


May 12, 2021
Three Takeaways from Jay Kreps’ Kafka Summit Keynote

CEO & Co-founder, Confluent
We’re always interested in hearing what Apache Kafka co-creator Jay Kreps has to say, since he’s one of the smartest folks in distributed systems today. The Confluent CEO didn’t disappoint in delivering insight into the state of real time data and computer architectures at the Kafka Summit today.
Kreps could be forgiven for being distracted at Kafka Summit Europe, which was held online this week due to the coronavirus pandemic. After all, Confluent just filed (privately) to go public less than a month ago, promising what many industry-watchers expect to be one of the biggest tech IPOs since Snowflake’s blockbuster public offering a year ago.
Instead, Kreps appeared laser-focused on the intersection of business and technology, and spent most of his 30-minute keynote talking about how Kafka is evolving to better support the real-time data needs of modern businesses.
Here are three takeaways from Kreps’ talk:
1. Companies Are Becoming Software
Ten years ago, Netscape co-founder Marc Andreessen famously declared that software was eating the world. He was right, of course, and today Kreps added another layer to that axiom when said that “companies are becoming software.”
“What do I mean?” Kreps asked. “In some sense, software is going from the outside of organizations–email and expense tracking and whatever…apps you interact with–and it’s moving right to center of how businesses transact with their customers, how they carry out what they do. It’s becoming the central infrastructure that runs a business.”
We’ve grown accustomed the digitization on the front-end, thanks to the user experiences of Amazon and Netflix that we have come to expect in all digital interactions. But in Kreps’ view, software is taking over the back offices too, and that’s where it gets interesting.
“It’s how companies manage goods, how loans are approved, how streams of data are coming from the [world] and orchestrating the activity of companies,” he said. “It’s the rise of a set of applications which use data in a whole new way and extend the decision-making ability of software into new domains.”
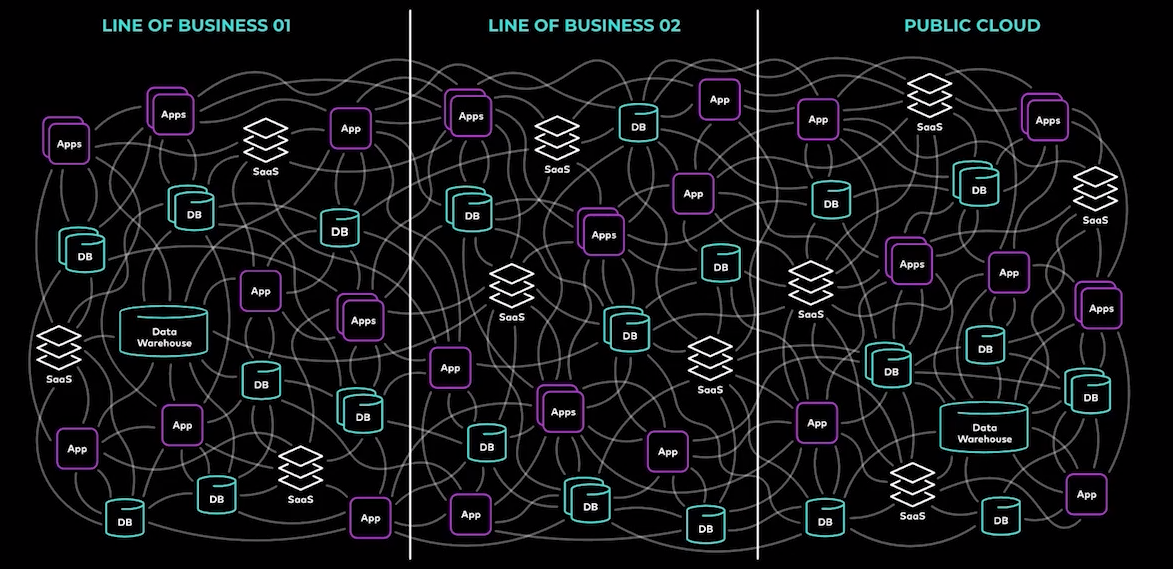
Spaghetti-based data and application integration typify legacy tech in enterprise deployments
Companies have been using software to automate their business processes for decades, starting with mainframes in the1960s, giving rise to the minicomputers of the 1970s, Unix in the 80s, client-server architectures in 90s, and finally today’s Web architectures in the 2000s and 2010s.
According to Kreps, we’re on the cusp of another major shift in the nature of business and technology. The difference is, companies increasingly want to be able to act upon real-world events, as represented by data, and do so in real time.
The problem is, the legacy integration methods, which Kreps likened to “a hairball of intertangled integrations” that’s held together with “bubblegum and duct tape,” are woefully inadequate to handle the new requirement.
“This is really no basis for moving to this much more dynamic, much more holistic, software-defined world,” he said. “This is a problem that every company faces and this is what has driven the rise of data in motion.”
