



June 5, 2018
Databricks Open Sources MLflow to Simplify Machine Learning Lifecycle
Databricks today unveiled MLflow, a new open source project that aims to provide some standardization to the complex processes that data scientists oversee during the course of building, testing, and deploying machine learning models.
“Everybody who has done machine learning knows that the machine learning development lifecycle is very complex,” Apache Spark creator and Databricks CTO Matei Zaharia said during his keynote address at Databricks’ Spark and AI Summit in San Francisco. “There are a lot of issues that come up that you don’t have in normal software development lifecycle.”
The vast volumes of data, together with the abundance of machine learning frameworks, the large scale of production systems, and the distributed nature of data science and engineering teams, combine to provide a huge number of variables to control in the machine learning DevOps lifecycle — and that even before the tuning.
“They have all these tuning parameters that you have to change and explore to get a good model,” Zaharia said. “This basically adds new dimensions to the whole problem, where you now you have many versions of your [model] with different parameters and you have to understand what happens with your results on each one.”
The Web giants have built data science platforms that provide some control over the process and alleviate some of the risk and concerns of having models go off the rails. Zaharia pointed out Facebook’s FBLearner Flow, Google’s TFX, and Uber’s Michelangelo as examples.
“These are platforms that standardize the data for training and deployment loop,” he said. “As long as you work within the platform, if you build the models using the tools provided there, you can deploy it, you can productionalize it, you can monitor it and so on. So it saves these companies a lot of time.”

Databricks CTO Matei Zaharia is the creator of MLflow
But Zaharia says there are limitations to these platforms that make them less than ideal. “First of all they’re often limited to a few algorithms or frameworks,” he said. “Whatever the machine learning platform team at your company put in, that’s what you get to use, and if you want to use something else, you’re on your own.” They’re also limited to running on the company’s infrastructure, which limits the capability to share code.
Zaharia said the Databricks team started looking at this problem about a year ago. The ideas centered around “how can we provide similar benefits to these platforms, but in an open manner — open not only in sense of open source but also in the sense that you can use any tool and algorithm with it and potentially share them across organization if you want to.”
The result is MLflow, a new open source project unveiled today by Databricks. MLflow helps data scientists by automating a range of data science activities that are occurring across machine learning frameworks, including tracking, packaging, and managing models, no matter what machine learning framework is used.
“It basically helps you move between data prep, building models, and deploying models,” said Databricks co-founder and CEO Ali Ghodsi during his keynote. “It makes reproduce-ability really easy for all these frameworks that are out there.”
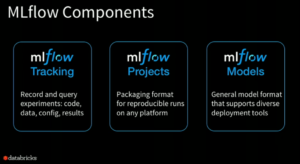
MLflow includes three sub-projects now: MLflow Tracking, MLFlow Projects, and MLflow Models.
- Tracking is an API that allows users to record and play back experiments, Zaharia said. “So you don’t have to ever lose track of what went into getting a specific result or model,” he said. “You can use this anywhere to record results.”
- Projects is a packaging format designed to provide reproducibility across different platforms. “So you can actually run the same code on any platform and get your result back from it,” he said.
- Models provides, a “general model format” that supports diverse deployment tools, he said.
The project, which is hosted at GitHub, is intended to remain an open source project. To that end, it sports REST APIs and simple data formats that can be used with a variety of tools. Databricks will also be offering a hosted version of MLflow that integrates with its Unified Analytics Platform, Zaharia wrote in his blog post on MLflow.
The company, which is hosting 4,000 people at its Spark+AI Summit this week, made several other machine learning-related announcements, including the general availability of Databricks Runtime for ML, which provides a pre-configured environment for frameworks like TensorFlow, Keras and others, and Project Hydrogen, which eliminates incompatibilities between the Apache Spark scheduler and the scheduling paradigms of deep learning frameworks.
Databricks also announced the general availability of Databricks Delta, the new data cleansing mechanism that runs in the company’s cloud and was originally unveiled last October.
Delta sits between incoming data streams like Kinesis or Kafka and Databrick’s Spark-based runtime. As data streams in, Delta cleanses the data transformations written in Scala, Java, Python, or R. Once the data is transformed, it’s stored in the Parquet format and made immediately available for SQL style processing, machine learning, and streaming analytics.
Related Items:
Project Hydrogen Unites Apache Spark with DL Frameworks
Top 3 New Features in Apache Spark 2.3
Databricks Puts ‘Delta’ at the Confluence of Lakes, Streams, and Warehouses
Leading Solution Providers
















