


March 24, 2021
The ‘Rage Design’ Behind Flatfile’s Onboarding Success

(solarseven/Shutterstock)
David Boskovic was excited to join a company called Envoy back in 2016. He had worked with B2B startups since he was 18, and was looking forward to helping another tech startup scale an idea. But that excitement turned to dread when Boskovic realized his first job was to build yet another data onboarding system.
“Eric [Crane] was leading product I was leading engineering, and for the umpteenth time in our careers, we had to build this CSV data onboarding solution for yet another SaaS company,” Boskovic said.
Envoy needed a painless way for new customers to move their existing data into its new SaaS offering so that it can do interesting things with it. So Boskovic and Crane (his future Flatfile co-founder) got to work.
At first glance, it seems like a simple problem: Data set A needs to move to database B. The data set is usually in one place already, and the data format is not an issue, since it usually takes the form of comma separated value (CSV) file, with the occasional XML, Excel, or SQL file thrown in for good measure.
But as Boskovic and Crane started scoping out the product, they realized that it was going to take three long months to build the data onboarding system. That triggered something inside Boskovic.
“I like to say I rage designed the first version of Flatfile, because I was like, ‘This needs to exist! This is the last time I’m going to build it!’” Boskovic told Datanami in a recent interview.
Even after building the data onboarding system for Envoy, Boskovic and Crane didn’t realize it could stand on its own. But after fiddling around with it on nights and weekends for six months, Boskovic decided to put it out on the Internet to see if it there was any interested in a stand-alone data onboarding system.

