


February 13, 2018
Scylla Eyes Cassandra’s NoSQL Workloads
If imitation is the sincerest form of flattery, then the folks behind the Apache Cassandra project would probably be pleased with Scylla, a C++-based rewrite of Cassandra that’s starting to make waves. But considering how serious the folks at ScyllaDB are about stealing Cassandra’s thunder, there’s likely no joy in Cassandra world.
The genesis story of Scylla is an unlikely one. About five years ago, Dor Laor and Avi Kivity, two key figures in the development of the KVM hypervisor at Red Hat, left the Linux distributor to found a startup named Cloudius with the ambitious plan to build a “unikernal” that would be a better and more efficient implementation of the Linux OS to power workloads in cloud data centers.
At some point, the pair decided that plan wasn’t panning out, so they looked for other areas where their system engineering talents could be applied. One potential target was Hadoop. The distributed platform was growing more popular by the month, and Laor and Kivity thought a non-Java implementation could grab the market’s attention. But when MapR Technologies rewrote large parts of Hadoop, including the Hadoop Distributed File System (HDFS), in C, they decided Hadoop wasn’t in their future.
So the pair started investigating NoSQL databases – specifically Cassandra, the enormously popular open source database that came out of Facebook just about the same time Hadoop emerged from Yahoo. The more they looked at Cassandra, they more they thought it could use a little sprucing up.
“Cassandra was one of the workloads that we wanted to run on our unikernal,” Laor says. “This is where we learned about the pros and cons of Cassandra and we decided to rewrite it from scratch.”
Rethinking Cassandra
Cloudius changed its name to ScyllaDB, and for the past three and a half years, Laor and his colleagues have been working to develop what’s essentially a Cassandra clone. However, while Scylla is wire compatible with Cassandra and is what the company calls a “drop-in replacement” for it, there are big differences between Cassandra and Scylla designs.
Laor tells Datanami that Scylla’s goal was to keep the good parts of Cassandra while casting out the parts they considered less than ideal.

Dor Laor is CEO and founder of ScyllaDB
“We noticed that Cassandra overall has a very good design,” he says. “It’s not a surprise. It’s a mature product and it relies on Dynamo and BigTable. A very strong foundation. But — and there’s a big but – the implementation has a lot of flaws in it.”
The first flaw that ScyllaDB sought to address was Cassandra’s use of Java, including the Java Virtual Machine (JVM) and how its garbage collection routines for clearing up memory. “Java is a terrific language for management application, not for high speed I/O,” Laor says. “It’s definitely bad for high speed I/O. It’s bad in terms of efficiency, it’s bad in terms of control. It’s even bad in terms of manageability, because it’s just a nightmare to tune Java.”
Cassandra is renowned for its capability to scale out to store a huge amount of data. In fact, Cassandra is widely considered to be the best-scaling NoSQL database in existence. But the folks behind Scylla think they have improved upon Cassandra’s scalability story.
“Cassandra is the best highly available distributed platform,” Laor says. “No one else can get 1,000 nodes. I don’t even hear anybody claim they can get to this scale… The nice thing is all the nodes are homogenous. So you just add more nodes and the cluster merges them automatically. There’s no need to reshard the data, no need to restart the database when the database either grows or shrinks. That’s super crucial.”
Cassandra’s support for multi-data center replication is also top-notch in the database world. “Replication is amazingly flexible,” Laor says. ” You can determine how many local replications do you have, any number from one to 10 or higher. You can have any number of data centers.” Cassandra’s integration with other big data technologies, such as Spark, Presto, and even graph database engines completed the picture.
“So it [Cassandra] is quite good,” Laor concedes. “But the problems are, it’s very costly. You’ll be running way more nodes than what you expect. And you pay a lot, especially on public clouds.”
Total Overhaul
ScyllaDB sought to develop a database that captured all of Cassandra’s upside while eliminating the downsides. The first move was ditching Java and rewriting it in C++.
“C++ is the right tool for the job,” Laor says. “It’s a more efficient language and it also allows you better control, because in Java you cannot control all of the aspects of the operating system….”
