


August 28, 2017
Kafka Gets Streaming SQL Engine, KSQL
Confluent today unveiled KSQL, a SQL engine for Apache Kafka designed to enable users to run continuous interactive SQL queries on streaming data. The new software, which is currently in developer preview, will lower the barrier of entry for stream processing, the vendor says.
To get work done with many stream processing engines requires developers to be fluent in high level languages like Java, C#, Python, and others. Even Kafka Streams, the stream processing engine that’s part of the open source Apache Kafka project, is a Java library and presumably requires somebody with Java skills to use it effectively.
By contrast, the new KSQL engine from Confluent only requires the user to know SQL. This puts the software into the realm of business analysts who are well-versed in the data-centric language and close to the business issues and opportunities present, as opposed to enterprise developers, who tend to be expensive, slammed with other work requests, and distant from the day-to-day worries of the business.
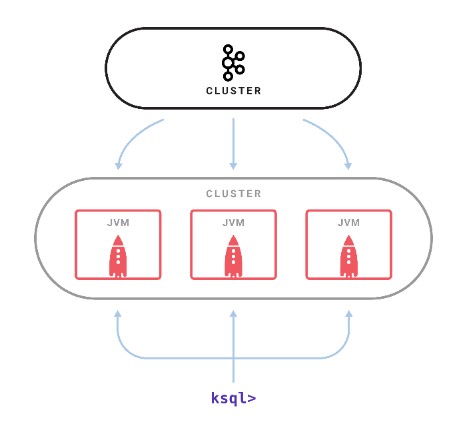
KSQL is part of Kafka and inherits its scalability, fault-tolerance, and support for exactly once semantics (Image courtesy Confluent)
“KSQL lowers the entry bar to the world of stream processing, providing a simple and completely interactive SQL interface for processing data in Kafka,” writes Confluent CTO Neha Narkhede in a blog post today. “You no longer need to write code in a programming language such as Java or Python!”
Inside KSQL
There are several components to KSQL, including a server process that execute queries. A cluster can run multiple KSQL processes, and the user can add them or kill them as necessary to scale up to meet demand. Queries are launched using the interactive KSQL command line client, which sends commands to the cluster using a REST API.
KSQL is based on Kafka Streams, the open source stream processing engine that’s part of the Kafka project. “KSQL uses Kafka’s Streams API internally and they share the same core abstractions for stream processing on Kafka,” Narkhede writes.
Specifically, KSQL uses two Kafka Streams concepts to enable users to manipulate Kafka topics, including the concept of a “STREAM,” which is an unbounded sequence of structured data (or immutable “facts”), and a “TABLE,” which in Kafka Streams is a view of a stream or another table that’s a collection of evolving (or mutable) facts.
“KSQL simplifies streaming applications,” Narkhede writes, “as it fully integrates the concepts of tables and streams, allowing joining tables that represent the current state of the world with streams that represent events that are happening right now.”
KSQL currently supports a range of familiar SQL operations, including aggregations, joins, windowing, and sessionization, according to Narkhede, who helped Confluent CEO Jay Kreps develop Kafka while at LinkedIn.
The software will get other features as time goes on, such as lookups, which is something that most SQL users are imminently familiar with when using SQL with a database, as well as a richer SQL grammar, more aggregation functions, and point-in-time SELECT on continuous tables.

KSQL supports SQL concepts like aggregations, joins, and windowing (Image courtesy Confluent)
But Kafka is far from a database. While it shares some features of a database, such as data persistency, Kafka is all about reading and writing data as it moves, as opposed to running operations on data sitting nicely all in one place. Confluent has a phrase for this: Turning the database inside out.”
“Turning the database inside out with Kafka and KSQL has a big impact on what is now possible with all the data in a company that can naturally be represented and processed in a streaming fashion,” Narkhede writes.
KSQL Uses
One of the uses that Confluent envisions for the new software is streaming ETL. Users can use KSQL to write a transformation, and it will run continuously on the incoming stream of data, as opposed to running in batch. “KSQL, when used with Kafka connectors, enables a move from batch data integration to online data integration,” Narkhede writes.
KSQL can also be used to write anomaly detection routines. Companies across industries have the need to recognize patterns in large sets of incoming data. Banks, for instance, could use KSQL to detect potential fraud or security attacks.
