


October 13, 2021
Hydrolix Puts Big Log Data In Its Place: The Cloud

(Cienpies Design/Shutterstock)
A startup named Hydrolix has arrived on the big data scene to give providers of log data storage and analytics solutions a run for their money. Its secret sauce: a distributed system designed to store, index, and query huge amounts of compressed read-only log data in the cloud.
Hydrolix is a cloud-based database designed specifically for append-only, high-cardinality data, such as the log data generated by applications. That puts it in direct competition with the likes of Splunk, Elastic, DataDog, and sundry other log data management systems going under the “observability” rubric these days.
The problem with existing cluster-based observability solutions, the company says, is that customers must take pains to store an ever-growing collection of data. That’s not difficult in the early days of collection, but as the months and years go by, customers are forced to bifurcate their storage environment into hot and cold repositories, simply to keep costs under control.
Hydrolix’s solution to this dilemma takes several forms. For starters, it runs only in the cloud and utilizes cloud object storage (currently AWS and S3, with support for other clouds coming soon). It also separates compute from storage, which enables customers to independently scale ingest and query. Users can choose between batch and real-time ingest using a combination of REST APIs, ETL tools, and Apache Kafka.
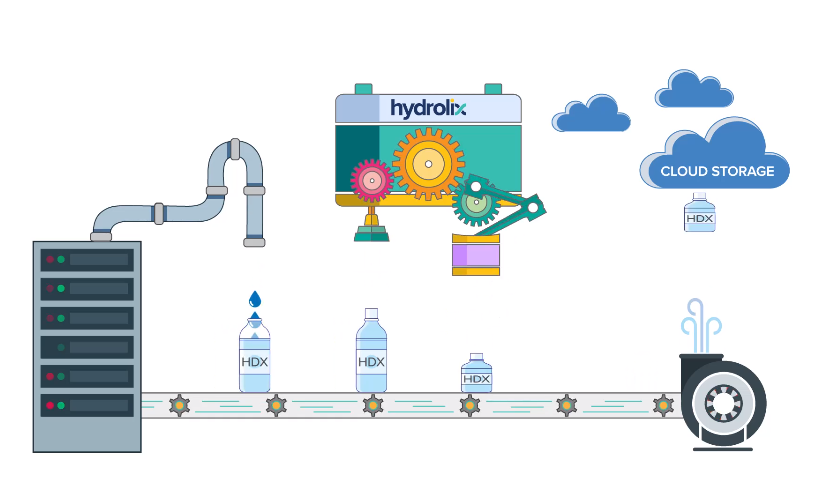
Hydrolix converts log data to a highly compressed HDX format, which is then placed in cloud object storage (Image courtesy Hydrolix)
Its secret sauce lies in its micro-indexing capabilities and predicate pushdown techniques, the core of its Turbine engine and its HDX file format. At query time, Hydrolix supports a version of ANSI SQL based on Yandex ClickHouse, which is already supported by common dashboarding tools like Grafana, Superset, and Looker (Grafana is bundled with the offering). Put all this together, and the company says it can deliver the speed and response necessary for to answer queries while helping to break the cost-versus-performance-versus-retention tradeoff that afflicts on-prem clusters and data lake solutions.
One of the Hydrolix believers is Peter Wagner, CEO of Wing Venture Capital, which invested in Hydrolix recently. Wagner was an early investor in Snowflake via Wing, and he is convinced we’re still in the early innings of the cloud data revolution, particularly around observability, currently one of the hottest segments of the market.
“Part of our point of view is that the most important cloud workloads and their associated unique data types will ultimately demand their own optimized data platforms,” Wagner tells Datanami via email. “Hydrolix is focused on supporting observability workloads and their append-only, immutable data types. These are increasing in terms of data volume and performance requirements as well as increasing in strategic importance to customers.”
By architecting specifically for these workloads and data types, in cloud-native fashion, Hydrolix “has been able to deliver radical gains in cost-effectiveness and performance, and eliminate the uncomfortable tradeoffs (such as constrained data retention, or hot / cold data tiering) that customers have had to resort to when using older, non-optimized, on-premise-oriented data platforms,” Wagner continues.
