


November 8, 2018
What’s Driving the Cloud Data Warehouse Explosion?

(RoboLab/Shutterstock)
The advent of powerful data warehouses in the cloud is changing the face of big data analytics, as companies move their workloads into the cloud. According to analysts and cloud executives, the phenomenon is accelerating, thanks largely to the potential to save large sums of money, analyze even bigger data sets, and eliminate the hassle of managing on-premise clusters.
Amazon Web Services is largely credited with kicking off the cloud data warehousing (CDW) wave with Redshift. Since launching it in 2012, AWS has attracted 6,500 customers to Redshift and remains the company to beat thanks to its integration with AWS’ broad portfolio, according to a Forrester report on cloud data warehousing released last week.
But AWS Redshift has stiff competition, according to the Forrester report, which identified a total of 14 vendors in the CDW field. Those within shooting distance of AWS include Google Cloud, Snowflake, and Oracle, which Forrester identified as the other CDW leaders in its report.
Snowflake, which closed a $450 million venture funding round last month, has grown quickly thanks to the ease of use, high performance, and low cost of its SQL-based offering. Google Cloud’s BigQuery, meanwhile, was cited by Forrester for its integration with AI and other data services. Oracle, meanwhile, also landed in the leader’s category of the Forrester Wave with its new Autonomous Data Warehouse (ADW).
Ease of use is one of the biggest drivers of CDW, writes Forrester lead analyst Noel Yuhanna. “You can provision a cloud data warehouse in minutes without requiring any technical expertise, allowing business analysts and other nontechnical users to access, store, and process large amounts of data for insights,” he writes.
While early adopters of CDWs tended to be smaller firms and digital natives, there’s a trend where established organizations are moving their existing on-premises data warehouse to the cloud. Some customers who have moved their on-premise data warehouses or Hadoop clusters to CDWs report saving millions of dollars per year.
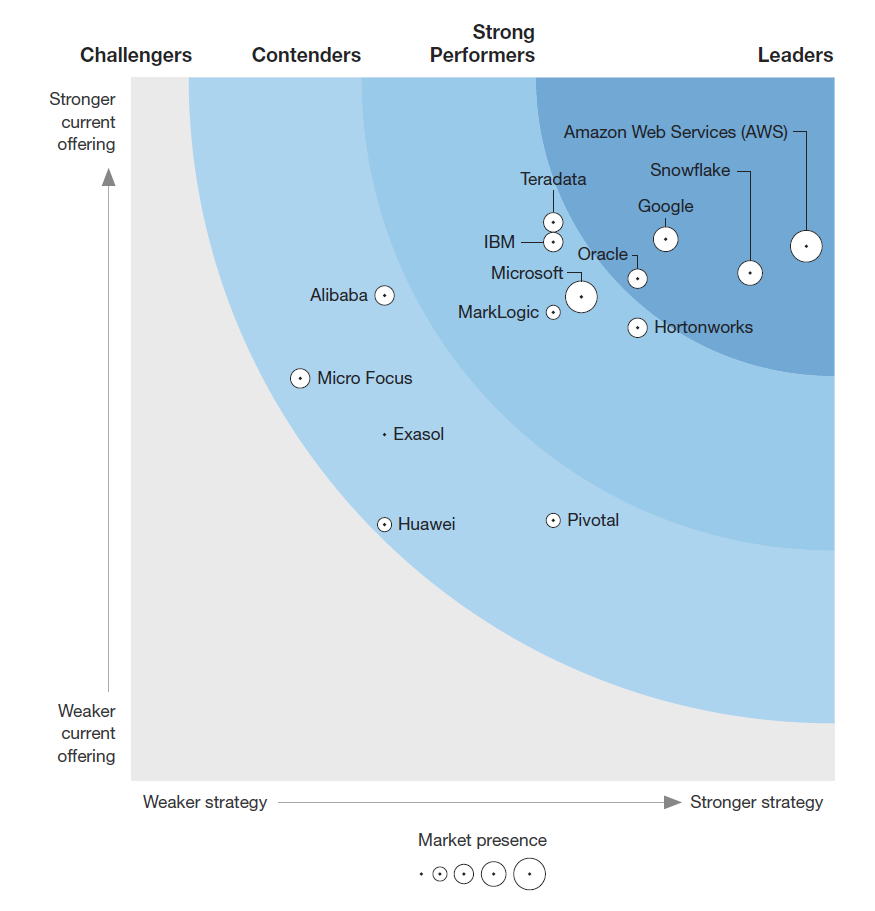
Forrester Wave for Cloud Data Warehouses 4Q18
“Most organizations find at least a 20% savings over on-premises data warehouses, while some have seen as high as 70% to 80% savings when implementing a CDW solution,” Yuhanna writes. ” In addition, many CDW solutions offer the ability to separate compute from storage, allowing organizations to be billed on the actual resource consumption, which saves money.”
