


March 16, 2018
IBM Launches New Cloud for Data Science and Engineering
IBM today unveiled a new cloud offering called Cloud Private Data that’s designed to help organizations utilize data science and machine learning techniques to generate insight from data, and then engineer AI products that put those insights into use. Separately, Big Blue announced the creation of a new consulting group dubbed the Data Science Elite Team.
IBM describes its new Cloud Private for Data offering as an “integrated data science, data engineering, and app building platform” that will eventually be available across all clouds. The offering is designed to help users with a broad swath of data science activities, from collecting, cleaning, and cataloging data, to using machine learning algorithms to build models, and finally to putting them into production.
The Cloud Private for Data borrows technology from various other IBM products, most prominently Data Science Experience, the Apache-Spark-based offering it launched in 2016 that allows data scientists to develop and iterate on models using R, Python, and Scale within a Jupyter notebook environment. Beyond that, the software includes IBM’s Information Analyzer, Information Governance Catalogue, Data Stage, Db2, and Db2 Warehouse products.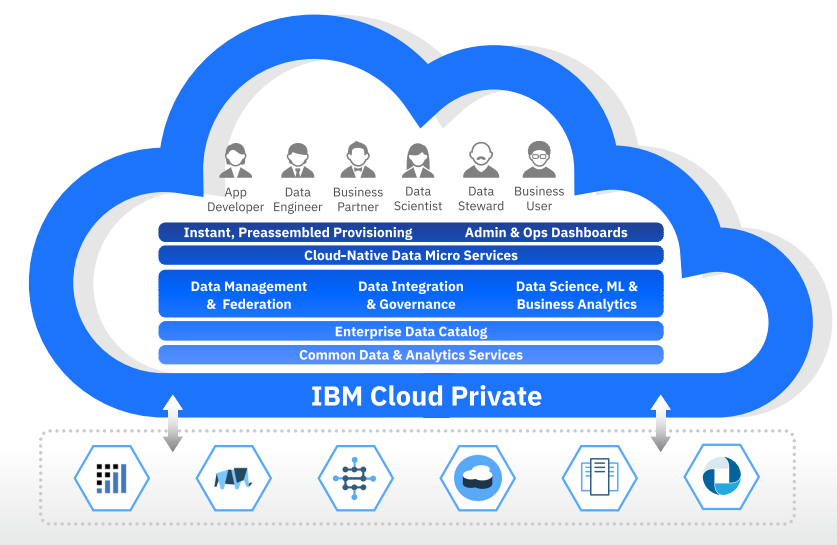
“Cloud Private for Data is an engineered solution for doing data science, data engineering and application building, with no assembly required,” says Rob Thomas, IBM’s general manager for analytics, in a blog post today. “As an aspiring data scientist, anyone can find relevant data, do ad-hoc analysis, build models, and deploy them into production, within a single integrated experience.”
In videos posted to IBM’s Cloud Private for Data webpage, the IT giant shows how the software can be used. From the comfort of a GUI, the user is able to search for various data sets across cloud, on-premise and Hadoop sources; preview and transform the data using machine learning-powered techniques; develop a model in an integrated notebook-style code editor; and then put the model into production by publishing it.
The Cloud Private for Data offering can be deployed “in minutes” using Kubernetes containerization technology, IBM says in its press release, while the use of microservices helps it to “form a truly integrated environment for data science and application development.” IBM says the software is suitable for analyzing data form event-driven applications, such as those that use IoT sensors, online commerce, and mobile devices.
While it’s only offered on IBM’s cloud today, it will run on all clouds in the future. IBM also plans to offer industry-specific versions of it for customers in the financial services, healthcare, and manufacturing industries.
IBM also announced the creation of a new Data Science Elite Team to help customers with their big data analytics and data science endeavors.

Some of the members of IBM’s new Data Science Elite Team: (L-R) Annamaria Balazs, Umit Cakmak, Seth Dobrin, Susara van den Heever, Wendy Won, and Siva Anne. (Photo: Mike Webb Photography) (PRNewsfoto/IBM)
Described as a “global team of data scientists, machine learning engineers, and decision optimization engineers,” the Data Science Elite Team was assembled to help clients with particularly use cases. Engagements typically start with a “discovery workshop,” where three to four “discrete deliverables” are identified, with the goal of delivering them in two to three weeks.
Thirty people currently are on the Data Science Elite Team, and IBM plans to grow the team to 200 over the next few years. Even though it was just publically launched today, IBM says the team is already helping more than 50 organizations.
One of the first customers to avail itself to IBM’s Data Science Elite Team services was Nedbank, one of South Africa’s biggest banks. The banks Chief Data Officer, Patricia Maqetuka, says the Elite Team “helped us to unlock new paradigms about how we think about our analytics and change the way we look at use cases to unlock business value.”
Related Items:
What Kind of Data Scientist Are You?
Why 2018 Will Be The Year Of The Data Engineer
IBM Seeks Data Science Unity with New Spark-Based ‘Experience’
Leading Solution Providers
















