


March 3, 2020
Kubernetes Gets an Automated ML Workflow
A stable version of an automation tool released this week aims to make life easier machine learning developers training and scaling models, then deploying ML workloads atop Kubernetes clusters.
Roughly two years after its open source release, Kubeflow 1.0 leverages the de facto standard cluster orchestrator to aid data scientists and ML developers in tapping cloud resources to run those workloads in production. Among the stable workflow applications released on Monday (March 2) are a central dashboard, Jupyter notebook controller and web application along with TensorFlow and PyTorch operators for distributed training.
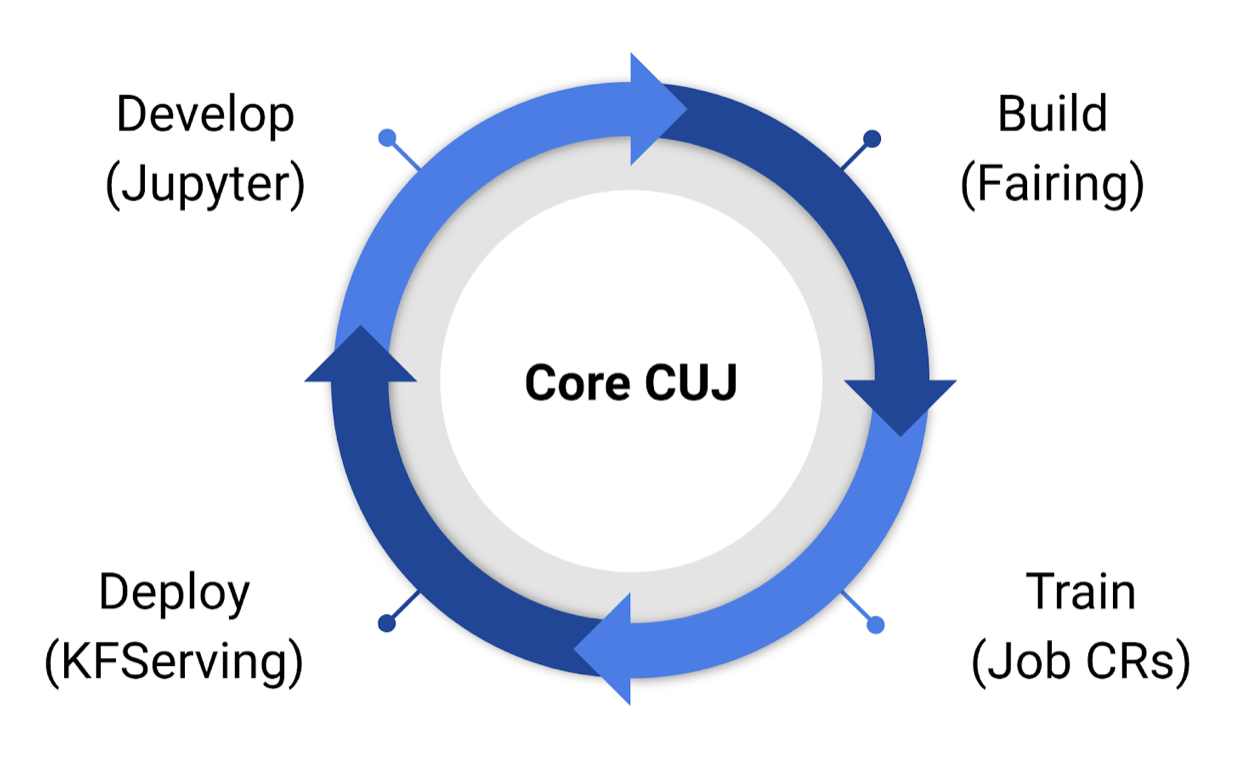
Contributors from Google, IBM, Cisco Systems, Microsoft and data management specialist Arrikto said Jupyter notebooks can be used to streamline model development. Other tools can then be used to build application containers and leverage Kubernetes resources to train models. A server can then be deployed for ML inference.
Kubeflow is ultimately designed to make it easier for developers to utilize popular cloud-native Kubernetes resources. “Deploying Kubernetes optimized for ML and integrated with your cloud is no easy task,” community leaders noted in a blog post. Kubeflow 1.0 is designed to reduce those steps to a single command.
Kubeflow 1.0 applications.
“One of our key motivations was to leverage Kubernetes to simplify distributed training,” lead developers said. “Kubeflow provides Kubernetes custom resources that make distributed training with TensorFlow and PyTorch simple.”
IBM (NYSE: IBM), the second largest code contributor to Kubeflow after Google (NASDAQ: GOOGL), said it is evaluating the machine learning tool kit for production deployments on its cloud and Power platforms along with Red Hat OpenShift. Kubeflow also can be deployed on Amazon Web Services (NASDAQ: AMZN) and Google Cloud Platform.
Kubeflow’s design is based on the concept of a machine learning pipeline that includes all the steps in a given data science workflow. Developers start by obtaining data from a local or remote source, transforming data, loading it into an ML model running on a laptop, then initiating the training of that model on a larger cluster, using one or more data sets.
IBM was an early contributor to Kubeflow pipelines used for machine learning workflow orchestration, the company said in a separate post.
Google initially created Kubeflow to manage its internal machine learning pipelines written in Tensorflow and executed atop Kubernetes.
Kubeflow leverages the cluster orchestrator to provide a higher abstraction level for ML pipelines, thereby freeing data scientist to focus on adding value to machine learning models.
The emergence of Kubeflow closely tracks production deployment of Kubernetes, addressing many of the teething problems faced by early adopters as they struggle to get the machine learning models trained on cloud-native platforms.
Organizers said the Kubeflow project has so far attracted contributions from more than 30 companies.
Recent items:
Kubeflow Emerges for ML Workflow Automation
In Search of a Common Deep Learning Stack
Vendors:
Google Cloud Platform
Leading Solution Providers
