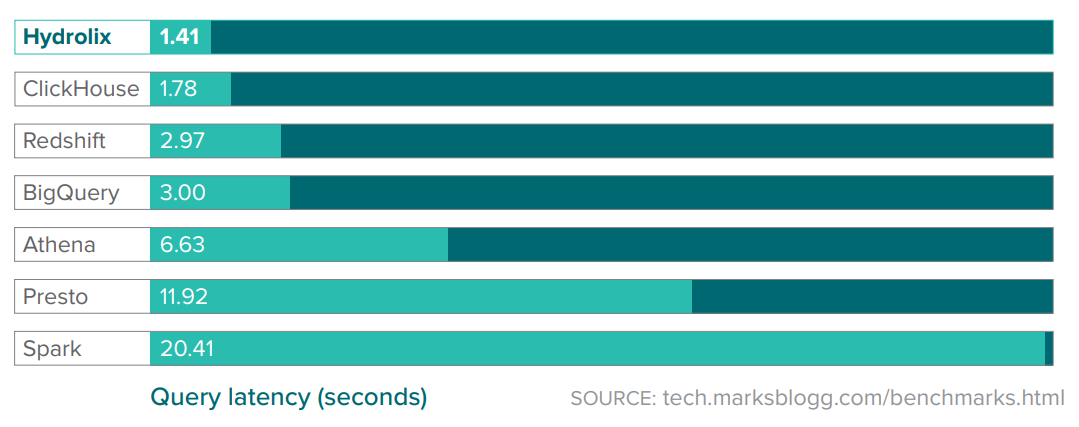
Hydrolix says a benchmark conducted by big data consultant Mark Litwintschik (tech.marksblogg.com/) showsthat its system achieves lower latency than other popular analytics sytsems (Source: Hydrolix)
One of the early adopters of Hydrolix is Arkose Labs, a cybersecurity company that targets fraudsters and the fraud they perpetrate. According to a recent case study, the Arkose Labs Security Operations Center (SOC) replaced a NoSQL-based log data management solution with Hydrolix, which is handling data ingestion exceeding 1TB per day.
While the previous NoSQL-based log data management system required separate storage tiers for cold, warm, and hot data, Hydrolix running atop AWS system eliminated that approach. The company, whose tagline is “bankrupting the business of fraud,” says the total cost of the Hydrolix solution, including a Supersets BI system, is lower than what it was previously paying.
The data challenges at Arkose Labs fit well with Hydrolix’s mission, Hydrolix CEO Marty Kagan said.
“They ingest billions of events a day, each containing hundreds of fields of sparse and complex, high-cardinality, semi-structured data,” Kagan stated in a press release. “They care about real-time ingestion, they care about long-term retention, and they care about the kind of sub-second, interactive query performance you can’t get from brute-force scans of un-indexed data.”![]()
Wagner, the Wing CEO, sees a big increase in the future in the generation of log data and associated workloads performed atop that data. While the space is increasingly crowded, Wagner is bullish on Hydrolix’s potential to rise above the pack.
“As observability workloads and the append-only data types they utilize grow in prominence and move to the cloud, the Hydrolix cloud data platform will become increasingly important,” Wagner says. “We believe Hydrolix has the chance to be a leader in the next generation of cloud data leaders.”
Hydrolix was founded in Portland, Oregon in 2018 by Kagan and Hasan Alayli, its CTO. The company raised $10 million in a seed round led by Wing with participation by AV8 Ventures, Oregon Venture Fund, and Silicon Valley Data capital.
Related Items:
Speedy Column-Store ClickHouse Spins Out from Yandex, Raises $50M
Who’s Winning In the $17B AIOps and Observability Market
OpenTelemetry Gains Momentum as Observability Standard
Applications:
Data Mining
Sectors:
Financial Services
Tags:
Clickhouse, cloud, compression, HDX, Hydrolix, indexing, log data, object store, observability
Leading Solution Providers

















