


March 11, 2019
What Makes Apache Spark Sizzle? Experts Sound Off

(ami mataraj/Shutterstock)
Apache Spark is one of the most popular open source projects in the world, and has lowered the barrier of entry for processing and analyzing data at scale. We asked some of the leaders in the big data space to give us their take on why Spark has achieved sustained success when so many other frameworks have fizzled.
It’s hard to believe that Spark is already 10 years old. That has given the technology time to mature to a point where it’s now being widely adopted. One of the places it’s seeing lots of action is Qubole, a cloud-based big data processing service founded by Ashish Thusoo.
“Spark is a great fit for in-memory processing workloads and we see Spark usage growing for batch ETL, streaming ETL, and machine learning workloads in our user base,” says Thusoo, who also led the development of Apache Hive while leading the infrastructure team at Facebook.
“Given the multiple language support such as Python, R and Scala; multiple use case support; and growing community of Apache Spark, we think Spark is here to stay and thrive for the workloads it is a great fit for,” the Qubole CEO says.
Spark usage grew nearly 300% last year at Qubole, which hosts Spark clusters for clients like Lyft, Grab, Adobe, Oracle, Malaysia Airlines, IQVIA, and Activision. “We are strong supporters of Apache Spark and see a lot of opportunities for innovation where we can contribute,” Thusoo says, adding that Qubole contributed projects such as SparkLens and RubiX to the Spark community in 2018.
Bala Venkatrao, vice president of product at Unravel Data, credits Matei Zaharia and his colleagues at UC Berkeley’s AMPLab (where Spark was created) for having a clear vision of how computing infrastructure would evolve and how to create new software abstractions that would generate big productivity dividends.
“They really thought through it — Where does MapReduce stop, and what is the next generation, evolution of that? Venkatrao tells Datanami. “The AMPLab guys at Berkeley clearly saw that infrastructure hardware would improve. You would have a lot more compute and memory resources available as part of your cluster, so you don’t to check-point things to disk all the time, and you leverage your memory effectively.”
Spark was developed to replace MapReduce in the Hadoop pipeline, but it’s widely adopted outside of the Hadoop ecosystem. That raises some questions about the future of Hadoop, Venkatrao says.
“The bigger question is do you really need HDFS?” he says. “That’s the question people are asking because now you can have all of your data in BLOB stores like S3 and you can run Spark directly on that. Do you really need HDFS? Do you really need YARN?”
Eclipsing Hadoop
According to a survey that Unravel Data conducted in January, Spark was the second most deployed big data technology, with 31% of respondents deploying it, compared to 32% for Hadoop. That’s evidence that Spark is on the cusp of transcending Hadoop, the framework that it was originally created to work within, the company says.
“The data illustrates that Spark has ascended and may soon eclipse Hadoop in popularity,” Unravel Data CEO Kunar Agarwal wrote in a recent blog post. “Spark was the number one big data technology that IT decision makers plan to deploy for the first time in 2019 (16%). Spark is frequently used for streaming applications common in healthcare, e-commerce, social media and financial sectors. Emerging technologies such as IoT also increasingly use streaming apps that rely on Spark.”
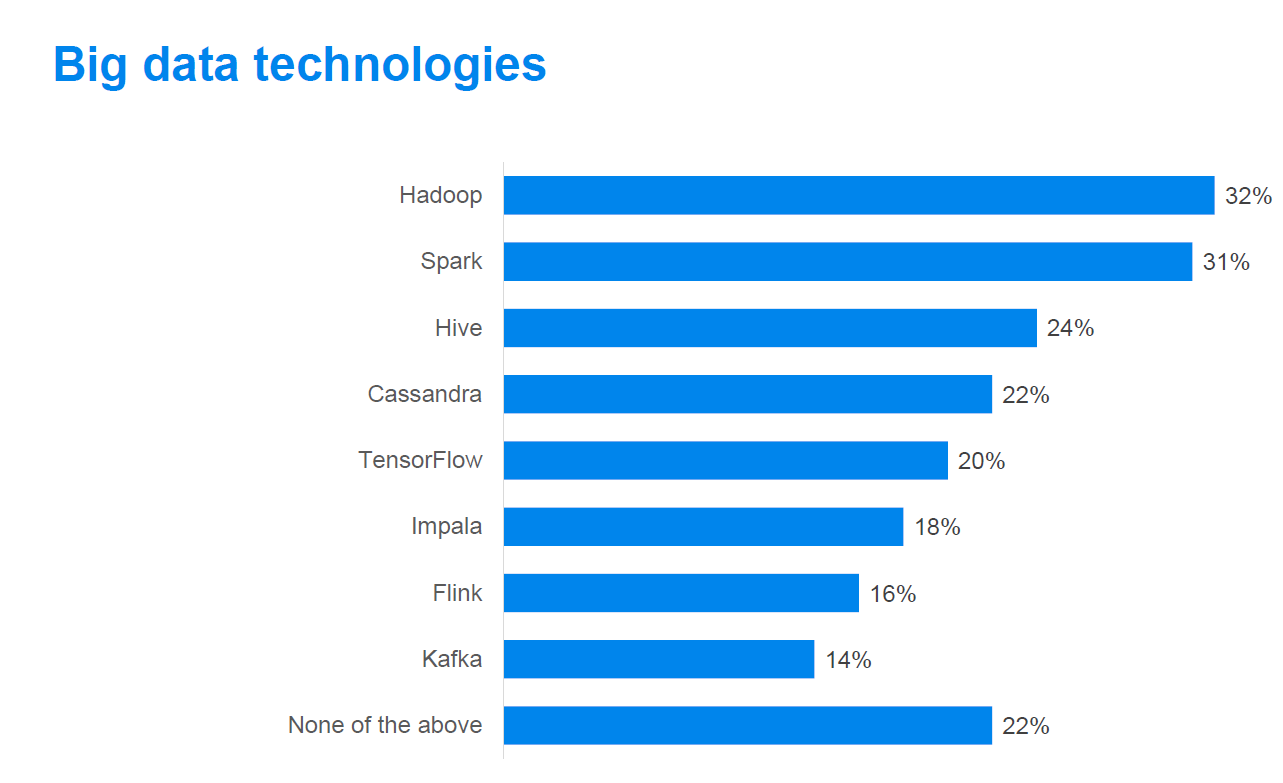
Unravel Data asked “Which big data technologies are you currently deploying” to 302 survey-takers (Source: Unravel Data)
Another big believer in Spark is IBM, which has invested large amounts of time, money, and talent into developing the open source technology. The technology giant founded the IBM Spark Technology Center, contributed code to Apache Spark, made the framework available on its Power and System z platforms, and integrated it into various products.
