


August 6, 2019
The Anatomy of AI: Understanding Data Processing Tasks

(whiteMocca/Shutterstock)
So you’re collecting lots of data with the intention to automate decision-making through the strategic use of machine learning. That’s great! But as your data scientists and data engineers quickly realize, building a production AI system is a lot easier said than done, and there are many steps to master before you get that ML magic.
At a high level, the anatomy of AI is fairly simple. You start with some data, train a machine learning model upon it, and then position the model to infer on real-world data. Sounds easy, right? Unfortunately, as the old saying goes, the devil is in the details. And in the case of AI, there are a lot of small details you have to get right before you can claim victory.
One person who’s familiar with the complexities of data workflows for AI and ML projects is Avinash Shahdadpuri. As head of data and infrastructure at Nexla, Shahdadpuri has helped build AI pipelines for some sizable firms, including a Big 4 asset management firm in New York and a major logistics firm that tracks packages for retailers.
According to Nexla, which has just published a white paper titled “Managing Data for AI: From Development to Production,” upwards of 70% of the time and energy spent in AI projects is consumed by preparing the data to be consumed by the ML algorithms. This data-management work can be broken down into a handful of phases, including:
- Data discovery: What data do you need, and how do you find it?
- Data analysis: Is the data useful for ML? How do you validate it?
- Data preparation: What format is the data in? How do you transform it into the correct format?
- Data modeling: What algorithm can you use to model the data?
- Model evaluation: Is the model working as expected? What changes do you need to make?

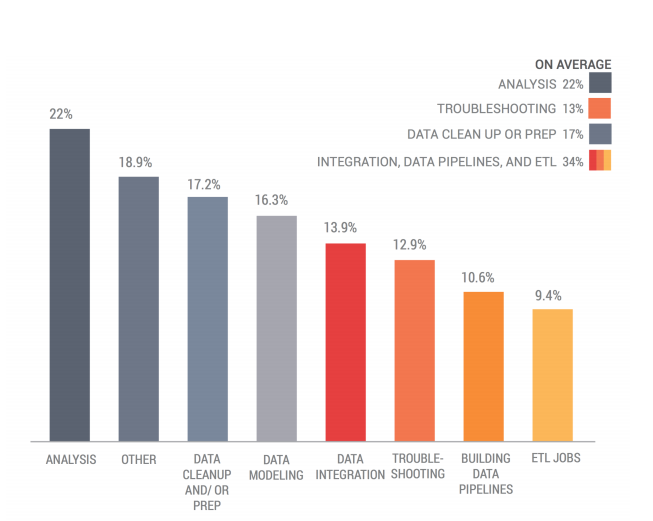
Time spent in different tasks in AI project (Image courtesy of Nexla)
Some of these tasks might be longer or shorter depending upon the type of data you’re working with and the type of problem you’re solving, Shahdadpuri says. “If your data is very segmented, you might have a bigger discovery phase,” he says. “If you’re very intimate with the data, you might have shorter discovery phase, but you’ll still be doing these things on and off.”
Data catalog and discovery tools can be very useful for finding relevant data sets, Shahdadpuri says. But many enterprises have millions of different data sets, many of which have not been cataloged via metadata analysis. That could lessen the usefulness of cataloging tools when workign with dark data sets. Now you’re back to fishing in the data lake with a fishing pole and hoping to get lucky.
But once you’ve found the right data, your problems aren’t over. Some of the most taxing problems in ML and AI stem from data preparation and data format challenges, Shahdadpuri says.
Selecting the right data attribute is a critical element of the AI and ML process. For example, if a data scientist wanted to predict the value of a house using Census data, he might look to features like location (given in lat/long coordinates), school district ratings, the crime rate of a Zip Code, or the age of the house.
The data scientist must be sure that the data attribute he’s looking for is always present in the data, and is stable to boot. Fluctuating scales, like changing from Celsius to Fahrenheit for temperature or from Imperial units to the metric system, will cause the algorithm to go haywire. While these may seem obvious, gremlins inevitably arise. Perfectly clean and accurate data is all too rare in the real world.
Part and parcel of the data preparation phase is feature extraction, which is one of the most fundamental aspects of data preparation work in AI and ML, Shahdadpuri says. But it’s also one of the most difficult and expensive phases of the process. That’s because it often requires domain knowledge and a lot of trial and error.

(Image courtesy Nexla and its white paper, “Managing Data for AI From Development to Production”)
Before an algorithm can train on a piece of data, it must be converted into a machine-readable format that it understands, which is another critical step in the AI and ML process. Scientists may have to encode the data a certain way, or use bucketization or binning techniques to represent data values in certain ranges. Winsorization is another technique used to limit extreme values in statistical data, Shahdadpuri says.
“You might have a CSV, a Parquet, or Avro file. But the models cannot understand all of these formats,” he says. “It needs to be converted to a format that the model can understand.”
Once the data is fully prepped and in the correct format, the data scientist can write an algorithm, or a pre-written one, to model the data. This starts the productionalization phase of the AI and ML journey, which has its own set of challenges.
Depending on how big the data the company is working with, an engineer may seek to automate the preparation tasks by writing ETL or ELT scripts. These scripts can be used to ensure that both the training and the production data pipelines are getting reliable and clean data.
Some companies may choose to use a new generation of AutoML tools to help automate many of these tasks. However, in Shahdadpuri’s view, these AutoML tools often do not deliver the full breadth of automation that the customers expect.
Nexla recommends centralizing as much of the big data architecture as possible. The company develops a tool that can help automate much of this work and standardize many of these repeatable tasks.
“You should not spend 70% of the time doing the boilerplate activities,” Shahdadpuri says. “You should spend time actually writing the models and deriving insights out of it rather than trying to connect this format of data, converting it to another format and stuff like that, because that doesn’t really add value.”
To read Nexla’s white paper, please see www.nexla.com/resource/managing-data-for-ai/.
Related Items:
Big Data Is Still Hard. Here’s Why
How to Build a Better Machine Learning Pipeline
Big Data File Formats Demystified
Applications:
Artificial Intelligence
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Nexla
Leading Solution Providers
