Support for a more diverse array of data types also favor CDWs over traditional data warehouses, according to Forrester. “Traditional data warehouses don’t deal with IoT data,” Yuhanna writes. “However, CDWs offer the ability to efficiently store, process, and access large volumes of IoT data from sensors and devices.”
Google Cloud has also racked up some impressive customer momentum with BigQuery, which it introduced in 2011. The vendor says that from 2016 to 2017, the amount of data stored in BigQuery doubled, while overall Google Cloud usage increased by 4x. “We’re seeing a lot of momentum with customer adoption with everything we’re doing,” says Sudhir Hasbe, director of product management for data analytics at Google Cloud.
Google shared some gaudy figures with Datanami regarding the scale of its BigQuery customers. The biggest BigQuery environment houses 250PB, and the peak ingest rate for any customer is 4.5 Million rows per second. The largest query involved 5PB, and once BigQuery scanned 23 trillion rows of data for a single query.
The company is finding traction with companies that have invested lots of time and money in Hadoop. King, the company behind Candy Crush, runs one of the biggest Hadoop clusters in Europe, according to Hasbe. However, challenges with Hadoop led the company to invest in BigQuery.
“They were going to look at the challenges they faced from managing the cluster and scaling the cluster, especially when the new games were launched,” Hasbe says. “It was a huge problem for them.”
King currently ingests on the order of 50 billion events per day into its BigQuery environment, which is added to a CDW that spans 18 trillion rows of data, Hasbe says.
Twitter is is another big Hadoop shop that’s working with BigQuery. “They have one of the largest Hadoop clusters in the world, more than 300PB, tens of thousands of cores that they’re moving,” Hasbe says. “They’re using core infrastructure as well as BigQuery for analysis for those use cases.”
But it’s not just digital native companies that are moving to BigQuery. Hasbe cited Home Depot’s decision to move some analytic workloads to away from Teradata and onto BigQuery (Teradata also offers a CDW and is a “strong performer” in Forrester’s Wave). Home Depot uses software from AtScale to analyze its BigQuery data.
The London-based bank HSBC is also moving risk-analysis and anti-money laundering workloads from on-premise Hadoop clusters into BigQuery. “You want to do large-scale processing and analysis, but doing it on-premise with Hadoop clusters with massive scale compute capabilities is actually wasteful, because most of the time you’re not going to use that infrastructure for analytics. So they moved to GCP.”
If the savings hold up, it’s likely we’ll see more brick-and-mortar companies move into its cloud, especially if they can translate those savings into bigger data analytics.
“The key thing is, when you’re on premise… you’re constantly thinking how do you reduce the size of data so that you don’t have to pay a lot for that infrastructure from a cost perspective,” he says. “So things the customers are able to store for only six weeks of fine-grained data or 12 weeks or 3 months — now they can store it forever.”
Related Items:
Data Warehousing with a Modern Twist
Data Warehouse Modernization and the Journey to the Cloud
Google’s BigQuery Gaining Steam As Cloud Warehouse Wars Heat Up
Editor’s note. This article has been corrected. The biggest BigQuery environment houses 250PB, not 62PB as first reported. Datanami regrets the error.
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers

















