


April 30, 2018
How Netflix Optimized Flink for Massive Scale on AWS

(Sitthiphong/Shutterstock)
When it comes to streaming data, it’s tough to find a company operating on a more massive scale than Netflix, which streams more than 125 million hours of TV shows and movies — per day. Netflix captures billions of pieces data about those viewing sessions and routes it into various analytic engines using Apache Flink. However, some additional work was required to get it all working smoothly and efficiently at scale in the AWS cloud.
Netflix is no stranger to big data tech. The company has been an eager adopter of Hadoop, NoSQL, and related projects for years, and has done pioneering work in optimizing the technologies to run in public cloud platforms. Netflix runs everything in AWS, its primary cloud platform, while it keeps some VMs in standby on the Google Cloud Platform as the backup.
Lately the company has been working on its real-time stream processing system, which it uses to drive various applications to improve personalization, provide operational insight, and detect fraud. A core component of its stream processing system is something called the Keystone data pipeline, which is used to move upwards of 12PB of data per day into its S3 data warehouse, where 100PB of highly compressed data reside.
Netflix recently migrated the Keystone data pipeline from the Apache Samza framework to Apache Flink, an open source stream processing platform backed by data Artisans. Like any platform migration, the switchover wasn’t completely without any hiccups. In Netflix’s case, the company ran into challenges surrounding how Flink scales on AWS. Earlier this month, at data Artisans’ Flink Forward conference in San Francisco, Netflix senior software engineer Steve Wu shared tips about how the company overcame scalability challenges.
Some of the tricks Netflix used to ensure Flink runs efficiently on AWS at massive scale are quite clever, and reflect the deep experience that Netflix has running big data apps in the cloud. The problem seem to stem from the nature of S3, which has several characteristics in regards to refresh rate, file size, and latency that are not optimal for running a streaming data pipeline at massive scale.
