


August 7, 2018
It’s Still Early Days for Machine Learning Adoption

(kentoh/Shutterstock)
Despite the hype surrounding artificial intelligence, we’re still in the early stages of adopting machine learning in the enterprise, according to a new survey released today by O’Reilly Media. The survey also found that large-scale production deep learning rarely happens on the cloud, and that companies pursuing machine learning are actively embracing privacy, security, and fairness.
Nearly half (49%) of the 11,400+ people who took O’Reilly’s survey this June indicated they were in the exploration phase of machine learning and have not deployed any machine learning models into production. That compares to 36% of who said they were an early adopter (models in production from two to five years), while 15% considered themselves sophisticated users (models in production for more than five years).
“A lot of people are very interested in machine learning, but a lot of them are in the getting-started phase in terms of actually putting these things into productions in products and services,” O’Reilly‘s Chief Data Scientist Ben Lorica tells Datanami. “We’re very early in the machine learning adoption cycle.”

We are still in the early days of machine learning adoption, says O’Reilly Media Chief Data Scientist Ben Lorica
Looked at another way, the survey indicates that 51% companies surveyed by O’Reilly say they have been using machine learning in production for at least two years. However, these results are skewed somewhat by the sample O’Reilly used. The company sent surveys to people who had attended its Strata Data or AI conferences or consumed content in related topics through online and ecommerce channels. This self-selection bias suggests the actual machine learning adoption figures are lower in the general population [i.e. those who may not have participated in O’Reilly conferences or consumed its content].)
With this in mind, it indicates that machine learning and AI are in the process of entering the mainstream of business technology, but we may not be as far along the path as some might believe. While some companies have embraced machine learning as a core aspect of their business — including tech companies like Google, Netflix, and Uber – the actual adoption of machine learning is still relatively low in the real world.
The survey showed a correlation between the stage of adoption and the titles of data professionals on staff. More than 80% of organizations that considered themselves sophisticated users of machine learning had a data scientist, while about 50% of early adopters and organizations in the discovery phase had one or more data scientists on staff.
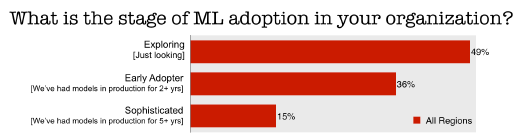
About half of respondents to an O’Reilly survey are just kicking the tires on machine learning, while half have deployed it to production (Courtesy O’Reilly Media)
Sophisticated machine learning users were twice as likely to have machine learning engineers on staff compared early adopters and organizations in the exploration phase. The disparity was even greater for deep learning engineers, a relatively new job title for engineers who work with neural networks. By comparison, early adopter organizations were more likely to have data analysts or business analysts, the survey found.
The more sophisticated machine learning users were also more likely to have a dedicated data science team compared to their less sophisticated counterparts, who were more likely to do their machine learning work in product development teams.
Surprisingly, the adoption of cloud machine learning services was low, ranging from 2% of respondents who are early adopters or sophisticated users to 4% for machine learning newbies, according to the survey.
“That’s one of the things that jumps out here. The people who are further along tend to build the models on their own,” Lorica says. “People who are using deep learning heavily tend to bring a lot of the stuff in house.”
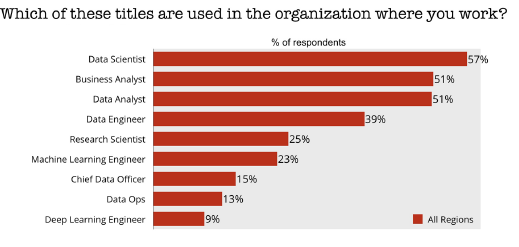
Data scientists remain popular job titles among companies pursuing machine learning (Courtesy O’Reilly Media)
Lorica says discussion with Bay Area companies confirms that once a deep learning system becomes mission critical, the company typically wants to bring that capability in-house. “For a lot of these [deep learning] models, the training set is so long, it turns out it’s more economical to do it on prem. If you’re going to do that, then you end up learning how to build the models on your own.”
Overall, North American firms lead the way in machine learning adoption, according to the survey. Eighteen percent of respondents from North America considered themselves sophisticated machine learning users, compared to 15% of folks from Western Europe, 12% from East Asia, and 11% from South Asia. More than 60% of South American firms said they were machine learning explorers, compared to 57% of Eastern Europeans and 47% of survey-takers from Oceania.
To its credit, O’Reilly Media has dedicated a significant amount of time in its conferences and content to covering topics related to the fair and unbiased application of machine learning technology. That includes O’Reilly Media founder Tim O’Reilly encouraging folks to talk to their AI “genies” at last September’s Strata Data Conference in New York.
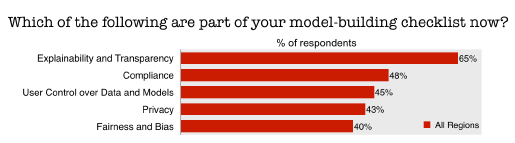
Data scientists remain popular job titles among companies pursuing machine learning (Courtesy O’Reilly Media)
To that end, O’Reilly was rewarded when a good cross-section of respondents indicated they have taken the advice to heart. According to the survey, 65% of respondents indicated that explainability and transparency are part of their model-building checklist, compared to 48% for compliance and 45% for ensuring user control over data and models. Privacy is on the minds of 43%, while 40% indicate fairness and bias are on the checklist.
Lorica says these awareness of these issues is increasing as organizations become more sophisticated with their machine learning activities.
“Even at this stage where people are really starting to engage in machine learning, they’re starting to realize that in order to productionalize machine learning, there are other considerations beyond business metrics and machine learning metrics,” he says. “Those considerations are privacy and security, fairness and bias.”
You can download a copy of O’Reilly’s ebook that contains the survey results, titled “The State of Machine Learning Adoption in the Enterprise,” at this link.
Related Items:
How To Build a Data Science Team Now
Which Machine Learning Platform Performs Best?
5 Reasons Data Science Initiatives Fail
Technologies:
Frameworks
Vendors:
O'Reilly Media
Leading Solution Providers
















