


January 16, 2019
Benchmarking NoSQL Databases

via Shutterstock
Developers have a large number of databases to choose from today, particularly when it comes to newer NoSQL databases. Figuring out which databases excel in different areas can be tough, but the folks at Altoros aimed to help to narrow the field by benchmarking the three leading NoSQL database solutions, Couchbase, DataStax Enterprise, and MongoDB.
Altoros Systems is a Sunnyvale, California-based engineering company that helps enterprises evaluate technology and implement technological solutions spanning AI, blockchain, and operational databases. The company has also taken it upon itself to shine more light on the inner functions of NoSQL databases, with the goal of helping organizations make better architectural decisions.
In late 2018, the company set up a benchmark test to see how the databases from Couchbase, MongoDB, and DataStax compared. The company has run tests with these databases other before, and it’s worth noting that it is a contributor to the open source Couchbase Server product.
Altoros set up three separate hardware configurations that were composed of four, 10, and 20 nodes. The clusters were deployed on Amazon Web Services, using a storage-optimized extra-large instances, or i3.2xlarge, each of which sports 8 vCPUs, 61GB of RAM, and a single 1,900GB SSD.
Altoros configured Couchbase Server v5.5 with the Data Service, Index Service, and Query Service turned on; the Search, Analytics, and Event services were disabled. The Data Service was given 60% of the RAM and the Index Service 40%. MongoDB v3.6 was configured with a hierarchical topology that included a config server, router services, and shards. Data was sharded across available nodes using a hash-based partitioning scheme. The DataStax Enterprise v6 (based on Apache Cassandra) YAML file was configured in a standard manner for resources like memtable heap spaces and cleanup thresholds, row cache sizes, and commit log sizes.
The workload to be tested was the Yahoo Cloud Serving Benchmark (YCSB), which is an open source suite of programs used to see how well databases can perform common data retrieval and maintenance functions. YCSB would be used to conduct four separate tests for each of the nine database clusters. Each test was configured so that all the data would fit entirely in memory. It also turned off any data durability settings, and kept just a single replica copy of data for each data set.
The first benchmark test was an update-heavy workload that was made up of 50% database reads and 50% database updates, which simulated an ecommerce setting. “Couchbase significantly outperformed both MongoDB and Cassandra across all cluster topologies,” Altoros says in its 29-page report.
MongoDB “scaled well” on this first test, and continually decreased processing time, but suffered on smaller nodes due to the background activity of the balancer that tried to balance chunks of data across the shards, the company says. Cassandra also scaled well but still underperformed Couchbase’s throughput by 50% on a 20-node cluster.
The second workload was a short-range scan workload that contained 95% scans and 5% updates, which simulates threaded conversations. MongoDB outperformed the two other databases on the four-node test, but failed to scale much beyond 14,000 operations per second regardless of cluster and data set size, Altoros says.