Seth Dobrin, who heads up IBM’s Data Science Elite Team, says what gives Spark its major mojo is the fact that it’s not a one-trick pony, like other processing frameworks in the Hadoop ecosystem.
“The thing that has given Spark the legs that it has is…it’s a way to interact,” Dobrin tells Datanami. “It was built to get rid of MapReduce on Hadoop environments, and now it’s used for so many other things outside the Hadoop ecosystem.”
Folks who are developing data applications should know how to interact with Spark, or at least use Spark programs to interact with different data sources, Dobrin says.
“You can have one interface for just about any database,” he says. “I can leverage Spark to access Hadoop or Microsoft SQL or Red Shift or Db2. And it does it in a highly performant manner….A lot of our data science platform under the hood is leveraging Spark because it’s so performant.”
‘More Than a Shooting Star’
Like Hadoop, Spark in its early days was dogged by questions about its suitability for the enterprise. Those questions have been answered, and today Spark is widely deployed across multiple industries.
At the Spark+AI Summit two years ago, we heard about three of those production use cases. We heard how data scientists, data engineers, and business analysts at Capital One catch fraudsters by processing big data using Spark and other technologies. We also heard how cancer researchers at the drug company Roche use a statistical package called Spatial Spark to improve their analysis of images of tumors.
Teradata CTO Stephen Brobst has seen his share of hype, in Hadoop and elsewhere. But in his view, the continued excitement around Spark — which the company plans to support (along with TensorFlow) with its new Vantage analytics platform unveiled last year — stems from some other force.
“There will be new things coming in the years – a new engine, a new shiny object,” Bropst said during a session at last fall’s Teradata Analytics Universe conference. “Some will go down quickly, some will continue to go up. Spark was much more than a shooting star.”
Splice Machine was an early backer of Spark, which the company has paired with HBase to create an updateable, ACID-compliant database in Hadoop to power operational applications. A year ago, the company doubled down on Spark by using the DataFrame API to power CRUD actions in its database.
Monte Zweben, the CEO of Splice Machine, says Spark is a critical element of his company’s success. “I would argue that Spark in particular has a lot of legs,” he says. “It’s a powerful infrastructure that’s infinitely adaptable and will continue to mature. I think that thing will be around for a long time, in particular, out of all these [big data] technologies.”
Spark is the rare five-tool player that can do the data equivalent of run, throw, field, and hit for average and power. Its bona fides among data engineers building ETL jobs and data pipelines are nearly unimpeachable, but its future applicability in the emerging machine learning and AI worlds are what get technologists excited.
Despite the hype around machine learning, production use of machine learning and AI technology has a long way to go to be anything near ubiquitous. As those use cases ramp up over the next few years, Spark stands to capture a good chunk of those workloads, Unravel Data’s Venkatrao says.
“You’ll clearly see Spark as the underlying platform that powers those applications,” he says. “Those could be written in Python, R, notebooks, or using some high level tools, but under the hood, they definitively use Spark to run those applications.
Related Items:
A Decade Later, Apache Spark Still Going Strong
Apache Spark: 3 Real-World Use Cases
Spark Streaming: What Is It and Who’s Using It?
Applications:
Data Mining
Technologies:
Frameworks
Leading Solution Providers

















