


November 20, 2018
Inside Pachyderm, a Containerized Alternative to Hadoop

Last week was a big one for Pachyderm, the containerized big data platform that’s emerging as an easier-to-use alternative to Hadoop. With a $10 million round of funding, public testimonials from customers like the Defense Department and AgBiome, and a new release of the software its creators say runs 1,000 times faster, the potential for Pachyderm to have an impact in big data are growing by the day.
The Pachyderm story starts back in late 2013. Joe Doliner and Joey Zwicker were working at a Y Combinator startup called RethinkDB, when they saw an early tech preview of what would become Docker from Solomon Hykes, its creator. Both of the technologists were immediately impressed, and they started working on a way to leverage Docker to solve some of the problems that were emerging in the big data space.
Interest in Apache Hadoop was surging at the time, and many saw Hadoop as the best way to store and process massive amounts of data being generated. A large ecosystem around the core Hadoop platform was quickly taking off as organizations utilized the Java-based technology to transform inexpensive X86 computers into powerful clusters.
Doliner worked with Hadoop for a year as an engineer at Airbnb, where he was part of a 25-person team responsible for keeping the infrastructure running for Airbnb’s data scientist and analysts. The experience opened his eyes to the benefits of clustered computing, but also its difficulties. While he appreciated how powerful emerging tools like Spark and Presto could be in data scientists’ hands, he also grew frustrated with the day-to-day difficulties of keeping Hadoop clusters running.
“We felt like all the outages we had were being caused by simple problems, like Zookeeper going down or something like that,” Doliner said. “None of the support contracts we had could really help with that. They were always trying to sell us add-ons. The industry had fragmented to the point where nobody was dealing with the simple, important things.”

Pachyderm CEO and co-founder Joe Doliner
Dolinar and Zwicker decided there was a potential market for a simpler, containerized version of Hadoop, one where a single entity maintained control over the architecture and could be held to account when problems emerged. This new project would retain some elements of Hadoop – and would even be compatible with some elements. But the duo were adamant that things wouldn’t be allowed to fall between the cracks, as has been the case with Hadoop and its overly complex integration schemes.
We wanted to restore some sanity to this,” Doliner said. “We wanted to have a new take with stuff that we could control, so that we could have people able to buy a system like this from one vendor, that it actually made the whole system and understood it and could support all of it and would care about the little details.”
Pachyderm Parts
In 2014, Doliner and Zwicker founded a company called Pachyderm in San Francisco. The company develops a distributed platform also called Pachyderm that’s developed in an open source manner at GitHub.
Just as HDFS and MapReduce defined the early days of Hadoop, the Pachyderm architecture starts with two main elements, including a distributed file system and an execution layer, which are pre-integrated and designed to work together.
While there are similarities with Hadoop at a high level, there are key differences too. Doliner says Pachyderm’s distributed file system is similar to HDFS in terms of its distributed nature and the amount of data that it can store. But offers additional features that help organizations manage their data.
“Where it’s very different from HDFS is it also provides version control semantics and provenance tracking semantics for the data,” Doliner says. “So you’re able to store several petabytes of data, but you’re also able to have snapshots going back in time of what this data looked like yesterday and the day before that, and you’re able to link the different pieces together.”
The province tracking capabilities of the Pachyderm file system has emerged as a major selling point, particularly for banks that are using the platform to power machine learning workloads, such as for assessing risk of a potential loan.
“They want to be able to say conclusively ‘This model that we’re using to determine the loan has all of this data in it and nothing more. You can see we’re taking into account income…and past credit scores, but we’re not taking into account race or gender or things like that,'” Doliner says.
The other main element of Pachyderm – its execution layer – is based on Docker. Users can run any data processing tool they want on Pachyderm, as long as it’s compatible with Docker and there is a Docker image available for it, Doliner says.
