


May 10, 2018
IBM Bolsters Storage with AI, De-Dupe, and Cloud DR

(sdecoret/Shutterstock)
Organizations today are struggling to keep up with the massive amount of data they’re generating and collecting, and in some cases they’re close to maxing out their existing storage. In a way it’s good news for storage providers, but IBM says it wants to help customers by taking a smart approach to minimizing their data and maximizing their storage investment.
IBM made several announcements today that should help customers get more out of their existing storage infrastructure, including IBM systems like the Storwize and FlashSystem arrays, the SAN Volume Controller (SVC) software-defined storage product, and even non-IBM arrays from Dell EMC and HPE that IBM storage software manages through its VersaStack program.
Let’s start with data de-duplication. For years IBM has offered de-dupe in its high-end FlashSystem A9000 array. Now it’s tweaked that de-dupe code so it can run on IBM’s Storwize, SVC, FlashSystem V9000, and the 440 external storage systems it supports via VersaStack.
It’s the first time IBM is providing de-dupe on those products, although it previously supported other data reduction techniques on them, including compression, thin provisioning, compaction, and SCSI unmap (which reclaims storage resources on arrays when virtual machines disconnect from them). Taken together, these five data reduction techniques can deliver up to a five-to-one reduction in the amount of raw data that organizations are storing on their IBM systems, IBM claims.
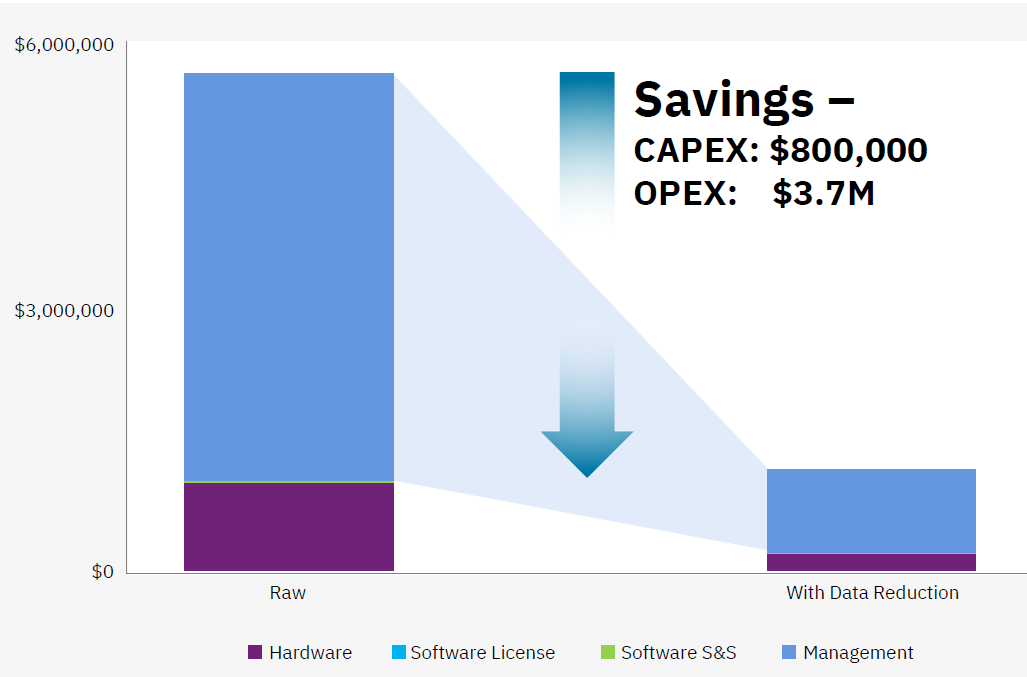
IBM is guaranteeing customers can cut storage requirements by least 2x and up to 5x
Reduced storage requirements translate into big savings for customers. IBM says a five-to-one reduction in data can save a client that storing 700TB across 7.7TB flash drives in a Storwize V7000F $3.7 million in operating expenditures (opex) and $800,000 in capital expenditures (capex) over the course of three years. That big savings on big data can’t be ignored.
“Storage analysts, depending on who you talk to, say the cost to manage 1TB of storage runs to $1,500 to $2,100 per year per terabyte,” says Eric Herzog, chief marketing officer and VP of worldwide storage channels for IBM’s Storage and Software Defined Infrastructure. “So if you don’t have to buy as many terabytes, guess what? You reduce your capex as well.”
IBM is so confident that its big data reduction capabilities can save customers big money that it’s making a big guarantee about it.
“We don’t care if you only do de-dupe or only do compression or do combination — the bottom line is you have data reductions guarantees,” Herzog he tells Datanami. “You can get up to five-to-one, which we can guarantee.” (Customers will have to submit to a data analysis to get the five-to-one guarantee; IBM is guaranteeing at least a two-to-one reduction without the data analysis.)
IBM also hopes to reduce the amount of money customers spend on storage through its new Storage Insights offering, which uses Watson-based artificial intelligence and machine learning capabilities to optimize storage requirements for customers’ specific workloads, provide capacity planning capabilities, and otherwise optimize the storage environment.
“The value is how to make sure you don’t overbuy,” Herzog says. “You’ll be able to see the patterns and see what your historical use is so you can predictably look forward.”
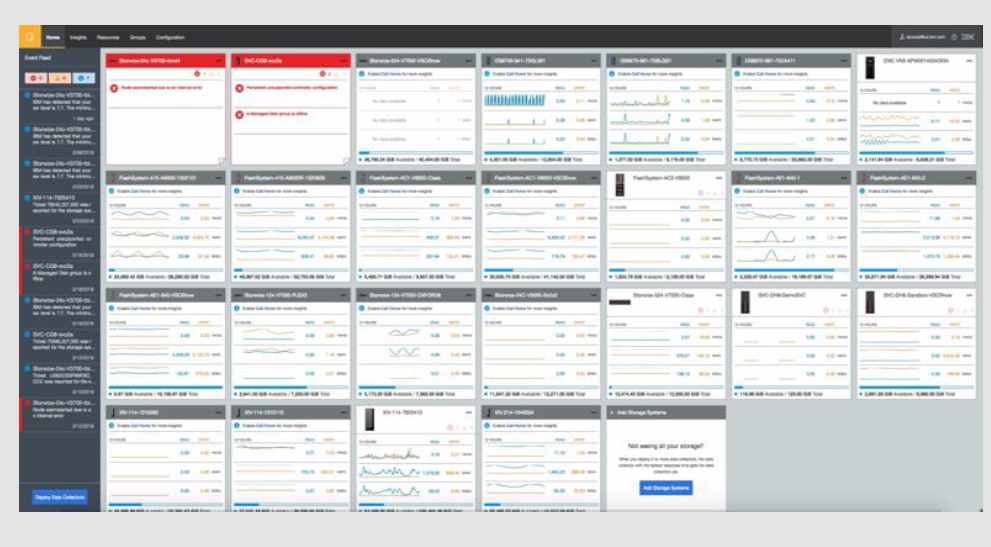
Storage Insights features a Web-based GUI where users can view storage recommendations made by IBM Watson-based AI models
Storage Insights works by collecting storage usage data information and statistics from a wide range of IBM storage customers and uploading them into the IBM cloud, where machine learning algorithms analyze the data to discover storage patterns surrounding certain application workloads. It then exposes the results of that data analysis to subscribers, who can see what the optimal settings are for specific workloads on specific gear across several variables, such as maximum performance or lowest price.
“Let’s say 100,000 different boxes use Storage Insights,” Herzog says. “We’ll gather all kinds of best practices. We can see using AI… the best configuration for an Oracle workloads seems to be like this on a Storwize box. You as an end user can take advantage of that…You can go in and use the AI tool and it will come back and say ‘Here’s the best way to configure your performance in Oracle or Hadoop or Mongo or SAP…..If I want to save money using tiering, how do I do that?'”