Couchbase “demonstrated great scalability” with near linear growth of throughput from four to 10 and 20 node clusters, with latency remaining around 10 milliseconds. Cassandra (or DataStax Enterprise), meanwhile, showed “rather low performance” with the scan operations, Altoros says.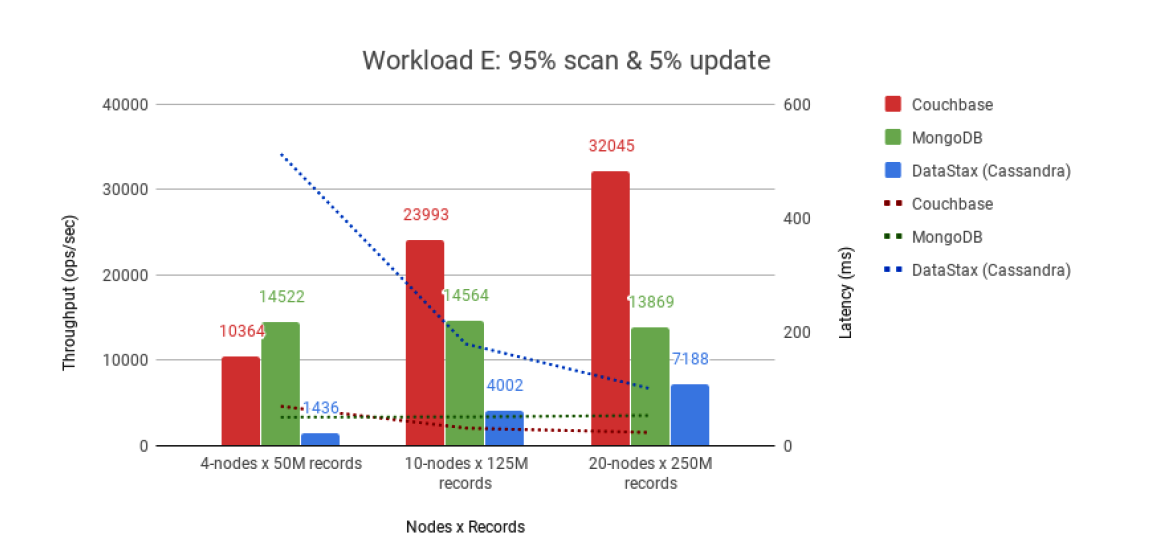
However, Cassandra “provided better scalability” than the other two databases, Altoros says. While latency for Cassandra was higher, the drop in latency for Cassandra as the cluster got bigger was notable, which Altoros attributes to how the coordinator node sends scan requests to nodes responsible for specific token ranges.
The third workload benchmarked represented a pagination workload – specifically a query with a single filtering option to which an offset and a limit are applied – which is more of a BI workload.
Couchbase “significantly outperformed” both MongoDB and DataStax on this test, which Altoros attributes to its use of memory-optimized secondary indexes. Since the data set for the tests were selected to fit within memory (if not within Cassandra’s cache), Couchbase excelled at this benchmark. For MongoDB, Altoros configured memory-optimized global secondary indexes for filtering fields, along with index replication on each cluster node.
Cassandra did not do well on this test. The engineering company admitted that “data filtering is not a typical use case for Cassandra, as the database is designed to be queried by a primary key.” It tried using a secondary index and synthetic sharding on Cassandra, but it failed the four-node test, so Altoros didn’t bother running it on 10- and 20-node setups.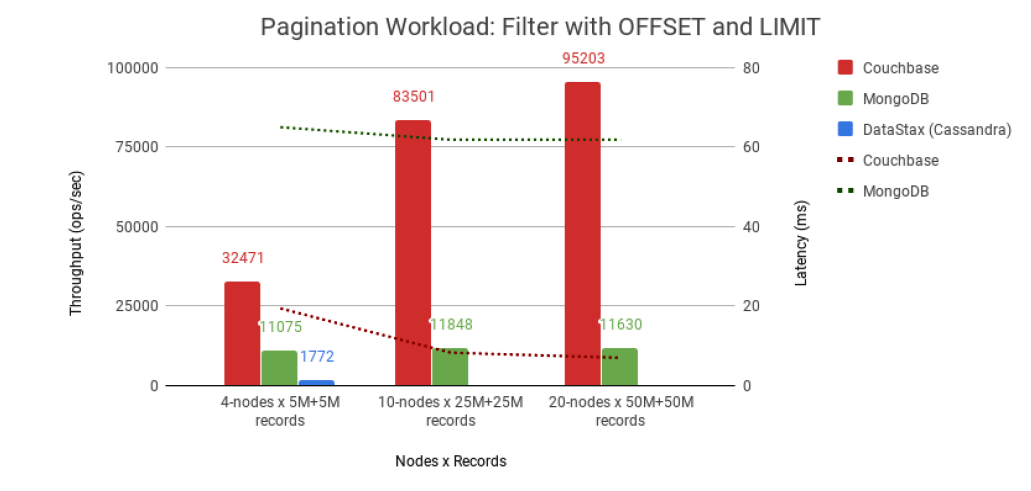
The fourth workload was a JOIN query with grouping and ordering applied, another BI-type workload. Once again, Couchbase delivered the top results, with Cassandra failing to make the cut in the end. “In general,” Altoros says, “Couchbase significantly outperformed MongoDB regardless of data set and cluster sizes.” This is likely due to the fact that Couchbase was the only database tested here that supports JOIN operations out of the box.