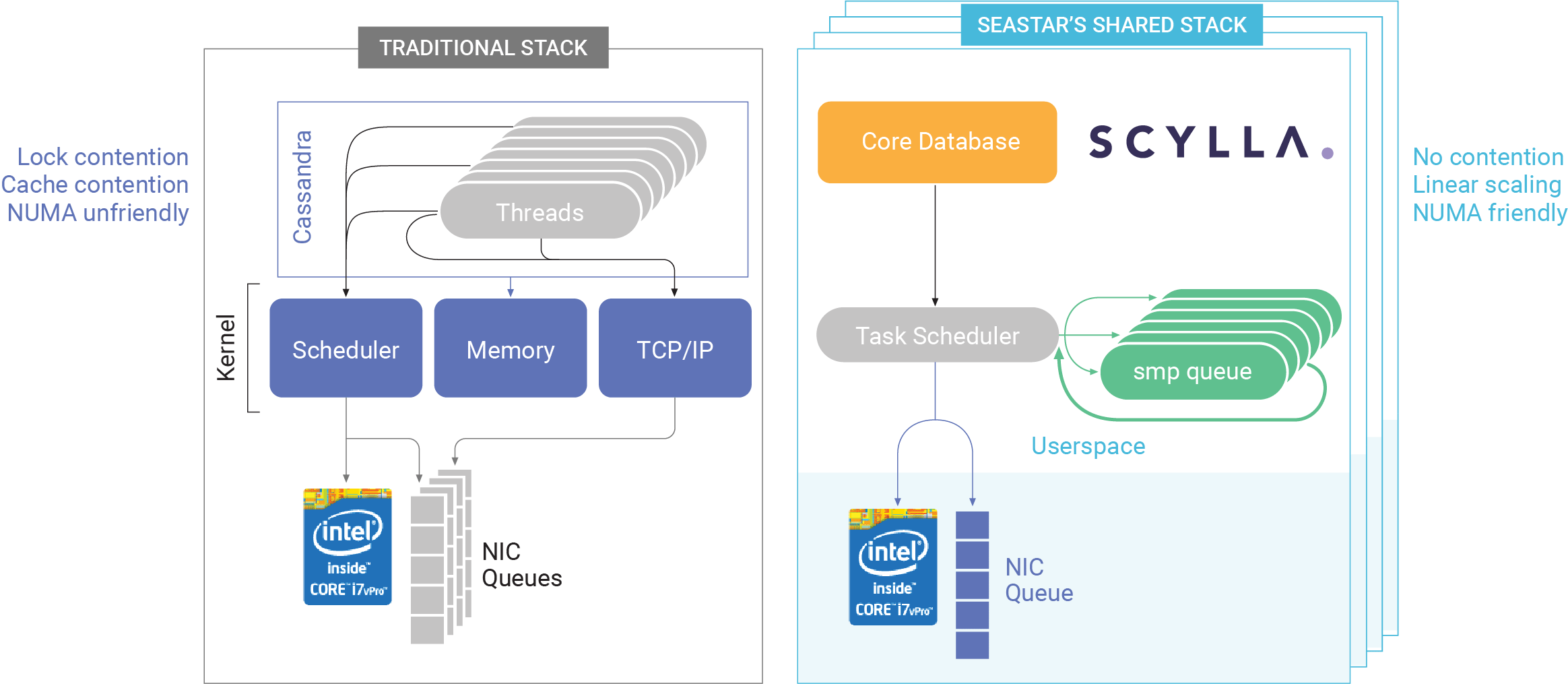
Scylla architecture compared to Cassandra (Image source: ScyllaDB)
The second major redesign consideration involved how Scylla would shard data. “We have two levels of sharding,” Laor says. “The first level of sharding is identical to Casandra, cluster-level sharding…. Our improvement is that, within every server, we have another level of sharding.”
In Scylla, every processor core has its own shard. “The idea is, those internal shards will have a shared-nothing design, so each one is independent,” Laor says. “It owns its data and never needs to lock anything. Locks on modern CPUs are very expensive.”