2. The Complex Becomes Commodity
Kreps and his LinkedIn co-conspirators, Jun Rao and Neha Narkhede, originally developed Kafka to elevate the company’s capabilities when it comes to moving and acting upon very large amounts of real time data. The effort was a success, as evidenced by the fact that and Kafka has emerged as a de-facto standard message bus for the modern enterprise, as well as Confluent’s spin-out and pending IPO. But it wasn’t a total success.
The trio did succeed in developing multiple distributed systems, which took a significant amount of time and effort and attention to detail. But in some ways, the effort was a failure, according to Kreps, and therein lies a lesson for those who would dare to take on hellaciously complex engineering projects, particularly those involving distributed systems.
“When we were building Kafka and other system at LinkedIn, our job wasn’t just to build those [systems],” he said. “It was to operate them as a service and to offer them to other product teams who needed to use these capabilities. This was a shockingly hard thing to do.”
The LinkedIn engineers assumed that building the scalable systems would be the hard part, and that tackling such tough engineering projects would attract top-flight talent, which in turn would make their jobs of operating the things easier as time went on. They were wrong.

How Kreps views his own work on distributed systems versus how others see it
“We really struggled to be able to do this in a way that was so reliable you could just count on it, and wasn’t a bottleneck,” Kreps said. “The reality was, we never quite got there. Despite all the effort we put into it, we always were the bottleneck, the slowest point, of being able to scale and do that in reality, to be able to turn over control to the application teams that were using it. This was always the challenge.”
Kreps said there’s a disconnect between how the outside world views him and other folks who build the distributed systems, and the reality that goes on behind closed doors. That’s part and parcel of the problem.
“From the outside, it seems like a really fancy job to have,” Kreps said. “It seems actually quite cool. But when you get into it, there’s quite a lot of toil involved. And despite all the effort in automation that people tend to put in, people never quite get ahead of the curve.”
The “cool” factor drives its share of hype into and around distributed systems. We’re reminded of the market just before reaching peak Hadoop, when Hadoop was positioned as the solution to all of the world’s problems. While Kafka dabbled in Hadoop and even shared some of the core underlying technology (hello, Zookeeper), it managed to keep from going all-in on Hadoop. Nevertheless, it shares the same problem when it comes to meeting unattainable expectations.
“Managing Kafka at scale is hard,” Kreps said. “There’s no one technology that changes this. People think, oh I know, we’ll just put it in Kubernetes and that will make it elastic and scalable. I think it’s actually a lot more difficult than that.”
Kubernetes is part of the solution (we’ll get to that in a second). But the bigger point that Kreps was making is that companies should take advantage of the hard work that people have done before them. We learned that with Hadoop (which Kreps never mentioned by the way), and we’re learning that now with Kafka.
In other words, Kreps said, if at all possible if your shop, run Kafka in the cloud, as a service, and leave the hard part of managing it to someone (or something) else.
“Increasingly [companies] want to get out of the business of running data systems themselves and they want to put their best people on the things that differentiate their company,” he said. “This allows them to move faster. It allows them to really invest in the things that are consuming these data capabilities. And it allows them to get best-of-breed capabilities out of other systems.”
Modern cloud-native software builds on the shoulders of technology giants
This is something that wasn’t available to Kreps and company at LinkedIn, where the rule of thumb was that 70% to 75% of the engineers should be focused on core infrastructure. Technology has improved to the point where no companies should be dedicating three-quarters of their engineers to these types of problems.
“I think in those days, the problem that we were solving at that scale, that was exactly what we needed,” he said. “But if you think about what the current state of the world is, what the needs are now, having 75% of your engineering team working on something that only indirectly affects the customer, a means to an end in building new applications–it doesn’t really make sense.”
There’s always another layer in the stack in the software business, Kreps said. “When one layer becomes easy, whenever you can get it in a predefined product or service, another layer appears above it,” he said. Ditto with Kafka.
3. Kafka Gets Better
As mentioned, Confluent has been doing some work in supporting the latest technologies. That includes supporting Kubernetes as the orchestration layer, getting rid of Zookeeper dependences, and other changes.
Today Confluent announced that it’s now supporting the Confluent version of Kafka running atop Kubernetes in the private cloud. The company already supported Kubernetes in its hosted cloud version of the Confluent Platform, and now companies can run this setup in their private clouds.