MongoDB supported the equivalent of a left outer join, which the benchmark called for. However, the MongoDB function was only available for non-sharded data collections for the version of the database that it used. Altoros configured a substitute method, dubbed “read parent-read dependencies,” but it “performed rather poorly and appeared to be non-scalable,” Altoros says.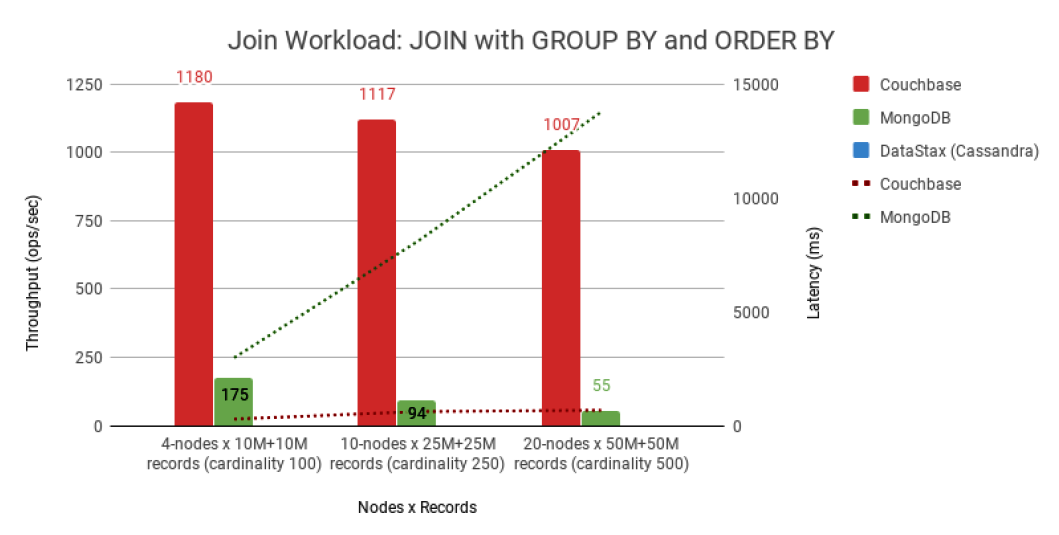
The fact that each of these database displayed different strengths and weaknesses isn’t surprising. Cassandra, Couchbase, and MongoDB are all ostensibly NoSQL database management systems, but each one is built and runs in a different manner, which means they excel at different things.
Couchbase, Altoros says, “demonstrated good performance across all the evaluated workloads and appears to be a good choice, providing out-of-the-box functionality sufficient to handle the deployed workloads and requiring no in-depth knowledge of the database’s architecture.
MongoDB produced comparatively decent results on relatively small clusters, the company says, and is scalable enough to handle bigger data sizes and clusters. “Under this benchmark, the one issue we observed was that MongoDB did not support JOIN operations on sharded collections out of the box,” Altoros says.
Cassandra, meanwhile, provided good performance on some workloads but not others. “In general, we proved that Cassandra is able to show great performance for write-intensive operations and reads by a partition key,” Altoros says. “Still, Cassandra is operations-agnostic and behaves well only if multiple conditions are satisfied.”
More details are available in Altoros’ report, which you can download from this page.
Related Items:
The New Math Driving NoSQL Analytics
MongoDB Users Discuss Their NoSQL Journeys
Three NoSQL Databases You’ve Never Heard Of
Tags:
benchmark, cassandra, Couchbase, database, JOIN, mongodb, NoSQL, performance, performance bencmark, throughput
Leading Solution Providers
