Flatfile CEO David Boskovic has designed his last data onboarding system
There was.
“We put it up for $1,000 per month and said ‘Let’s see if people bite,’ essentially,” Boskovic said. “And sure enough, early-stage startups [and banks showed interest]. Everybody was like, ‘Hey, we need this feature. We need this thing.’”
At that point, it dawned on Boskovic and Crane that this was something much more than a side project. And so, after founding Flatfile in 2018, the Denver, Colorado company raised its first $2 million in seed funding in 2019, and it was off to the races.
Today, Flatfile boasts more than 300 customers, including many startups but some very large enterprises too, including at least one Fortune 500 firm. The company is helping to onboard hundreds of thousands of files per month on behalf of its customers, touching billions of individual records.
“Once you have the data in the right shape, there’s a lot of innovation that’s happening,” Boskovic said. “But when data is in the wrong shape, very few systems can do anything with it and very few products can reason about that data. Our unique ability in the market is to predictably get data into the right shape very quickly.”
The company reached a milestone two weeks ago when it announced a $35 million Series A investment by Workday Ventures, Afore Capital, Gradient Ventures, Two Sigma Ventures, and HNVR.
ETL for the Masses
Data on-boarding in essence, is a extract, transform, and load (ETL) problem, and an ETL tool could definitely be used to solve this problem. But because the end-users of Flatfile clients are not technical, they cannot use a complicated ETL tool to upload their data into the new SaaS offering they’re using, according to Boskovic.
“The problem is the stakeholders involved in this transaction are non-technical,” he said. “And because that audience is non-technical, you have to build an ETL product for a non-technical person, which is a very interesting challenge.”
So Flatfile’s first product is basically an ETL tool that’s designed to be used by a non-technical person. It leans heavily on pre-built mappings to streamline the data transformations (really just data movement), and employs a bit of machine learning to take the automation further when the basic mapping is insufficient.
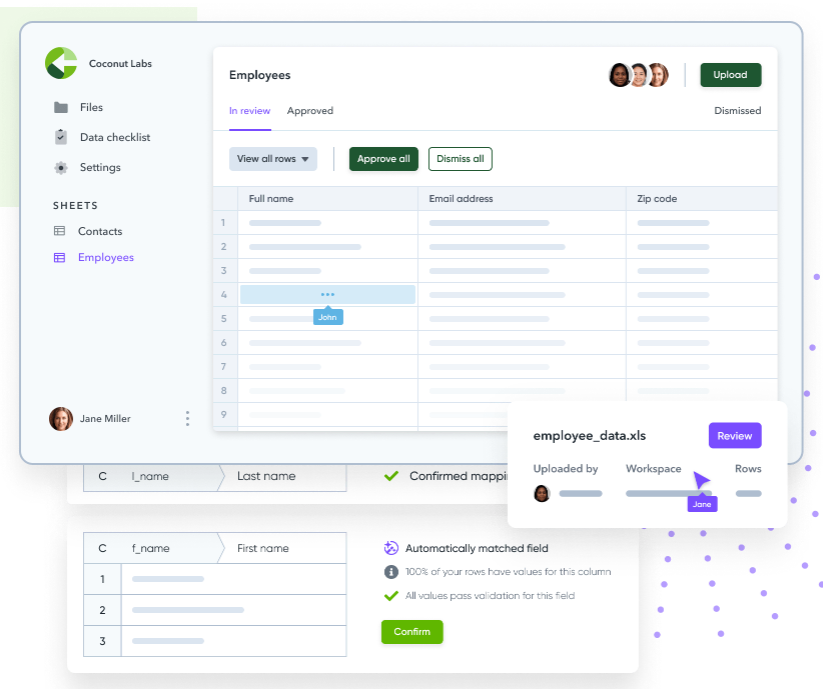
Flatfile supports some data transformation and quality tasks through its GUI
A lot of bulk data movements can be automated through basic rules. If all of the data values in a given column are straightforward and accurate, then they can just say “move this data to column A.”
The goal of Flatfile’s first product was to allow end users to map their data easily, Boskovic said.
“Upload what you have and say, column A goes to column B manually,” he said. “No machine learning automation involved. Just make it really easy for them to do that. And then give them a spreadsheet view when the data doesn’t map correctly or the data isn’t the right format and highlight the issues.”
But many times, the data does not map very easily, because it’s complex, incomplete, and messy. Multiple addresses might be buried in an 85-field CSV file, and extracting the original data formatting–the original data meaning, often created in a relational database or a NoSQL database–is not always easy.
“Flat files are a representation of data and oftentimes they actually are a representation of very complex structures. Like you’ll try to serialize a relational database into a flat file, and get halfway there,” Boskovic said. “Flatfile’s job is to actually detect those relationships out of data and oftentimes, we have to reverse engineer with very little information by watching user behavior. So I think we’re actually building this ability to understand very complex data sets very well out of flat files.”
AI for Data Transformation
In addition to basic text files formatted as a CSV, Flatfile is able to handle more complex documents, including PDFs. The company’s second product, called Concierge, is designed to be used by groups of individuals who are working to bring together dozens of disparate data sets.
“With Concierge, you can upload basically any file type,” Boskovic said. “We do build a relational database behind the scenes, but also allow for essentially an ephemeral view of the data in whatever database you want. So if you want to spin up a BigQuery instance so you can get in there and mess around with it, we’ll [help you] pick the data and load it back into the system.”
In the long run, Boskovic hopes that Flatfile will become a place where customers can just throw their messy data in, and have it come out transformed on the other side. The company is not there yet, but it’s working at it.![]()
“We’re rolling out what we call the one-click import for customers,” Boskovic said. “We’re starting to get to the place where we can actually just give them a check box. ‘You just dropped a random file in here, we’ve mapped it correctly, we have high confidence in it, and your data is now in the product.’”
Having a human in the loop has proved critical for data onboarding success, particularly for dealing with edge cases. But as the volume of data increases into the many billions of records, those edge cases become increasingly common. That’s where Flatfile’s use of machine learning really comes into play.
The goal, Boskovic said, is to lean on machine learning to get the data onboarding process–the ETL job, that is–to be so good and so accurate and so seamless that the need for humans in the loop goes down dramatically.
“That’s the exciting next step for the product, how many times can we avoid the user interacting with the product at all,” he said. “We like to say our vision for the product is to remove the product.”
And, of course, to never have to write another data onboarding system again.
Related Items:
Matillion Rides Cloud ETL to $100 Million Round
Fivetran Launches Pay-As-You-Go Option for ETL
Leading Solution Providers
