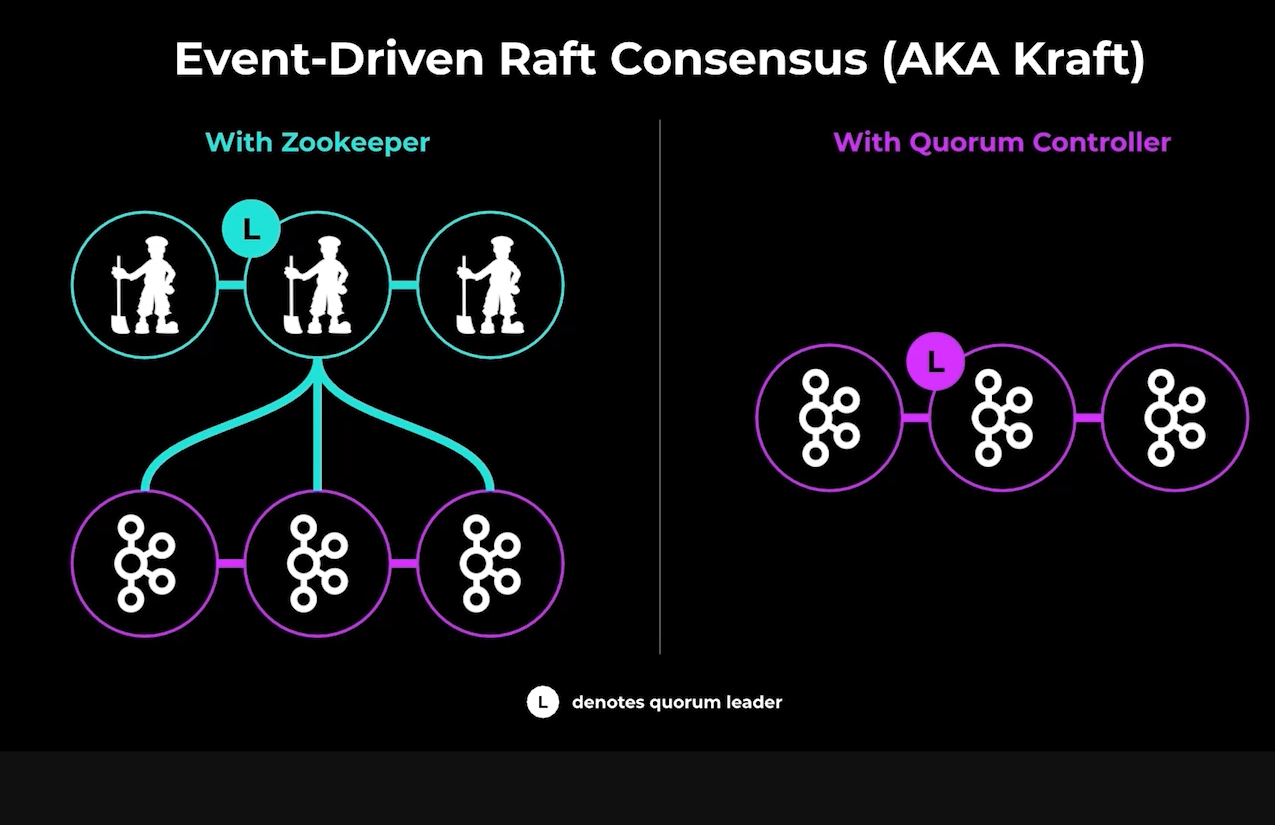
Say goodbye to Zookeeper in Kafka
“Obviously this isn’t a fully managed offering. It’s something you run yourself,” Kreps said. “But we gained the knowledge of how to build a system like this through the work we’ve done to run Kafka at scale for thousands of customer, as well as the work we’ve done with folks on premise, who are trying to run this type of offering of Kafka on their private cloud.”
The current release of Kafka, version 2.8, also eliminates the dependency on Apache Zookeeper, which has been a technological holdover from the old Hadoop days. The company replaced Zookeeper with a combination of the Raft consensus algorithm and the Kafka log itself, a solution it calls Kafka Raft, or Kraft.
According to Kreps, eliminating Zookeeper “dramatically simplifies the operation of the system.” “It takes us from a world where there [were] really two things down to one,” he said. “It takes all the duplication between Kafka and Zookeeper, both of which were keeping a log and the fact that they have two network layers, two security models, two monitoring systems, two ways of running and configuring each of them, and it gets to just one.”
Confluent is also working with early adopters on new software to improve the discoverability of data, as well as to improve governance and lineage tracking of data as it flows in Kafka, Kreps said.
The company is also working on a new cluster linking service that will improve the flow of data in a multi-site data fabric. “This allow topics to show up in clusters of your choosing,” Kreps said. “It replicates transparently. There’s no additional infrastructure that has to be managed. It’s purely API driven. And the offsets are exactly replicated in each place.”
Kreps said that “it’s like magic” to see your full ecosystem of data fully available wherever in the world you want it to be, in real time. “This is something that’s available in preview now for early customers.”
Related Items:
Confluent Files to Go Public. Who Could Be Next?
Confluent Moves to Boost Kafka Reliability
How Machine Learning Is Eating the Software World
Applications:
Enterprise Analytics
Vendors:
Confluent
Leading Solution Providers
















