


November 1, 2018
Inference Engine Aimed at AI Edge Apps

Flex Logix, the embedded FPGA specialist, has shifted gears by applying its proprietary interconnect technology to launch an inference engine that boosts neural inferencing capacity at the network edge while reducing DRAM bandwidth requirements.
Instead, the inferencing engine draws greater processing bandwidth from less expensive and lower-power SRAMs. That inference approach is also touted as a better way to load the neural weights used for deep learning.
Unlike current CPU, GPU and Tensor-based processors that use programmable software interconnects, the Flex Logix approach leverages its embedded FPGA architecture to provide faster programmable hardware interconnects that require lower memory bandwidth. That, the chip maker said, reduces DRAM bandwidth requirements—and fewer DRAMS translates to lower cost and less power for edge applications.
“We see the edge inferencing market as the biggest market over the next five years,” said Flex Logix CEO Geoff Tate. Among the early applications for the low-power inferencing approach are smart surveillance cameras and real-time object recognition, Tate added in an interview.
The company said this week its NMAX neural inferencing platform delivers up to 100 TOPS of peak performance using about one/tenth the “typical” DRAM bandwidth. The programmable interconnect technology is designed to address two key challenges for edge inferencing: reducing data movement and energy consumption.
Most neural processing workloads are currently handled in datacenters. Hardware specialists like Flex Logix, Mountain View, Calif., are betting that AI applications are moving to the network edge. For inferencing, that means cheaper processors and lower power consumption. Hence, Flex Logix is focusing on programmable interconnects and storing neural weights on SRAMs rather than DRAMs to help scale and move inferencing technology out of the data center.
The reconfigurable neural accelerator is based on 16-nm modular building blocks that can be snapped together to form arrays of varying sizes. Each NMAX tile consists of 512 MACs with on-chip SRAM delivering about 1 TOPS of peak performance. That’s achieved through high MAC utilization which reduces silicon cost along with lower DRAM bandwidth requirements to reduce both cost and power consumption for edge applications.
The architecture is designed to distribute SRAM bandwidth across the entire chip and arrays.
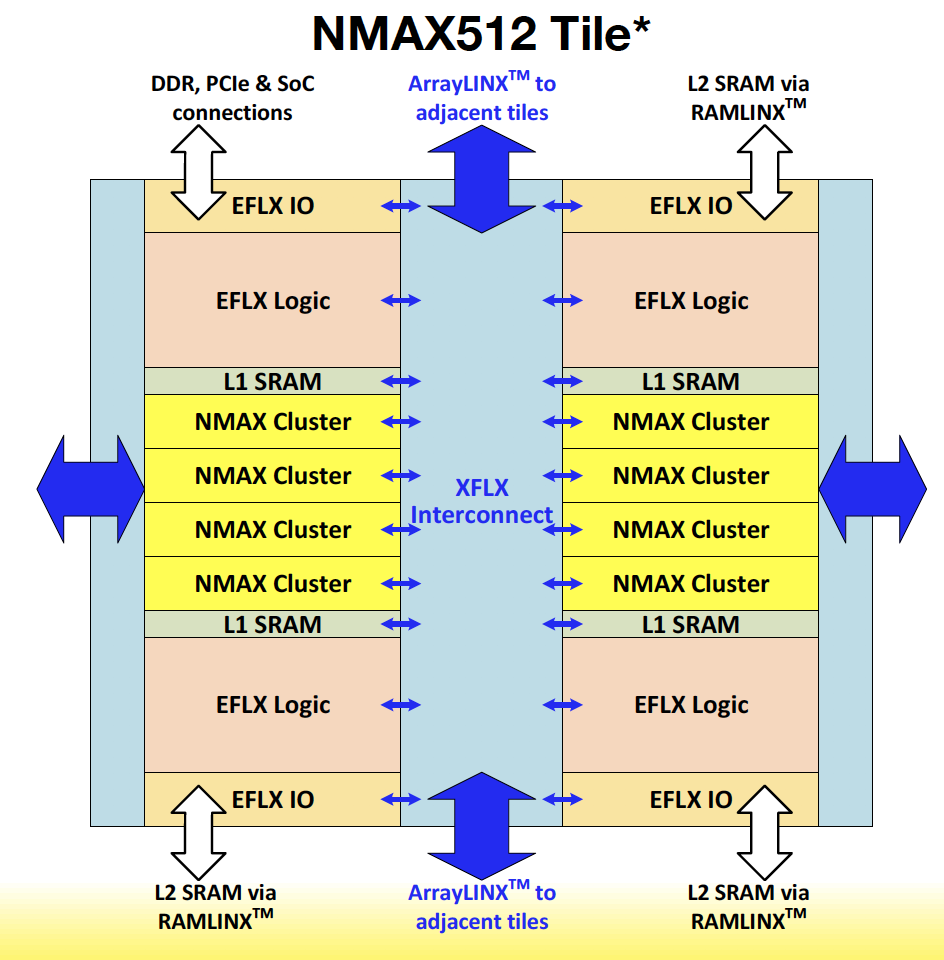
Source: Flex Logic
Tate said customers often request multiple tiles depending on the amount of on-chip SRAM needed for a specific inference model. The tiling approach was first implemented on the startup’s flagship embedded FPGAs.
Along with lower latency for edge applications, the approach is “the closest to ASIC-like performance for all reconfigurable options,” Cheng Wang, Flex Logix’s co-founder and senior vice president for engineering, told an industry chip conference this week.
Along with throughput and low latency, Tate noted that customers running neural inference engines want lower batch sizes to reduce latency as they move the technology to the edge. They also want the ability to run multiple neural networks or reconfigure existing ones. The chip maker concluded that the key was reducing DRAM bandwidth, replacing it with an interconnect approach that squeezes more bandwidth from less expensive SRAM as alternative for loading neural weights.
“Weight loading is [the customer’s] problem,” Tate said “We can run any type of neural network.”
Flex Logic said this week it expects to nail down target specifications for its neural inferencing engine such as silicon area and power requirements during the first half of 2019. The NMAX compiler also should be ready then. Tape-out of the neural processor for manufacturing is scheduled for the second half of next year.
Recent items:
Inference Emerges as Next AI Challenge
Can Markov Logic Take Machine Learning to the Next Level?
Applications:
Artificial Intelligence
Vendors:
Flex Logix
Leading Solution Providers
