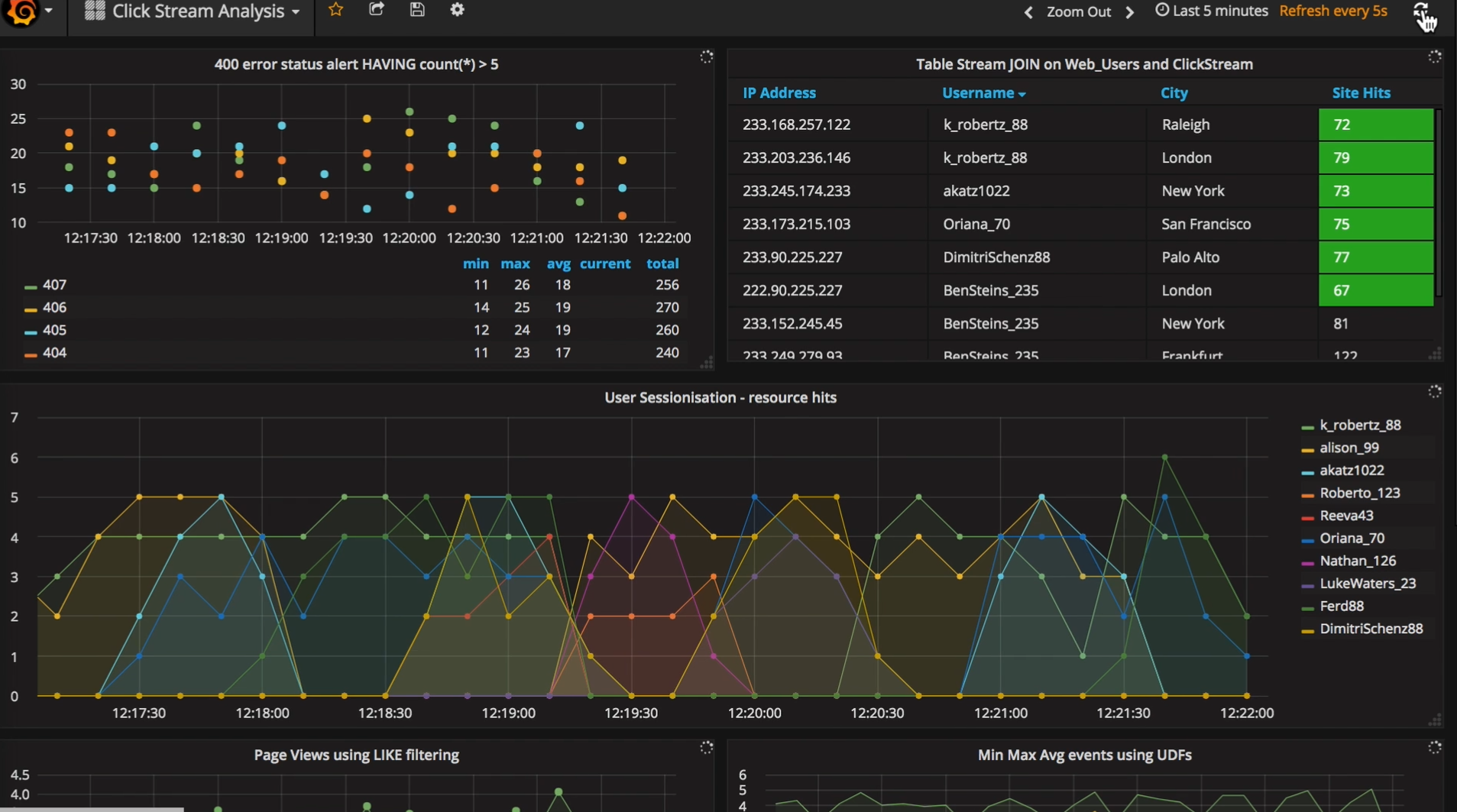
KSQL powers this Grafana dashboard by way of Elasticsearch
The new software could also be used to build real-time monitoring systems. This could be to build a log analysis tool that ensures that critical server-based applications are up and running, or that certain processes are executed in response to triggering events, such as to ensure that new customers are greeted with welcome emails and registered in the database, Narkhede writes.
The output from KSQL can be fed into visualization tools. The Confluent site has a demo of the output of KSQL queries tracking various website statistics being fed into Elastic‘s Elasticsearch data repository via Kafka connectors, and then visualized using a Grafana dashboard.
But KSQL users don’t need to move data to analyze it, according to Shant Hovsepian, CTO at Arcadia Data, which is integrating KSQL into its business intelligence tool. “With KSQL, now users can query Apache Kafka topics directly without dumping data into intermediate databases or key value stores,” Hovsepian says. “This is really a game changer…”
KSQL isn’t the first instance of SQL being used with streaming analytics. One example that immediately comes to mind is SQLstream, whose software is OEMed by Amazon Web Services for its Kinesis Analytics. But the fact that SQL-based data transformation is now part of Kafka shows that it could have a big impact in the future.
Related Items:
How Kafka Redefined Data Processing for the Streaming Age
Only a Fraction of 160 Zettabyte ‘Datasphere’ to Be Stored
Leading Solution Providers
















