


February 21, 2018
ParallelM Aims to Close the Gap in ML Operationalization

A startup named ParallelM today unveiled new software aimed at alleviating data scientists from the burden of manually deploying, monitoring, and managing machine learning pipelines in production.
Dubbed MLOps, ParallelM‘s software helps to automate many of the operational tasks required to turn a machine learning model from a promising piece of code running nn Spark, Flink, TensorFlow, or PyTorch processing engines into a secure, governed, and production-ready machine learning system.
“The main thing that we solve is the whole operational aspect of the story,” says Yoav Banin, a strategic adviser to ParallelM. “On the one hand, you have data science people focused on building models, but they don’t have the ops mentality of what does it take to scale this model, to guarantee reliability, to ensure security, to keep things updated, to make sure things don’t break. And the ops people don’t really have familiarly with machine learning as of yet, so there’s a bit of a disconnect…We think of it as the last mile to AI.”
While many businesses are looking to ML and AI technologies and technique to gain a competitive edge, only a small fraction of them have successfully moved systems into production. The company cites statistics from McKinsey Global Institute that shows only 12% of a group of 3,000 “AI-aware CEOs” report their organizations have moved ML or AI technologies beyond the experimental stage.
“There’s an executive mandate that we’re hearing, where companies say we have one or two [ML applications] in production, but we want to push it out to 10 or 100 or more,” Banin tells Datanami. “You just can’t do that with the tools and processes that are in place….It’s very hard to keep track of all this stuff.”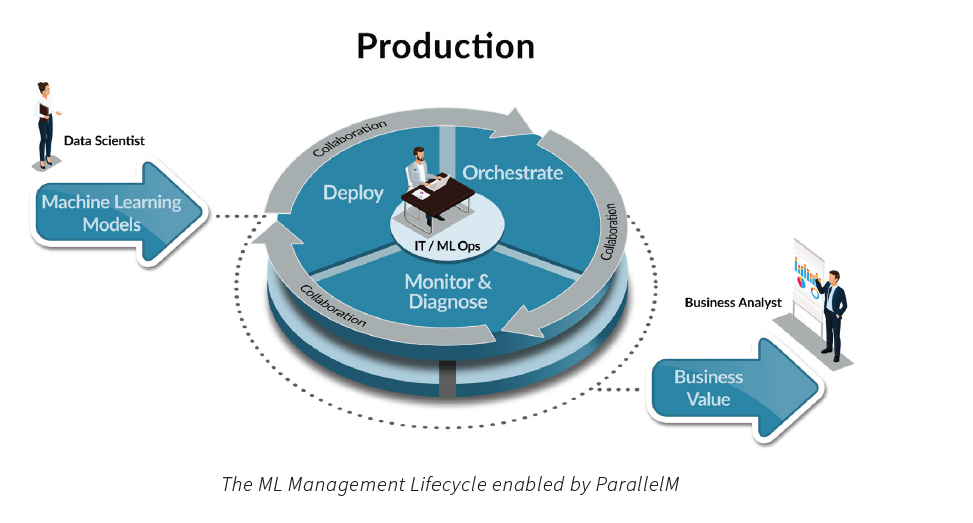
ParallelM is betting that MLOps will resonate with organizations that want to get out of the business of doing all the manual tasks that are required to keep ML and AI applications afloat in a changing world. To that end, the software brings specific capabilities, including:
- Ingestion of ML models via PMML or via connectors to DataRobot, Dataiku, and H2O data science platforms;
- ML model lineage and provenance, including tracking of who configured and approvals the models;
- Centralized policy-based management of production and training ML models via its ION framework;
- Deployment of ML models to distributed compute resources;
- Monitoring of ML health indicators to spot divergence between results of training models and results of production inference models;
- Sandboxing of models for AB testing, including management of “canary” models to monitor for changes in real-world conditions;
- Snapshotting of ML model and data states for later analyses; and
- A central dashboard for monitoring ML activities.
When MLOps is put into action, it handles a range of tasks, Banin explains, including “keeping all the pipelines up to date, including orchestrating the updating between training pipelines and inference pipelines; tracking the health and validation of your ML predictions; doing ML governance to track all configuration and parameters over time; monitoring diagnostics; and being able to correlate predictions or outputs from your ML algorithms to business results.”

The MLOps dashboard keeps users apprised of ML pipeline activity
In most shops doing ML, data scientists have been the ones tasks with keeping the ML models up and running after they were initially created, even though that’s not really their strength, Banin says. Many of the most advanced shops have cobbled together their own collection of tools for managing ML operations, including scripting tools and Excel, he says, but it’s far from optimal. The less advanced shops get by with less.
“A gaming company came to us saying ‘Here are all 20 steps we do to manage ML. How do I swap out my tools and things that I cobbled together, because I don’t want to maintain that anymore, it’s not fundamental to my business, and use yours instead,'” Banin says.
Even though the product is just launching today, ParallelM, which is headquartered in Sunnyvale, California and also has offices in Tel Aviv, Israel, has a handful of customers already.
One of those is Clearsense, a Florida-based healthcare analytics startup that uses a variety of big data technology, including Hortonworks Hadoop stack, to ingest, normalize, and analyze a variety of data feeds in hospital settings to improve patient care. (You can read our May 2017 case study on Clearsense to learn more).
Charles Boicey, Chief Innovation Officer at Clearsense, says MLOps is similar to the theoretical framework that the company has been discussing internally, which made the decision to buy it a relatively easy one. “I believe that ParallelM will not only be of value to Clearsense, but also to the healthcare industry as a whole,” Boicey says in a press release. “Many of the organizations that have adopted Hadoop and other big data technologies could use ParallelM’s help as they implement and scale their data science programs.”![]()
An ad tech company is using MLOps to manage the array of ML pipelines it uses to optimize ad spending for customers. Banin says managing the roll-out of ML models was a complex and error prone process. “They’ll roll out the model to a few of the lower value customer first, and they’ll watch it for a while and make sure everything is OK,” he says. “Then they’ll roll it out to a few more. That process can take weeks and months and you still have the risk of ML blowing up.
For this specific company, the cost of having an ML model generate the wrong predictions would cost clients $20,000 per hour in misallocated ad spend, Banin says.
“There’s this implementation risk around ML where if the predations go wrong or if they go stale because production data is diverging from data upon which the model was trained, then your predictions start to go bad and you can have very serious business consequences,” he says.
Related Items:
Why Getting the Metrics Right Is So Important in Machine Learning
How Big Data Can Save Lives at the Hospital
Leading Solution Providers
















