


June 25, 2020
Spark 3.0 Brings Big SQL Speed-Up, Better Python Hooks

Apache Spark 3.0 is now here, and it’s bringing a host of enhancements across its diverse range of capabilities. The headliner is an big bump in performance for the SQL engine and better coverage of ANSI specs, while enhancements to the Python API will bring joy to data scientists everywhere.
In 10 short years, Spark has become the dominant data processing framework for parallel big data analytics. It started out as a replacement for MapReduce, but it’s still going strong even as excitement for Hadoop has faded. Today, it’s the Swiss Army knife of processing, providing capabilities spanning ETL and data engineering, machine learning, stream processing, and advanced SQL analytics.
Spark has evolved considerably since the early days. Few new applications today use the Resilient Distributed Dataset (RDD), which have largely been replaced by DataFrames. In concert with the shift to DataFrames, most applications today are using the Spark SQL engine, including many data science applications developed in Python and Scala languages.
The Spark SQL engine gains many new features with Spark 3.0 that, cumulatively, result in a 2x performance advantage on the TPC-DS benchmark compared to Spark 2.4. There are several reasons for this boost, including the new Adaptive Query Execution (AQE) framework that simplifies tuning by generating a better execution plan at runtime.

Image courtesy Databricks
A blog post on the Databricks website explains the three main adaptive mechanisms in AQE. One of them is dynamically coalescing shuffle partitions, which “simplifies or even avoids tuning the number of shuffle partitions,” the Databricks authors write. Another technique, dynamically switching join strategies, can “partially avoid executing suboptimal plans due to missing statistics and/or size misestimation,” the company says. Finally, dynamically optimizing skew joins can help avoid extreme imbalances of work.
No SQL engine supports the breadth of the ANSI standard out of the box, and Spark SQL’s ANSI journey has been a work in progress. With Spark 3.0, the engine gains closer adherence to the standard.
The Databricks authors write: “To improve compliance, this release switches to Proleptic Gregorian calendar and also enables users to forbid using the reserved keywords of ANSI SQL as identifiers.” The developers have also introduced runtime overflow checking in numeric operations and compile-time type enforcement when inserting data into a table with a predefined schema, which help improve data quality.
The addition of join hints further enhances the accuracy of the compiler when the built-in algorithms deliver a suboptimal plan. “When the compiler is unable to make the best choice, users can use join hints to influence the optimizer to choose a better plan.”
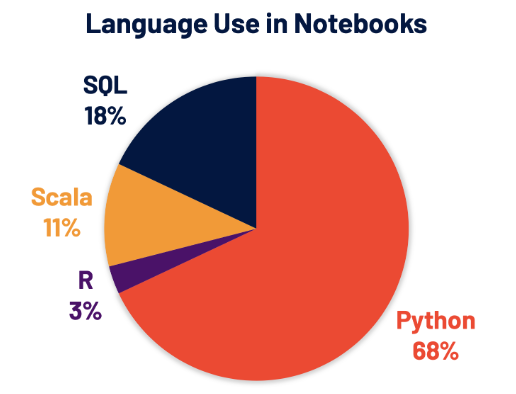
Image courtesy Databricks
Together, these Spark 3.0 enhancements deliver an overall 2x boost to Spark SQL’s performance relative to Spark 2.4. But according to Databricks, on 60 out of 102 queries, the speedups ranged from 2x to 18x.
“There was a ton of work in ANSI SQL compatibility, so you can move a lot of existing workloads into it,” said Matei Zaharia, the creator of Spark and chief technologist at Databricks. “You dont have to re-write them in any way to run on this.”
Python is the most popular language for data science, so it should be no surprise that Python has become the dominant language for developing in Spark too. According to Databricks, 68% of the commands written in its Workspace are written in Python, and the PySpark API is downloaded 5 million times per month.
“Some of the biggest things going on are around SQL and Python,” Zaharia says. “We’re going to announce an initiative at the keynote at the [Spark + AI] Summit, where we’re going to spend a lot of our engineering time going forward for Python on Spark, so making that much easier to use.”
The Pandas package is also popular in Spark environments, but it only runs on a single node. The Koalas implementation of Pandas addresses that limitation in PySpark, and has been a focus for Databricks. “After more than a year of development, the Koalas API coverage for pandas is close to 80%,” the Databricks authors write.
With Spark 3.0, the developers have added several new capabilities, including “a new Pandas UDF interface that leverages Python type hints to address the proliferation of pandas UDF types” the Databricks authors write. The new interface is also “more Pythonic and self-descriptive,” they write. It also brings better error handling of PySpark errors.
The Spark team has finished key components of Project Hydrogen, a long-running project to bring deep learning capabilities to Spark through support for GPU. With Spark 3.0, the framework now recognizes GPUs, which will deliver a big performance boost for AI in Spark.
“Spark now has a first class concept of what accelerator devices on the machine and how to schedule computation around them, so you can submit a job that says, I need GPUs, and it will launch it on the machines that have GPUs and it will assign the right number of GPUs on each task,” Zaharia says.
The Apache Spark team has also added a new user interface for Spark Streaming; delivered up to 40x speedups for calling R UDFs; and resolved over 3,400 Jira tickets. For more information on Apache Spark 3.0, see the Databricks blog post.
Related Items:
Databricks Brings Data Science, Engineering Together with New Workspace
Databricks Cranks Delta Lake Performance, Nabs Redash for SQL Viz
Databricks Snags $400M, Now Valued at $6.2B
Applications:
Artificial Intelligence, Complex Event Processing, Enterprise Analytics, Predictive Analytics
Technologies:
Frameworks
Vendors:
Databricks
Tags:
analytics, apache spark, big data, GPU, machine learning, Matei Zaharia, PySpark, python, Spark SQL, sql, TPC-DS
Leading Solution Providers
















