


September 13, 2021
LinkedIn Open Sources Tech Behind 10,000-Node Hadoop Cluster

(GreenBelka/Shutterstock)
LinkedIn last week open sourced DynoYARN, a key piece of technology that allows it to predict how appliacation performance will be impacted as it scales Hadoop to gargantuan proportions, including one 10,000-node cluster that may well be the biggest Hadoop implementation on the planet.
Hadoop may not be in the news much anymore, but it’s still chugging away behind the scenes at places like LinkedIn, which has bet heavily on the technology and continues to use it as the basis for its big data analytics and machine learning workloads.
LinkedIn essentially doubles the size of its Hadoop clusters every year to keep up with the exponential rate of data growth, according to a LinkedIn blog post last week by a quartet of company engineers, Keqiu Hu, Jonathan Hung, Haibo Chen, and Sriram Rao.
The company, which has been very active in the open source Hadoop community, long ago had to deal with the limitations in the Hadoop Distributed File System (HDFS), and in particular the NameNode. But it didn’t have a reason yet to do anything with YARN (Yet Another Resource Negotiator), which schedules the execution of jobs on the cluster.
But when LinkedIn recently decided to merge the compute nodes of two clusters, one that served mainline traffic, and another that was used for data obfuscation, cracks started to appear in YARN. Some jobs could face several hours of delay before they were scheduled, even though there was plenty of capacity on the cluster.
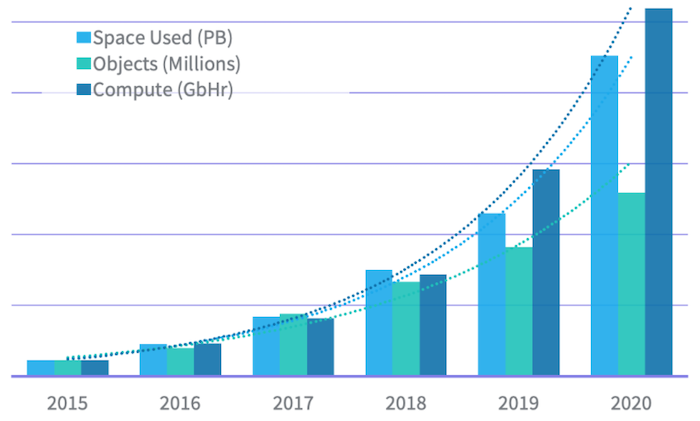
LinkedIn’s Hadoop clusters double in size every year (Source: LinkedIn)
“When looking for the cause of the delay, we initially thought that the logic to handle software partitioning in Hadoop YARN was buggy, but we did not find any issues in that piece of code after debugging and investigation,” the engineers wrote in the blog. “We also suspected that increasing the size of the cluster by 50% overloaded the resource manager, and that the scheduler was not able to keep up.”
As the engineers investigated, they found YARN could be susceptible to a “temporary deadlock” in allocating containers in certain conditions, such as when scheduler queues experience different workload characteristics (i.e. a higher container churn than the other).
“From an observer’s point of view,” the engineers wrote, “the scheduler appears to be stuck scheduling workloads in queue A, while workloads in queue B are starved of resource.”
Upon further analysis, they discovered that one of the merged clusters consisted mostly of AI experiments and data analyses implemented in longer-running Spark jobs, while the workload in the secondary partition’s queues were mostly “fast-churning MapReduce jobs.”
“If resource managers could schedule containers arbitrarily fast, this wouldn’t be an issue,” they theorized. “However, since the cluster merge reduced scheduling speed so significantly, an allocation fairness problem surfaced.”
Picking the queue randomly should address it, they said, and it did, temporarily. They even submitted the fix as a patch to the Apache Hadoop project. However, it didn’t address the root cause of inefficiency.
“We knew there was still an imminent scaling problem in our YARN cluster on the horizon. the engineers wrote. “We had to dig deeper!”
And dug, they did. They eventually rooted out an inefficiency in the scheduler related to its heartbeat monitoring and how that impacts which queue to schedule jobs in.