Pachyderm uses Kubernetes as its resource scheduler, which replaces YARN in the Hadoop scheme. The first step in getting Pachyderm’s execution layer setup is to configure a Kubernetes cluster. Once Kubernetes is in place, getting Pachyderm up and running is a relatively simple manner, Dolimer says.
Simplified Cluster Computing
By building Pachyderm atop Docker and Kubernetes, Doliner hopes to deliver a powerful platform for cluster computing, but without elements of technical complexity that has come to define Apache Hadoop and the Hadoop ecosystem.
“We see Pachyderm as the base layer. We want to go below everything else,” he says. “The fact that our API, the way you write code for Pachyderm, is all Docker containers means that we have a very natural way to integrate other types of services onto the Pachyderm file system. You still get version control and provenance semantics, but you can use all these other tools.”
While it has built a new file system, Pachyderm isn’t throwing away everything in the Hadoop system and starting from scratch. Instead, the company – which won the startup showcase at the Strata + Hadoop World conference two years ago — hopes to build on some key parts on Hadoop.
“We think there are definitely good parts of the Hadoop ecosystem that, software wise, we want to run,” Doliner says. “Spark is a good technology. I like Hive. I like Presto a little better, so we definitely want to run all those. We’re more shying away from the corporate structures around the Hadoop ecosystem.”
Doliner says the main benefit of Pachyderm’s approach is the simplified access to data that it brings data scientists benefit. Instead of requiring a team of engineers and support people to build and maintain a Hadoop system, data scientists can get up and running with Pachdyerm without much difficulty. Some firms are running Pachyderm in production with just a single data scientist managing it.
The “magical bit” that makes Pachyderm unique, Doliner says, is how simple and natural it is for data scientists to access data stored on the system. “It’s just a simple open a file, read, open another file, write to it,” he says. “We can scale it up arbitrarily large. We can run thousands of containers to make their code scale to huge amounts of data….The reason that that’s so magical for users is that allows them to deploy any tools that they want.”
Image processing has been a popular use of Pachyderm clusters thus far. While there are a handful of image processing libraries for Hadoop, the ones outside of Hadoop are older and more mature. OpenCV, in particular, is available in a Docker image and has been well-received by the Pachyderm community. So have a range of bioinformatics tools.
Tensorflow is another popular data science tool that’s gaining traction on Pachyderm. “That’s something else that doesn’t fit nicely in Hadoop but fits very comfortably in a container,” Doliner says. “It’s very powerful in Pachyderm.”
One of the benefits of Pachderym is that it doesn’t developers to be fluent in Java to be able to work with it. Hadoop was written in Java, and while it does support software written in other languages, getting them to run isn’t always as natural.
“We have people using Python, R, Go, Rust. We have basically every language,” Doliner says. “It’s been really interesting to see all of the different ways that people want to process data when they’re not pigeonholed into just using Java because that’s the only thing that will run on their system.
