


March 5, 2019
Data Engineering Continues to Move the Employment Needle

Interested in a career in big data? You could do well by investing your time and effort in acquiring data science skills. But you may do even better by turning yourself into a data engineer, which is a title that continues to see substantial demand in the job market.
A year ago, we declared 2018 to be “the year of the data engineer.” And there was good reason for that, as companies in Silicon Valley and the real world struggled to find qualified engineers who can handle critical tasks like building data ingestion pipelines in Kafka, constructing data warehouses and lakes on Hadoop and S3, programming distributed systems like Spark, transforming and preparing data for analysis, and stitching data sets together for training downstream machine learning models.
The shortage was reflected on online job boards. A year ago, Glassdoor and Indeed listed roughly four times as many openings for data engineer as they did for data scientists. A quick search in March 2019 reveals that the situation hasn’t changed much, with about 94,000 to 124,000 openings nationally for data engineers versus 27,000 to 33,000 openings for data scientists.
This ratio of job openings roughly jibes with the ratio of data engineers and data scientists that companies should shoot for. “A common starting point is two to three data engineers for every data scientist,” writes Jesse Anderson, the managing director of the Big Data Institute, in a 2018 O’Reilly story. “For some organizations with more complex data engineering requirements, this can be four to five data engineers per data scientist.”
Dice found demand for data scientists increased 97% year over year
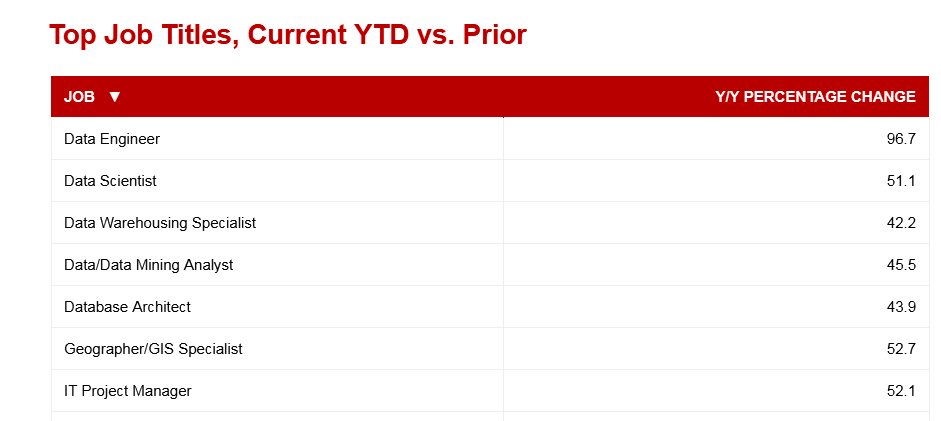
Data engineer was the hottest tech job in December, according to a recent blog post by Dice. Data engineer had a 96% year-over-year change in demand, according to data collected by Burning Glass’s Nova platform. That was well ahead of the 51% change in demand for data scientists, which had the sixth-highest change in demand, Dice’s post shows. Data warehousing specialists, database architect, and data mining analyst all saw the percentage of job openings increase by 40% to 50%, according to the Burning Glass data.
Academic institutions and trade schools have responded to the big demand for data engineers by adding more classes and degree programs for educating and training the next generation of workers. In many cases, the coursework for data engineers is included in data science or general computer science curriculums, although increasingly data engineering is standing on its own.
One educational outfit that’s taking data engineering demand by the horns is Udacity. The company which has been at the forefront in training the next generation of data scientists, is branching out into data engineering with today’s launch of its new Data Engineer Nanodegree Program.
According to Sam Nelson, the product lead for Udacity’s data programs, the new nanodegree program is designed to help students learn the technical skills required to become a data engineer. “With the launch of this program, anyone with an Internet connection (and the relevant background and skills) will be able to enroll. Companies all over the world are looking for data engineers and our goal is to help anyone who wishes to land a job in the field can do so.”

Udacity is rolling out its new data engineering program
Udacity’s program is divided into four courses and involves five projects that revolve around a hypothetical music streaming company. The company says students will play the part of a data engineer who’s tasked with managing the increasing volume, velocity, and complexity of data.
The first course introduces Udacity students to data modeling, including relational and NoSQL databases. The students will use Postgres and Apache Cassandra to store activity data for a music streaming app.
The second course involves cloud data warehouses, as students will get a chance to create an ELT pipeline that takes data from Amazon S3 and moves it into Amazon Redshift before transforming it into a set of dimensional tables.
The data gets even bigger with the third course, which introduces the students to the big data ecosystem of tools, including Apache Spark. Students will use Spark to build an ETL pipeline for a data lake built on S3.
Students will be introduced to big data pipelines in the fourth course, which focuses on scheduling, automating, and monitoring data pipeline activities via Apache Airflow in support of the hypothetical streaming music app. A capstone project will finish off the class.
Source: Paysa
Udacity developed the curriculum for the course by working with data engineers from Insight Data Engineering, Slack, Stitchfix, and Uber. Registration is currently open for the course, which begins on April 2 and costs $999.
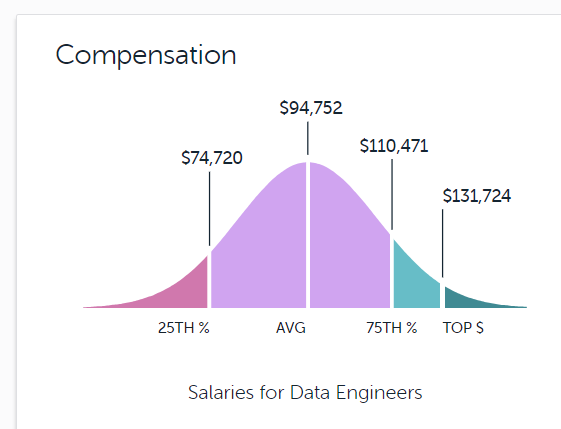
The pay is good for data engineers. According to data from Paysa, data engineers can expect a salary between $75,000 on the low end to around $132,000 for top earners. The company, which summarized the data from more than 9,000 data engineers, found that 46% of them had Bachelor’s degrees, 14% had Master’s, and 3% had PhD.s. Python and SQL were listed as common data engineer skills.
Location matters for pay. According to Hired’s “2019 State of Software Engineers” report, data engineers can expect data engineer job to pay about $132,000 in in New York and $151,000 in San Francisco. The study, which was released last week, found there was a 38% increase in demand for data engineers
But there’s another engineering job that’s just starting to make its way onto the job boards that exceeds the demand of data engineer. According to Hired, demand for blockchain engineers is “through the roof,” at 517% year over year. The job also pays a bit better than data engineer.
Engineers with an expertise in blockchain “typically hold titles such as backend engineer, systems engineer or solutions architect, with blockchain being listed as a desired skill for the role,” the company says. Hired expects demand for blockchain engineers to continue into 2020, as businesses begin implementing blockchain use cases, which span from digital identity and smart contracts to workforce management and distributed data storage.
Related Items:
What’s Driving Data Science Hiring in 2019
Why 2018 Will Be The Year Of The Data Engineer
Applications:
Data Mining
Sectors:
Academia
Tags:
big data, data engineer, data team, engineering, Hadoop, job market, Kafka, personnel, Spark, udacity
Leading Solution Providers
