ScyllaDB’s implementation of one-shard-per-core doesn’t raise the complexity level because it’s automatically shielded from the user, Laor says. (In fact, the sharding and the locks are handled by Seastar, the database engine at the heart of Scylla, which is also its own, separate open source project.) But this approach is critical for allowing the database to scale easily to achieve higher I/O, he says.
“We always scale the CPU and the memory together in the shard, so access to the memory is always NUMA local,” he says. “We always access the memory that resides on the same socket. If you access memory on neighboring sockets, on a two-socket machine, then you pay a penalty of 2x accessing that memory.”
The engineers also developed their own task scheduler, including a CPU scheduler and an I/O scheduler, to make sure that it optimized these resources. The list goes on and on.
“We also wrote our own memory allocation library because we cannot even use the regular system calls because they have locks and it’s not good for us,” Laor says. “So we pretty much had to write a lot of mechanisms to support the extreme design that we took in order that everything would work out of the box with good performance under any circumstances.”
Real World Performance
By rewriting the innards of Cassandra in C++ and rethinking Cassandra’s approach to sharding, ScyllaDB aimed to improve the throughput, latency, scalability, and ability to tune the popular NoSQL database. While Scylla isn’t a household name (few databases ever are), it appears to be turning some heads in the industry.
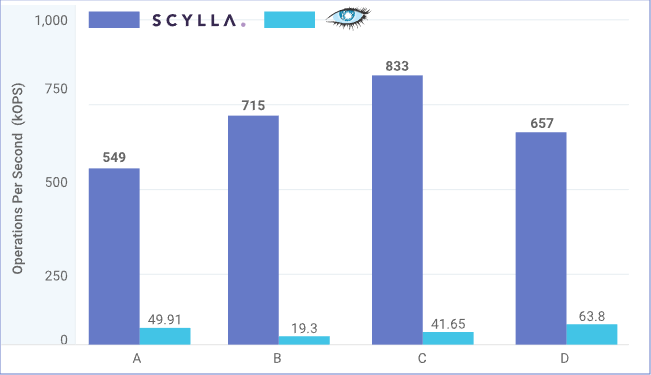
A Samsung Benchmark shows throughput of Scylla vs Cassandra using 2TB of data for different YCSB workloads
The company claims that Scylla can handle 1 million read/write operations per second, which it says is a 10x improvement over Cassandra. It can do this while maintaining low latencies – in some cases as low as a millisecond for database operations. ScyllaDB compared its database against Cassandra on the Yahoo cloud serving benchmark and found that a three-node Scylla cluster had the same throughput as a 30-node Cassandra cluster.
Scylla also runs on IBM Power, where it can take advantage of higher memory I/O density and more threads per core to scale up the throughput while minimizing the server footprint. The company also worked with Qualcomm to port Scylla to ARM, another dense node-count design.
“The nice thing is we can utilize all of these cores and provide better throughput,” Laor says. “Not only are we more efficient than Cassandra, we can utilize larger boxes. There’s no need to provision 100 or 1,000 nodes — you can just provision 10 nodes.”
Scylla has started to gain some real-world traction, including in the ad tech business, recommendation engines, and mobile applications. Samsung is a customer, as are IBM, Music.ly, Outbrain, AdGear, and Zen.ly. CERN, the Los Alamos National Laboratory, and the Swiss Army are also users. (While the Scylla database itself is open source – just like Apache Cassandra is — ScyllaDB makes money by selling enterprise add-ons for security, authentication, and the like.)
Cassandra in many ways is a victim of its own success. While the original developers at Facebook had a great architecture, some of the technical decisions made over the years were not conducive to long-term success, according to Laor.
“The project took off and people started using it,” he says. “It started as a hobby and evolved over the years, and it was hard sometimes to stop and rethink it. This is exactly what we came around with, a fresh view.”
Related Items:
Which Programming Language Is Best for Big Data?
What SQL’s Co-Creator Sees in NoSQL
Scalability Answers Found in the NoSQL Family Tree
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers
