Looking Forward
The core of the Pachyderm software is open source and free to use. If organizations want additional functions such as advanced security, monitoring, and a pipeline building tool, they are encouraged to pursue an enterprise license with the Pachyderm company.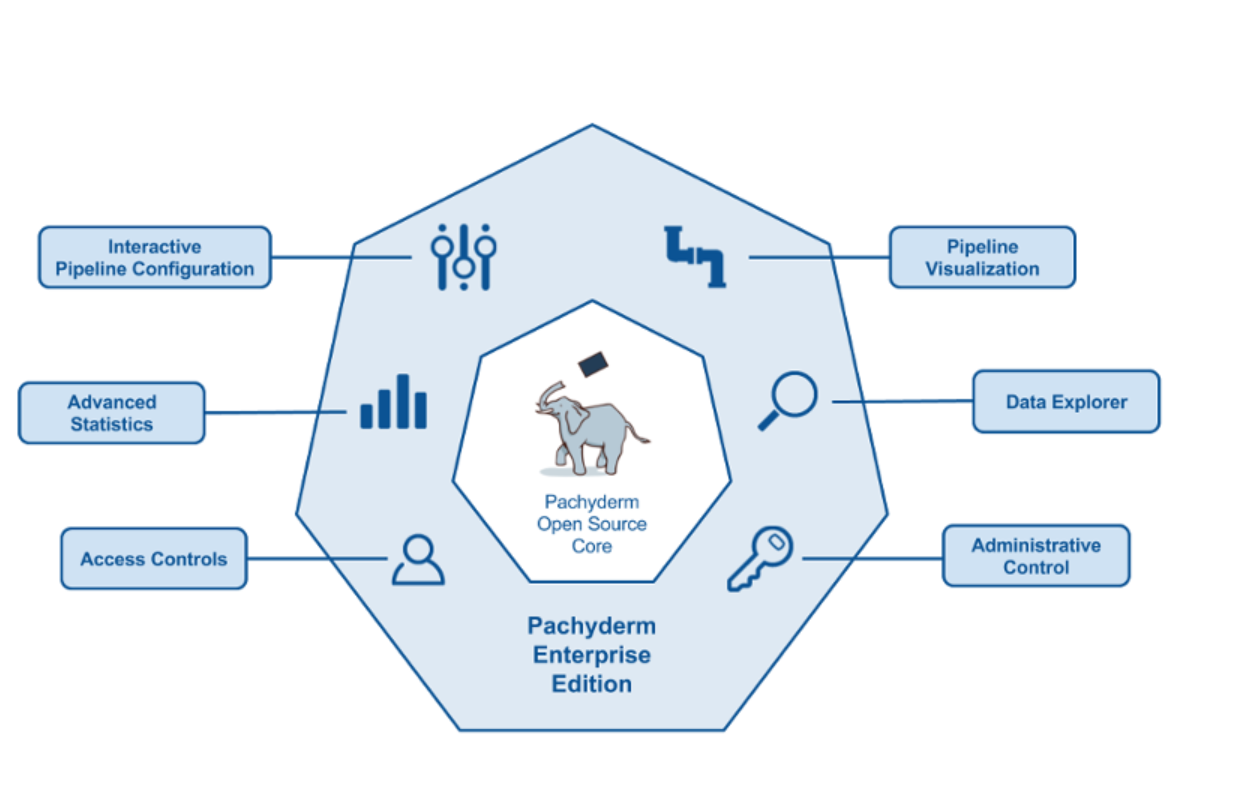
The company is also pursuing a cloud service strategy, whereby data scientists can access Pachyderm capabilities in a GitHub-like manner. In the PachHub model, the Pachyderm software helps data scientist manage data and models, as well as executing machine learning workloads.
“If you think of Pachyderm as Git for data science as it exists today, then PachHub is going to be this online site where people can basically collaborate on data science the same way that GitHub allows people to collaborate on software development, Dolimer says.
Last week it announced the completion of a $10M Series A round of investing, which was led by Benchmark, which has also invested in other big data firms that have gone on to be successful, including GitHub, MongoDB, and Elastic. The round was led by Chetan Puttagunta, and it was his first investment since he joined the venture capital firm.
The company also announced a version of Pachyderm, version 1.8, that it says is about 1,000 times more scalable on popular workloads. Lastly, the company received permission from customers, including DOD, AgBiome, and Boston Consulting Group to start talking about what they’re doing with the software.
While Pachyderm is open to working with partners, it’s also hoping to keep control the project to avoid slipping down the rabbit hole of distributed complexity that has come to plague Hadoop. The company is receiving a ton of requests these days to integrate other big data projects, such as Kafka, Flink, and Pulsar, into Pachyderm, and chances are some will make it in.
“It’s just such an exciting time to be in data tools,” Doliner says. “Every day I come in and somebody is trying to do something new with Pachyderm. Sometimes it’s a bit of a headache to be totally honest — but it’s a very exciting headache.”
Related Items:
Container Specialist Tops Strata Startup List
Leading Solution Providers
