“To solve this challenge, we optimized the logic so that if a node from the primary (or secondary) partition heartbeats to the resource manager, the scheduler only considers applications submitted to the primary (or secondary) partition when scheduling,” they wrote. “After the change, we observed parity in total average throughput before and after the merge, and a 9x improvement in the worst case scenario when both partitions are churning busy!”
Determined not to face such a situation again, the company decided to devise a tool to keep it aware of impending scalability problem in its Hadoop cluster. Similar to Dynomometer, which it built to simulate HDFS NameNode performance, the company created DynoYARN to spin up simulated YARN clusters of arbitrary size and replay arbitrary workloads on the simulated clusters.
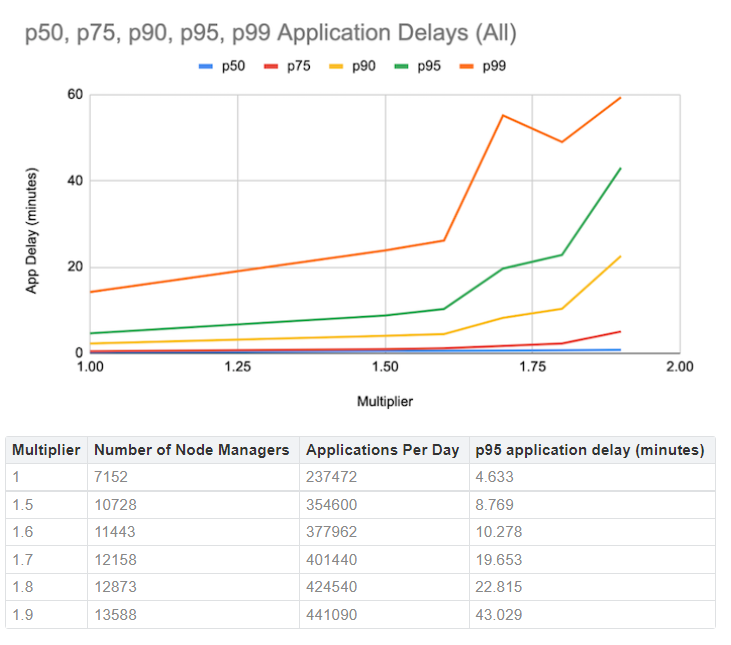
DynoYARN predicts LinkedIn’s largest Hadoop cluster will top out at 11,000 nodes (Image: LinkedIn)
DynoYARN allows LinkedIn to see how scaling its Hadoop cluster’s current workload will impact application delays. Engineers enter a multiplier, such as 1.5x or 2.x of current workload, and DynoYARN generates a predicted application delay, based on its actual workloads.
With its current setup, LinkedIn’s cluster can scale to around 11,000 nodes before the application delay exceeds 10 minutes, which is its goal. However, if the cluster with its current applications were to grow to 12,000 nodes, the predicted delay would be close to 20 minutes, breaking its SLA. DynoYARN can also be used for predicting the impact of new applications on cluster performance.
As it did with Dynomometer, LinkedIn is open sourcing DynoYARN. You can find it at this GitHub repo.
LinkedIn’s work hints at the existence of a cap in Hadoop scalability, thanks to YARN’s single-threaded architecture. But LinkedIn isn’t about to let that stand in its way! To address this cap, the Microsoft subsidiary is embarking upon a new project to build a cluster orchestrator.
Robin functions as “a load balancer to dynamically distribute YARN applications to multiple Hadoop clusters,” the company says. “At a high level, Robin provides a simple REST API that returns a YARN cluster for a given job. Before a job submission, YARN clients check with Robin to determine which cluster the job should be routed to, and then send the job to the correct cluster.”
LinkedIn has more to say about DynoYARN, Robin, and its migration of the Hadoop assets to Azure on its blog.
Related Items:
LinkedIn Open Sources Dagli to Simplify ML Pipeline Building
LinkedIn Open Sources Kube2Hadoop
Leading Solution Providers
















