


October 22, 2020
Openness a Big Advantage as Edge Grows, IBM Says

(metamorworks/Shutterstock)
A large computational build-up is predicted to occur on the edge in the coming years, as organizations look to capture and act upon data as soon after it’s generated as possible, when it has the highest value. Today, there are few standards and protocols defined for how all this is going to work. But in the meantime, hardware and software providers, including IBM, are espousing the benefits of an open ecosystem approach.
The edge, which includes server rooms, cell towers, and smaller data centers deployed in the field, is set to proliferate over the next five years, according to the IDC. By 2025, 50% of new on-premise infrastructure will be deployed in edge locations, up from 10% today, the company says.
The edge will be where lots of machine learning-based decisioning occurs on real-time data generated from end points (such as PCs, smart phones, industrial sensors, connected cars, and wearables). It will need to occur on the edge due to the large network latencies involved with sending data all the way from the end points to the core (defined as public clouds, private clouds, and large data center), and back to the end point to have the impact.
According to a McKinsey study, data has 2.5 times as much value on the edge compared to when its stored in the cloud. The challenge for system makers, integrators, and enterprises, then, is how to architect these edge environments in a way that makes them adaptable and flexible to changing needs, despite the wide variety in different hardware and software expected to be involved.
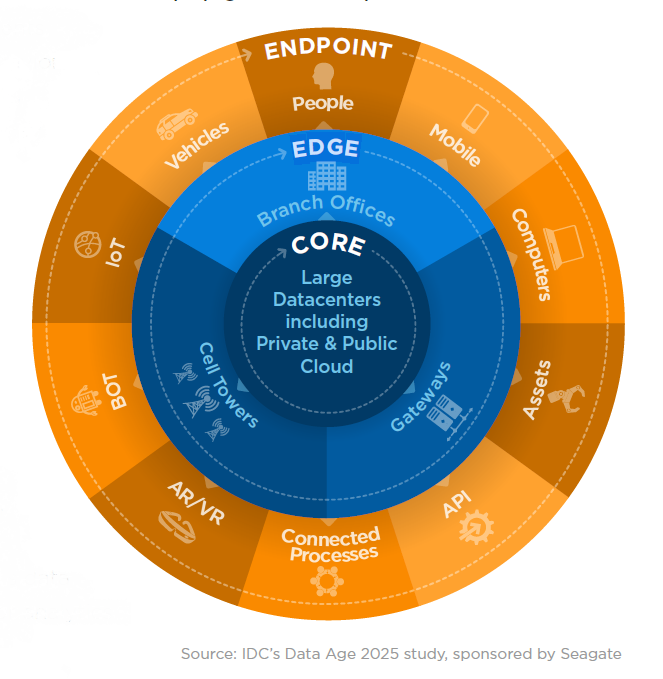
Source: IDC Data Age 2025
According to Evaristus Mainsah, who is the GM of IBM’s Edge Ecosystem, the solution to the edge dilemma is to strive to build as open an ecosystem as possible.
“You have…a great variety of different equipment that has to combine to make sense of the work environment, like an Industry 4.0 environment,” Mainsah says. “And therefore, if you’re ….not really thinking about doing this as an ecosystem, its’s very difficult to craft together solutions that deliver value quickly to customers.”
Instead of having Big Blue build entire edge stacks with its own set of toys, it’s looking to build an open playground where lots of different hardware and software vendors can bring their own toys, to the benefit of the customer.
“What we decided the best thing to do was to try to bring together a group of ecosystem partners that are likeminded, that understand the complexity of working with an edge,” Mainsah tells Datanami. “Some of these are infrastructure partners that accept that, in order to craft and create solutions that work and deliver value quickly, you really need to have an open mindset. You need to believe in the idea of open.”
It’s a simple proposition, really: Building open architectures makes it easier to integrate your stuff with other people’s stuff. Not everybody has the same camera, Mainsah says. But by agreeing to openness in the beginning, it increase the odds that a new camera from a new manufacturer will find its spot on the edge.
That doesn’t mean there will be “plug and play” simplicity on the edge, according to Mainsah. Not everything can be easily hooked into the emerging reference architecture. But the number of “empty calories” spent on expensive systems integrators will be dramatically less with the open ecosystem approach, he says.

The edge is predicted to grow in importance in the coming years (metamorworks/Shutterstock)
IBM, of course, has a horse in this race. It wants to sell IBM Edge Application Manager, which is a management system designed to radically simplify the rollout and maintenance of applications to thousands or millions of devices on the edge (or the endpoint, for that matter). Like most of IBM’s new offerings, Edge Application Manager runs on Red Hat Open Shift, its Kubernetes-based runtime.
On top of the Edge Application Manger, companies will be encouraged to deploy the IBM Cloud Pak for Data, which brings a slew of advanced analytics and AI capabilities. Customers will be able to build machine learning models–such as a computer vision program for measuring the density of a crowd, or for detecting the presence of face masks— with Cloud Pak for Data, and then deploy it with Edge Application Manager.
But this isn’t an IBM-only affair, of course, and IBM is hoping to enable a fleet of third-party software developers to also play nicely on the edge. It has commitments from Cisco, Dell Technologies, Intel, Samsung, Arrow, and ADLINK to participate in IBM’s edge ecosystem. Another one is Hazelcast, the developer of an in-memory data grid.

Evaristus Mainsah, PhD., is the general manager of Cloud, Cloud Pak, and Edge Ecosystem at IBM
Earlier this month, IBM and Hazelcast announced they’re working together to ensure that Hazelcast’s IMDG, which supports Kubernetes, is compatible with IBM’s Cloud Pak for Data and Edge Application Manager offerings. This means that customers building edge solutions with IBM software can also utilize Hazelcast’s IMDG to provide fast processing of real-time data with very low latencies, with a minimum of integration effort.
Kubernetes and Docker containers have emerged as de facto standards for deploying the IT stacks that business applications are built on. But there’s a lot of work yet to do to create new standards that unlock efficiencies as the Industry 4.0 and IoT build-out on the edge continues in the years to come.
IBM wants to be a part of those standards discussions, Mainsah says. In the meantime, it’s making an effort to foster an open ecosystem where multiple parties can come together, such that those standards might begin to take shape.
“If everybody is going to focus on creating their own system that is proprietary, then I think the whole of this can implode on itself,” he says. “But if you have an ecosystem approach, where you’re looking to makes it easier for other developer, other independent software vendors, other device manures, to use the same sort of standards….then I think the sky is the limit.”
Related Items:
Lightweight Kubernetes Pushes Orchestrator to the Edge
Towards The Edge: How Innovative New Technologies Are Redefining Data Delivery
Exploring Artificial Intelligence at the Edge
Applications:
Artificial Intelligence
Leading Solution Providers
















