


March 25, 2021
A Nutrition Label for AI
It can be difficult to understand exactly what’s going on inside of a deep learning model, which is a real problem for companies concerned about bias, ethics, and explainability. Now IBM is developing something called AI FactSheets, which it describes as a nutrition label for deep learning that explains how models work and that can also detect bias.
AI FactSheets is a new addition to Watson Open Scale that will provide a plain-language description of what’s going on inside deep learning models. The software, which is expected to be generally available soon, can work with AI models developed by Watson Studio, or any other AI model accessible from a REST API.
After being exposed to the model, AI FactSheets generates a PDF with information about bias, trust, and transparency aspects of a given deep learning model. It also captures data lineage and provenance of data so that users can know whether data is being governed correctly, according to IBM’s Chief AI Officer Seth Dobrin.
“It’s really aimed at building trust in the models, both for the end users and consumers who are affected or impacted by the model,” he tells Datanami.
IBM customers are concerned about bias and trust issues with AI, Dobrin says. The COVID-19 pandemic accelerated the adoption of AI, but companies are afraid they may be making unethical business decisions or perpetuating human biases if they roll out AI models that they can’t fully explain the workings of.
“Absolutely, our customers are very interested in trust trustworthy AI and being able to assess their AI as they’re continuing to move forward from implementing all of these tools,” Dobrin says. “In the past it’s been handled through manual labor, and what this provides is an automated way to do it at scale.”

dee
AI FactSheets can be used anywhere that deep learning is used. That could include regulated industries, like financial services and healthcare, as well as unregulated industries, like retail and manufacturing. A bank, for example, could use it to interrogate a deep learning model used for deciding whether applicants are approved for a mortgage or denied the loan. That can give the bank the confidence to use deep learning.
“So if a regulator shows up and wants to know ahead of time why a model…is making a decision about certain individuals, how do you know that it’s not biased towards one group or the other?” Dobrin says. “How have you removed the effects of previous decisions of humans, like redlining? FactSheets will, in a consumable manner, help to explain that in terms that a regulator could understand or a business user” can understand.
Bias and ethics have emerged as hot topics in the AI community, particularly since last summer’s political unrest and the national conversation around pervasive racism. Even before COVID-19, a Deloitte survey showed that a large number of high-performing companies were so concerned about AI bias that they were slowing down their AI rollouts. In light of the rapid expansion of AI due to the pandemic in the last year, these concerns are coming to a head.
IBM’s software goes beyond what explainability frameworks like Lime can do to provide a more detailed explanation of how deep learning models come to decisions, Dobrin says. Lime provides a linear approximation of each layer in a deep learning network, which provides the explainability.
“The problem with linear approximation is it only gets you so far,” Dobrin says. “You get models that are so deep and have so many hidden layers that every layer you go down, you lose a little bit of confidence and eventually you have hardly any confidence. So these new algorithms that we’ve built in IBM Research do the same kind of thing, but with much more confidence as you go deeper into the into the deep learning model.”

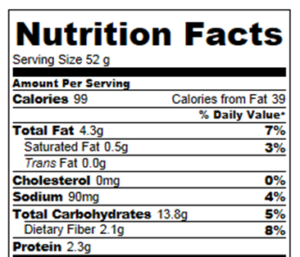
An example of an AI FactSheet for the machine learning model in a mortgage approval application
The PDFs generated by AI FactSheets (you can see an example of them here) are designed to be readable by knowledgeable staff members, such as a data scientist, a regulator, or an experienced data analyst. It’s a little beyond what a regular business user can understand, according to Dobrin.
If there is unacceptable bias, the tool can help users pinpoint exactly which part of the model is generating that bias, and also provide suggestions on how to fix it, he says. “It actually identifies which features are driving the bias and it provides some recommendations for remediating, adjusting the weight of that feature to minimize the impact on the model,” Dobrin says.
Because it can detect bias, AI FactSheets will help companies implement deep learning models in a more responsible manner. According to Dobrin, companies have been putting deep learning models into production without fully understanding how they’re working. That’s not legal in regulated industries–they must be able to provide an explanation for how the model came to its conclusion–which is why companies in healthcare and financial services may be among the biggest users of AI FactSheets, since it can automate that manual effort.
Deep learning technology is all the rage in AI. But Dobrin is not exactly a big fan.
“I spend a lot of time, when I talk to customers, talking them out of using deep learning models if it’s not appropriate,” he says. “I’m a very a big fan of Occam’s Razor. You want to keep it simple, right? The simpler solution, the better.”
Neural networks have emerged as the best approach for certain classes of data problems. Language problems like natural language processing (NLP) and computer vision are at the top of the list, and the technology is also finding traction in some use cases that have lots of time-series data and where a 1% or 2% performance boost can be material, such as high frequency trading and fraud detection.
Beyond that, the high costs of deep learning–including a need for powerful GPUs for training (and inference, in some cases) as well as a very large amount of labeled data–begin to outweigh the very small percentage boost that can be had.
“Yes, it’s cool and shiny, but if you can get the job done with a much simpler approach that’s easier to maintain, easier to explain, and probably will cost you a lot less in the long run,” then that’s probably the best approach, Dobrin says. “Sometimes if you look at a deep learning model compared to Gradient Boost, you may get 1% or 2% [advantage], but is it really worth the extra overhead for that?”
Related Items:
Looking For An AI Ethicist? Good Luck
Governance, Privacy, and Ethics at the Forefront of Data in 2021
It’s Time to Implement Fair and Ethical AI
Leading Solution Providers
