For example, with regards to refresh rate, who would have thought that changing the prefix in the log file would have an impact on scalability? It turns out that when AWS encounters sequential names is a series of files – such as how Flink and arguably most other real-time streaming systems do – AWS will try to store them on the same cluster. However, storing pieces of data on the same cluster eliminates the scalability and throughput advantages that having a massive distributed infrastructure such as AWS entails.
“If you use sequential key names, S3 might tuck it into one specific location, so your transactions will slow down,” Wu says. “That’s why we avoid sequential key names.” The solution to the sequential file name problem is relatively simple, Wu says. By inserting randomness into the file names in the form of a 4-charcter hexadecimal string, Netflix can trick AWS into automatically distributing the files evenly across the available clusters.
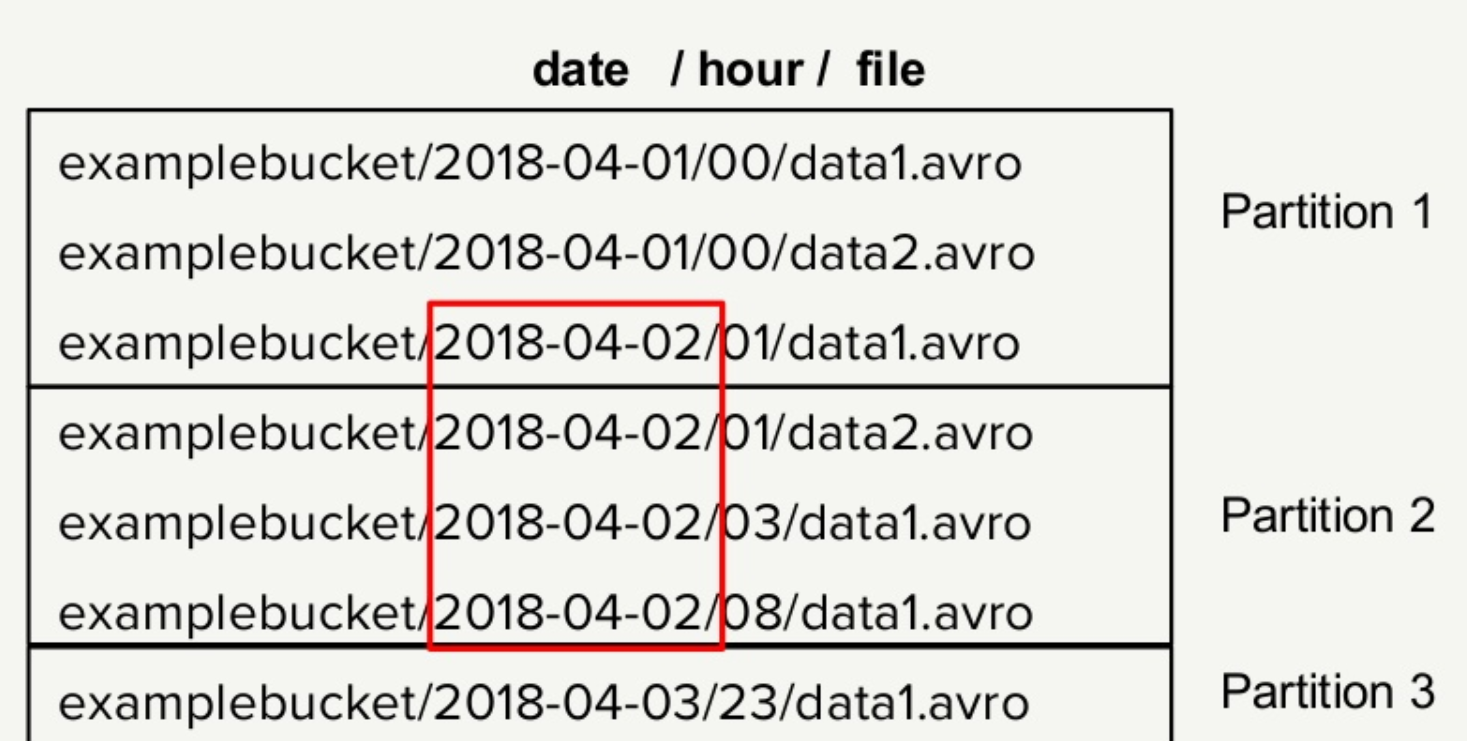
Netflix added randomness to file names to force AWS to distribute file storage (Source: Netflix)
The small-file problem also triggered some engineering work at Netflix. This one involved the Keystone Router, a key piece of software that distribute the 3 trillion events per day across 2,000 routing jobs and 200,000 parallel operators to other data sinks in Netflix’s S3 repository, including Hive, Elasticsearch, and a Kafka consumer.
After each checkpoint operation, the Flink operator takes a snapshot of the state and sends it to S3, which is how Flink keeps a globally consistent view despite the asynchronous nature of the operations, Wu says. “The problem is we have so many operators writing small S3 files,” he says. “That’s not an ideal way for S3 [to work]. It’s not optimized for small files.”
A solution was found in a Flink feature called memory threshold. If the size of the state snapshot file is smaller than the memory threshold, the Flink operator will automatically send the state information in the acknowledgement message, as opposed to sending a separate message with the state data. By change the memory threshold default from 1KB to 1MB, Netflix was able to force the job manager to gather all the state acknowledgements from other operators, and then sync it up at that point with one big “uber” checkpoint file. “So operators don’t write to state any more,” Wu says. “Only job manager writes to S3.”
