


July 6, 2021
Tuplex Gives Python UDFs a Performance Boost
Python use is surging in data science, thanks to its versatility and its ease of use. But as an interpreted language, Python code can be quite slow, especially compared to hand coded C++. That’s what drove a group of university researchers from Brown University and MIT to create Tuplex, a new framework that speeds up the execution Python user defined functions (UDFs) by a factor 3 to 38x compared to Spark and Dask.
It’s hard to overstate the popularity of Python today. In just a few years, Python overtook R, Java, Scala, and every other language to become the most widely used language for data science workloads. As its gravity grows, the number of Python libraries and packages keeps growing, which just extends its lead.
Despite its popularity, Python is not particularly fast, particularly for big data workloads, says Leonhard Spiegelberg, a PhD student at Brown University, and the lead developer of Tuplex. “Using Python UDFs is incredibly inefficient,” Spiegelberg says in a video about Tuplex posted to YouTube.
There are several reasons why Python UDFs are slow, he says. The number one reason is that Python UDF code must run through a stack-based byte-code interpreter before being executed. Dynamic typing and dispatch, serialization overheads, garbage collection, and the interpreter lock all contribute to slow down the execution of Python UDFs, Spiegelberg says in his presentation.
Some computer scientists have attempted to get around this performance issue by building compilers. For example, PyPy, Pyston, Glow, Nuitka, Weld, and MLIR are Python compilers that have seen use in the field. “But when we use those compilers with our data science pipelines, we saw no benefit or only [minor] improvement,” Spiegelberg says.

Tuplex creates compiled code for Python UDFs (Source: Leonhard Spiegelberg, Brown University)
Tuplex represents a “radically different approach” to the performance problem. Instead of building a general-purpose system, Spiegelberg aimed to create a domain specific approach that can speed up specific types of Python UDFs.
Tuplex, which is a portmanteau of tuples and exceptions, is a just-in-time compiler that turns Python UDFs into native code. It works on Python UDFs that share a certain commonality. For everything else that doesn’t fit into Tuplex’s narrow use case, or that returns an error, Tuplex runs through the standard interpreter. After these two systems run in parallel, the results are merged for the final result.
“We explicitly make use of the properties of UDFs, which are embedded in a data science pipeline,” Spiegelberg says. “Since they are small, stateless, and called as part of a pipeline of a mostly known schema, we can match Pyton semantics with a much simpler execution model.”
User interact with Tuplex just like they interact with other Python compilers. After importing the Python UDF into Tuplex, the framework samples the data, and creates a context object based on that code. The user then writes a high-level LINQ-style operator and passes the UDF as parameters to those operators, Spiegelberg and his colleagues write in their research paper, “Tuplex: Data Science in Python at Native Code Speed,” which was published last month in the Proceedings of SIGMOD 2021.
“Our key technique to achieve this is to compile for the common space, which helps Tuplex avoid dynamic typing and dispatching compiled code,” Spiegelberg says. “By embedding the compiled UDFs within a…compiled query plan, Tuplex can avoid most of the serialization overhead. And for garbage collection, Tuplex simply uses a region-based memory management. Moreover, since UDFs are stateless, Tuplex no longer needs a global lock for parallelism, but still matches Python’s semantics.”
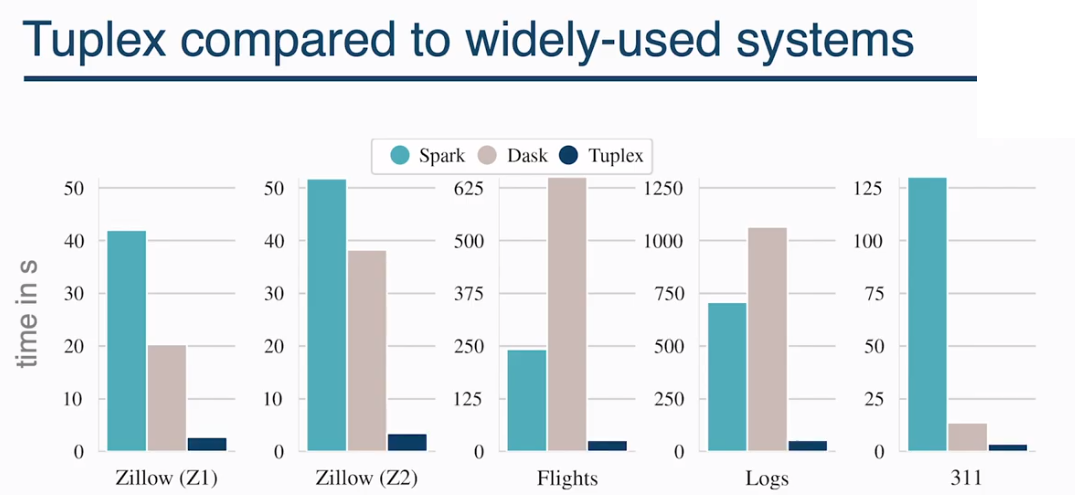
Tuplex executes Python UDFs up to 38x faster than Spark (Source: Leonhard Spiegelberg, Brown University)
Not all Python UDFs will be a good fit for Tuplex. The framework, which is written primarily in C++ and measures about 67,000 lines of code, demands a certain level of homogeneity in the code, what Spiegelberg calls “common space.” And the framework can still return errors, even if the common space is favorable for execution. That’s why the framework implements the dual-processing channels, which allows UDFs that aren’t a good fit to run through the standard interpreter. This is key to the “end to end” nature of Tuplex: even if there are errors, the process always run to completion.
Benchmark tests performed by Spiegelberg and his colleagues show that Tuplex can deliver a big performance increase. The researchers built five standard data science pipelines that include map, join, and filter operations, and ran them against standard Python UDFs using the Spark and Dask frameworks. The researchers took pains to use the latest, greatest techniques wherever they could, including using Spark SQL functions. They also created a hand-crafted C++ program for comparison’s sake.
Tuplex returned queries anywhere from 3 times faster to 38 times faster compared to the hand-tuned Spark and Dask programs, Spiegelberg says, while it was slightly slower than the C++ program, which was hand-coded.
“Thanks to end-to-end UDF and query compilation, Tuplex outperformed Dask and Spark in all scenarios,” he says. “Tuplex outperformed single-threaded Python baseline by one order of magnitude and comes within 25% of the C++ baseline.”
Another test compared the performance of the frameworks on larger data sets running in a distributed manner. A 64-core Tuplex setup was able to process the dataset in about 2.5 seconds, while the Spark setup took 87 seconds. “It’s pretty much done” before Spark finishes loading the data. What’s more, the Spark cluster required 40GB of memory, while the Tuplex cluster required only 412MB of memory.
Tuplex is available for Linux and MacOS. The software achieves parallelism as a mult-threaded application running on a single server, or as a serverless Lamba functions running in the cloud. The code is open source and can be downloaded at tuplex.cs.brown.edu/gettingstarted.html.
Leading Solution Providers
















