


June 25, 2020
Databricks Brings Data Science, Engineering Together with New Workspace

(ra2 studio/Shutterstock)
Data scientists and software engineers work in different ways and use different tools. But both personas will feel more comfortable developing applications in the new version of Databricks Data Science Workspace, which the company unveiled today at Spark + AI Summit.
Databricks first launched Workspaces in 2014 as a cloud-hosted, collaborative environment for development data science applications. Since then, Jupyter has become a lot more popular, says Matei Zaharia, the creator of Apache Spark and Databricks’ Chief Technologist.
“But we’ve also learned a lot about what works well and what doesn’t work well in using notebooks in general and developing data science applications with them,” Zaharia tells Datanami. “So we’re trying to take the lessons from that and make it easier to manage projects as a team.”
Existing development environments make data teams choose from three bad options, Databricks says.
Running any old open source environment on a laptop opens up governance and compliance risks, the company says. Hosting those same environments in the cloud may solve some of the data privacy and security issues, but it doesn’t provide a clear path to production, nor does it improve productivity and collaboration, Databricks says. Or teams can choose to use the “the most robust and scalable DevOps production environments,” but they can hinder innovation and experimentation by slowing data scientists down.
With today’s launch of what Databricks internally is calling Workspaces 2.0, the company thinks it has come up with a new data science development environment that addresses those concerns.
Databricks Data Science Workspace provides a collaborative environment for data scientists and software engineers
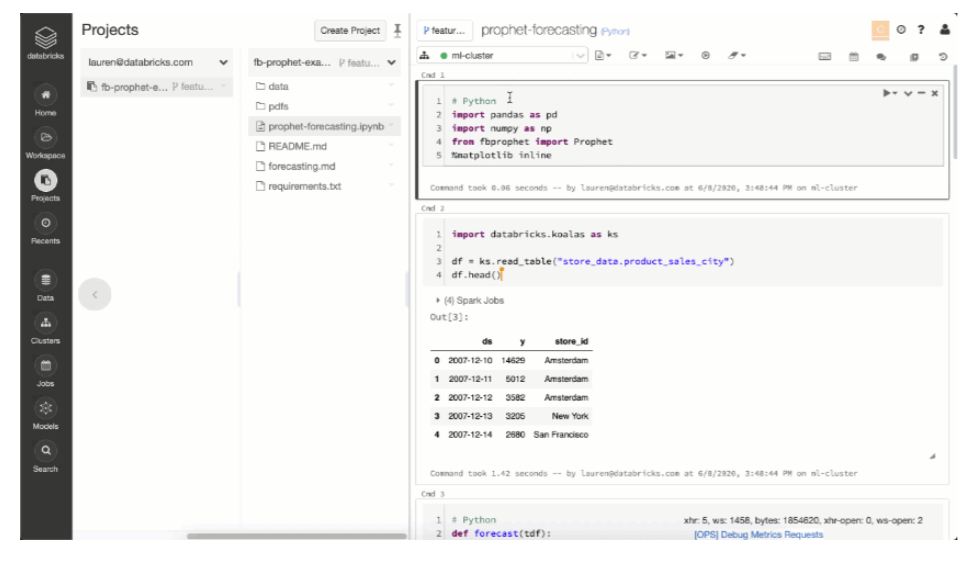
For starters, everything in Workspaces is now stored by default in the Juypter notebook format. So if a user tries to access an application developed in Workspaces outside of the Databricks environment, it works just like a standard Juypter notebook.
But there are bigger changes, Zaharia says.
“The biggest, most visible thing is instead of just working with notebooks individually, you can work with a notebook, or multiple notebooks and a set of files as well and create these projects that include your code, its dependencies, and also maybe libraries or data files and so on,” the Databricks co-founder continues.
Workspaces 2.0 also integrates with Git, and enables teams to store their files within Git, which can help with the iteration cycle. But Workspaces goes beyond that to basically enable diverse teams of data scientists and data engineers to collaborate in real time within Workspaces 2.0. It’s like Google Docs for data science projects, Zaharia says.
“The first release [of Workspaces] only had notebooks, so it didn’t have this concept of a project that also has source files, and additional libraries and data files and so on,” he continues “So this one having the files in there allows you to have more complicated projects and to do more software engineering, basically, to factor some code out into a library and share it with people, or have someone on your team who work with an IDE and is more of a software engineer and someone is more of a data scientist who calls those functions and does something interactively.”
Workspaces 2.0 allows these diverse groups, including data scientists and software engineer, to work collaboratively in the same environment. That’s a big advantage in today’s fast-based data environment, Zaharia says.

Matei Zaharia is the creator of Apache Spark
“With these projects, you often [are] working in some domain,” he says. “You write some utility function. You bring in some libraries. Maybe you bring in data sets that you want to use in your code and then people worry if I only have notebooks, how do I manage lots of code? How do I do software engineering? So this allows both of those personas to work nicely together on the same project.”
Workspaces also streamlines the process of deploying these collaborative data science software projects into working applications – running in the Databricks environment, of course. And because Workspaces automatically tracks all the different versions, it brings more of a standard, CI/CD-based software engineering approach to notebook-based data science development, Zaharia says.
“This was one of the pain points that a lot of users had with notebook-based solution, including early on with our notebook and our product,” he says. “How could I actually test these things before pushing them to production, and hold them back if there are changes? So with this concept of a project, you can check out different versions of the project from Git, because it’s all backed by Git in different locations and different Databricks Workspaces. And you can also use an API to check out one of the versions and run various tests on it.”
It’s all about getting data teams to work smarter and get more work done in a fast-moving environment.
“We make it easy to take your projects and turn them into a production application,” Zaharia says. “That’s what we’re trying to do: Make it easy to build these applications and having them run for ever. And then as a data scientist, you can move on to the next thing and answer more questions.”
Spark + AI Summit is currently underway as a virtual event, with around 60,000 registered users. For more info on Workspace, see this blog post.
Related Items:
Databricks Cranks Delta Lake Performance, Nabs Redash for SQL Viz
Will Databricks Build the First Enterprise AI Platform?
Databricks Snags $400M, Now Valued at $6.2B
Vendors:
Databricks
Leading Solution Providers
