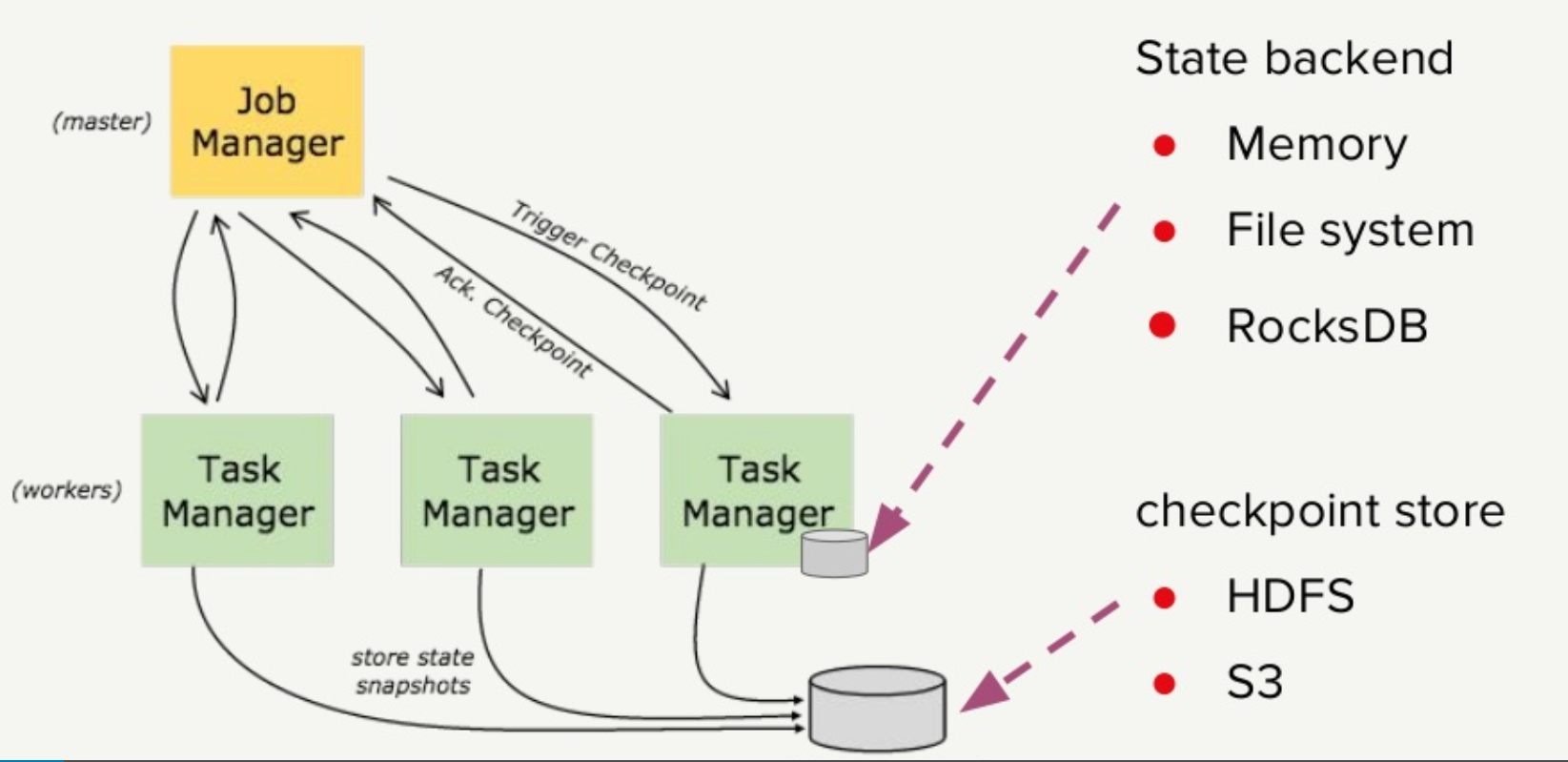
Netflix worked with Flink to address chatty checkpoint connections to HDFS and S3 (Source: Netflix)
On the latency front, the Netflix data engineering team discovered another odd occurrence that was helping to run up its AWS bill. As Wu explains, when the Flink operators in the Keystone Router made a metadata request, it would pass two paths. One of the requests had a slash at the end of the pathname, and one did not a slash. The extra slash was needed to ensure compatibility with HDFS, which still plays a useful role for Netflix. “This problem was tolerable to us, so we didn’t bother to fix it,” Wu says.
However, there was another cost: Half of the jobs ended without any S3 files being written at the end of the pipeline, since the path was either using HDFS or not. With 200,000 operators and a checkpoint interval of 30 seconds, Wu calculated that 13,000 metadata requests were being sent from task managers without writing any S3 files. “So that was a complete waste,” Wu says. “Although metadata requests are pretty cheap they still count against request volume.”
The solution entailed Netflix working with Flink to make a change in Flink, which was actually implemented in Flink version 1.2.1. The change involved having the Checkpoint Stream Factory called only once when the operator is first initialized, instead of every 30 seconds. “Hopefully you’re running on a Flink version more than this and you will not run into the same problem,” Wu says.
data Artisans has posted all the videos and slides from its two-day Flink Forward event on its website: https://data-artisans.com/flink-forward-san-francisco-2018.
Related Items:
Flink Aims to Simplify Stream Processing
Top 10 Netflix Tips on Going Cloud-Native with Hadoop
Apache Flink Takes Its Own Route to Distributed Data Processing
Applications:
Complex Event Processing
Sectors:
Retail
Leading Solution Providers
