Spectrum Virtualize for Public Clouds eliminates the need to buy matching pairs of storage gear for replication, and also lets users use the IBM cloud for DR
IBM offers two versions of Storage Insights, including a free version and a paid version called Storage Insights Pro. The paid version provides more configurability, advanced metrics, and the capability to hold up to two years of data (the free version supports only 24 hours of data). The pro version, which costs $257 per month per 50 TB block, also includes analytics and optimizations, including best practices violation, customizable alerting, business impact analysis, and others.
The last major announcement made by IBM today is an expansion of Spectrum Virtualize for Public Cloud. This offering makes it easier for Spectrum Virtualize users – which could be running Storwize, SVC, FlashSystem V9000, or any of the 440 VersaStack systems — to have a fully replicated copy of their production storage infrastructure running either in IBM’s cloud or the client’s DR site.
Herzog explains: “In traditional replication, if I have Storwize box on the primary site, I need to put Storwize box on secondary box,” he says. “In this case, with Spectrum Virtualize for Public Cloud, you can use whatever storage you’ve got at your DR site. It can be ours. It can be competitors. It can be Intel storage in your server. It doesn’t matter to us. It looks like Storwize box. Or it looks like EMC DMX even if the DR site doesn’t have EMC DMX. The value there is not have to buy a duplicate copy of your storage of the exact same manufacturer on your DR site.”
With today’s announcement, scalability for Spectrum Virtualize for Public Cloud doubles, from two 2-node pairs to two 4-node pairs. That translates to better throughput, lower networking charges, and better CPU utilization on the production system. “We made it less impactful on the primary application you’re running,” Herzog says. “Usually your replicating while still working because most companies runs 24 hours these days.”
Related Items:
How Erasure Coding Changes Hadoop Storage Economics
IBM Challenges Amazon S3 with Cloud Object Store
Leading Solution Providers

















