


May 5, 2017
Kafka ‘Massively Simplifies’ Data Infrastructure, Report Says

What’s behind the rapid rise in Apache Kafka? According to a new survey of Kafka users by Confluent, the commercial venture behind Kafka, the data pipeline’s capability to “massively simplify” the IT infrastructure of enterprise organizations is driving its adoption.
For its “2017 Apache Kafka Report,” Confluent surveyed IT professionals from more than 350 organizations around the world to identify patterns of adoption of Kafka, the open source publish-and-subscribe messaging bus that’s quickly become a standard component of the big data stack.
Confluent found that organizations are using Kafka in a variety of ways, with the most popular being stream processing, data integration, messaging, and log aggregation, according to the report. These Kafka-based systems support a variety of downstream applications, like data warehousing, application and system monitoring, recommendation engines, and security and fraud detection (see fig 1).
Kafka use is increasing at 86% of organizations have adopted it, according to the survey, which found that a majority have Kafka connected to six or more applications. About a fifth of Kafka users have it connected to more than 20 applications. These numbers are considerably higher than last year’s figures, showing continued growth of Kafka.

Fig 1 (Source: 2017 Apache Kafka Report)
Confluent says the report shows that Kafka is helping to simplify the work of building data-driven applications. Instead of building separate infrastructure for major IT projects like ETL, data warehousing, Hadoop implementations, messaging middleware, and data integration technologies, they’re using a common Kafka layer to simplify the work. (See fig 2 for common Kafka uses.)
“[Kafka] transforms an ever-increasing number of new data producers and consumers into a simple, unified streaming platform at the center of their organization,” the company writes in its report. “It allows any team to join the platform, allows a central team to manage the service, and scales to trillions of messages per day while delivering messages in real time.”
In a recent interview, Kafka co-creator Jay Kreps, who is also the CEO of Confluent, says Kafka has the capability to become the “central nervous system” of the modern data-driven enterprise. The computing community hasn’t seen this before, which is why Kafka is simultaneously so unusual and so promising.
“What we’re seeing in the world…is the emergence of this whole new category of infrastructure around streaming,” Kreps told Datanami in March. “It’s a different category of thing….I don’t think there was something quite like this before….This can really be something that ties together and [becomes] the core data flow in the enterprise and the big central nervous system that everything comes off of.”
Besides simplifying their architecture, Kafka is benefiting customers in several other ways. According to the report, half of respondents say Kafka helps them make more accurate and/or quicker decisions than they could before. Nearly half report that Kafka has reduced the operating cost of data projects, while two-fifths say it improves customer service.
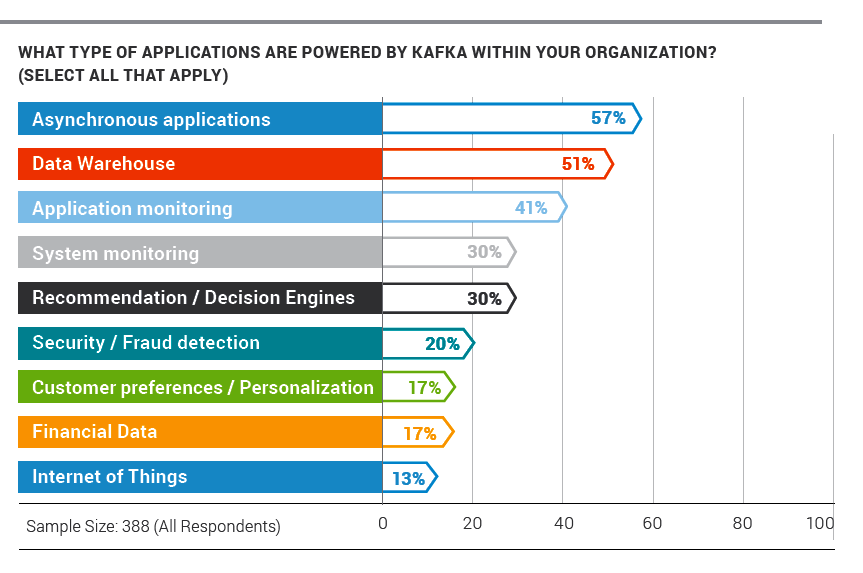
Fig 2 (Source: 2017 Apache Kafka Report)
The report also finds a 15% boost in adoption of Kafka Connect API, which allows users to add new data sources, such as Apache Hadoop, to the Kafka pipeline without having to write custom interfaces. The most common source of data for a Kafka pipeline is a database, used by 59% of respondents. Hadoop is used as a source or a sink of Kafka data by 36% of respondents, which is actually 4% less than last year.
Adoption is also building for another higher level abstraction, the Kafka Streams API, which makes it easier to build stream processing applications atop the Kafka pipeline. Nearly nine in 10 survey respondents report being familiar with the Kafka Streams API, according to the report, which identified ETL as the most common application built atop the API (40%), followed by core business apps (32%) and asynchronous applications (25%).
Kafka was developed by a trio of LinkedIn engineers – Kreps, Neha Narkhede and Jun Rao –as a new way to handle the social networking site’s massive messaging requirements. It was initially created as a low-latency, high-throughput publish-and-subscribe messaging system with built-in durability and fault tolerance.

Fig 3. Interest in Apache Kafka (blue) has exceeded interest in Apache Hadoop, according to Google Trends
Kreps and company released Kafka as an open source project in 2011, and it’s grown from there. Users soon discovered it was a fairly simple matter to set up a Kafka cluster and create any number of data pipelines (or Kafka “topics”) that move data from sources to sinks. In 2014, the three engineers left LinkedIn to found Confluent, which continues developing core open source Kafka as well as proprietary add-ons.
Since then, Kafka adoption has skyrocketed. As of last summer, Kafka had been downloaded more than 2 million times, a number that has surely increased. According to Confluent, the distributed system is used by more than one-third of the Fortune 500; six of the top 10 travel companies; seven of the top 10 global banks; eight of the top 10 insurance companies; and nine of the top 10 US telecom companies.
Here’s another data point that speaks volumes about the future of big data: About a year ago, interest in Apache Kafka surpassed interest in Apache Hadoop, the previous standard bearer for big data, according to Google Trends. Interest in Apache Spark, however, continues to exceed both Kafka and Hadop.
Confluent released the report ahead of next week’s Kafka Summit NYC, where the company is expected to announce a new version of Kafka that delivers “exactly once” processing. The Kafka community, which includes many developers who work at Confluent, has been working on exactly once processing for quite a while, and it believes it has finally solved what’s been called the “holy grail” of real-time processing.
Related Items:
How Kafka Redefined Data Processing for the Streaming Age
Exactly Once: Why It’s Such a Big Deal for Apache Kafka
The Real-Time Future of Data According to Jay Kreps
Applications:
Enterprise Analytics
Leading Solution Providers
















