


October 31, 2017
5 Reasons Data Science Initiatives Fail

(WHYFRAME/Shutterstock)
Data science is one of the fastest growing areas of business. Jobs related to data are continuously ranked among the most in demand, with IBM estimating the need for data scientists to rise 28% by 2020. This comes as no surprise, considering nearly every aspect of a modern business requires skills in data analysis.
Building predictive models and other data initiatives differs significantly across industries, but the best practices for developing an effective model remain consistent. So do the pitfalls that ruin or delay them. At the heart of every data initiative is the data vetting process, and if that step is done incorrectly, it negatively impacts the rest of the project. Below are the five most common pitfalls that dismantle big data initiatives, as well as tips for avoiding them.
Pitfall 1: Don’t partition prematurely
Partitioning is the act of breaking up a data set into different pieces. These partitions are used during the model building phase to make decisions, and measure the accuracy of models. The build set is the main ‘laboratory’ for the Data Scientists, and is used to iterate through the model building process. How would the business know if the decisions made during this process are robust enough to be used in production? The test set, if designed correctly, can help answer this question.
Many new data scientists undertake this process of partitioning before all disparate data (i.e. social media, weather, customer information, etc.) has been consolidated, which can lead the data scientist to partition each time new data is added. Unless steps are taken to avoid test sample confusion, it is easy to repartition and miss the fact that during this subsequent partitioning, observations from the original test set, are now in the build set.
Beyond the technical aspect, there are other more practical reasons to wrangle all disparate data sets up front. Bringing in data midway through the model building process creates a non-linear and confusing data pipeline for the model build, and can greatly increase the effort to put the solution into production. In addition, any statistical algorithms that have been applied will have to be redone to consider this new data. As such, no data science work should be done until after the disparate data sets are brought together before partitioning. This can save time and headaches in the long run.
Pitfall 2: Don’t burn a test set during partitioning
The importance of having a mechanism to measure predicted production performance cannot be overstated. In fact, these metrics should be considered much more closely than in-sample performance measures. They also lead to one of the most common, but esoteric, pitfalls for data science work.
The most common partitioning strategy splits the data into two partitions, one for building and one for testing. This usually takes the form of a 50/50 split, 70/30, 80/20 etc. This is visualized using the following diagram:

Using the Build set, the data scientist will perform various algorithmic ranking procedures on the universe of variables, build some initial models, and experiment with the effect of various imputation schemes. These decisions will be judged by the performance on both the Build set and the Test set. If the Test set is available, all decisions will be optimized on it, whether the data scientist is conscious of it or not. In fact, during this phase, a data scientist will likely become more intimate with the Test set than the Build set. Once we take a step back from the chaos, it’s clear we can no longer use the moniker ‘Test Set’, as this data is no longer blind. This is the source of the pitfall. We no longer have a mechanism to estimate production performance of this model. This is commonly referred to as ‘burning the test set’, and is detrimental, especially if more test data is impossible or prohibitively expensive to obtain.
Now, consider a more conservative approach to partitioning that addresses this insidious pitfall. Sample size aside, a data scientist would partition our data into 4 partitions as follows: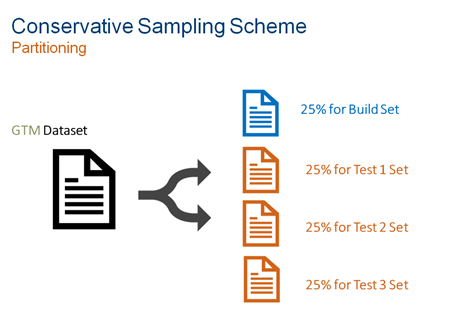
Using this approach, data scientists can go through the same procedure mentioned above to produce initial models using the Build Set and Test Set 1. At some point, optimization will cease, and a candidate model (ready for testing) will be available. However leveraged the first test set is, we still have the mechanism to test these decisions because there are two blind datasets available. As we iterate through these blind sets of data, we will need to make less decisions than before. It is advisable to create as many partitions in this fashion as the budget will allow. It gives us the best chance of success, and the most representative view of the data.
Pitfall 3: Conducting exploratory data analysis (EDA) on the entire data set
EDA is an approach to analyzing data sets to summarize their main characteristics. Statistical techniques can be used (or not), but primarily EDA is the data scientists best way of learning the nature of the data at hand. EDA takes many forms. A few gold standard methods are using summary tables, histograms with and without target values, clustering, and PCA analysis. This work, and the output, is usually shared with the team as some of the first results from a modeling project. It is an exciting time, but data scientists must think carefully about what they are doing and in what order. Commonly, EDA will be done before partitioning and surely before model building. But when looking at EDA output, subtle information about future Test samples are being ingested. By looking at EDA analysis, data scientists see interesting variables, but they are interesting across the Build and all Test partitions, and thus learning about our Blind set.
The treatment to this symptom is simple. Data scientists should perform EDA only on the current Build partition. They still get a good sense of the data, and any interesting relationships, but have not tainted the integrity of the blind data. This is a best practice that is uncommon, but gives the respect warranted to the blind data.
Pitfall 4: Relying too heavily on too few techniques
When building a model for any data science initiative, it is important to use multiple techniques for variable selection. Every technique has its unique set of assumptions, and as such, picks up on different signatures of the target in the predictor space. For example, using a stepwise regression algorithm would reveal variables found to be predictive multivariate that are also linear. It would not find non-linear variables. Conversely, using a tree based approach may find variables that are good at separating the data into homogenous strata, but linearity is not considered. For these variables, more attention is needed for them to be used in a framework that assumes linearity. The predictor space is complex, and usable data is found in the most obscure places. For this reason, it is important to use a diverse and ever-expanding pool of techniques.
Pitfall 5: Not having the end in mind
A data initiative can have sound mathematics and avoid all the common pitfalls previously mentioned, but, without applying it to a specific use case, it will all be wasted. This is where the business side must collaborate with the IT team to produce a strategy that will sustain the project long-term. Organizations should begin projects with a specific business problem that needs to be solved. All stakeholders must understand the purpose of the initiative and be kept apprised of steps taken to address the problems. This is especially true for industries, such as insurance, that deal with vastly complex problems on a regular basis. The best way to accomplish this is by selecting specific metrics to measure and manage project goals. Doing so allows data scientists and the rest of the IT team to isolate and express gains from the initiative as it moves forward, while making it easier to address problems as they occur during implementation and production. It is most common for data initiatives to fail on the implementation portion of the project, and this is largely due to a lack of organizational buy-in.
By carefully assessing these pitfalls, data scientists can prevent common failures that take place during the entire process from testing through production.
About the author: Bailey Pinney is a senior data scientist at Valen Analytics. Pinney is a statistician with substantial experience in a wide variety of statistical methods across multiple industries, including full-gambit experience in model building, from R&D, to deployment, to model monitoring.
Applications:
Data Mining
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Valen Analytics
Leading Solution Providers
















