


April 27, 2017
The Complexities of Governing Machine Learning

(Olivier Le Moal/Shutterstock)
Today’s businesses run on data. It’s essential for any corporation to look for insights about their customers based on the data they collect. That collected information drives everything from business strategy to customer service.
In order to retrieve insights from the massive amounts of data they collect, companies are turning to machine learning, and for those of us concerned with governance, this has begun to create difficult new challenges for the ways we think about and govern data within the enterprise.
Analysts have traditionally used domain knowledge and human expertise to develop models of how their consumers interact with their business. They use data to verify and track the accuracy of these models, which typically are combinations of simple aggregate values (like age, group, and region) and somewhat limited by their generalities.
Thanks to the increasing prevalence of machine-learning (ML), this process has changed dramatically over the past few years. ML allows analysts to invert the process: instead of using data merely to verify models, they create models directly from data. ML algorithms are able to identify interdependencies in the data that aren’t obvious, and some of the resulting models tend to be very difficult for humans to reason about, which is also why they’re so useful. It’s also becoming easier for the average engineer to build ML models, and because they’re starting with the data, they’re able to generate valuable enterprise insights with little or no domain knowledge.
As businesses increasingly rely on ML generated insights to set strategy and design operations, they need to clearly understand the limitations of ML models. New problems are already beginning to emerge.
For example, neural networks, which frequently form the backbone of ML models, are, by their very nature, incredibly opaque. It’s hard to understand why neural networks makes the decisions they make. This can be a huge problem when an enterprise needs to justify these decisions for governance purposes. The same holds true when an enterprise is using data from multiple regulatory environments: a prerequisite to using such data lies in simply knowing what you can do with it, and what obligations attach to which sets of data.
As the need for both robust governance and ML models increases, governance and data science will become competing priorities within most organizations. Trying to balance these priorities is the wrong approach; it will force compromises enterprises simply can’t afford to make. We need a process for streamlining access, so engineers can build better ML models that generate valuable insights. At the same time we need to ensure that every step of this process is governed.
Let’s get specific.
The below example illustrates how easily a typical neural network introduces serious governance issues.. The typical neural network has three types of nodes: an input layer, hidden layers, and an output layer.
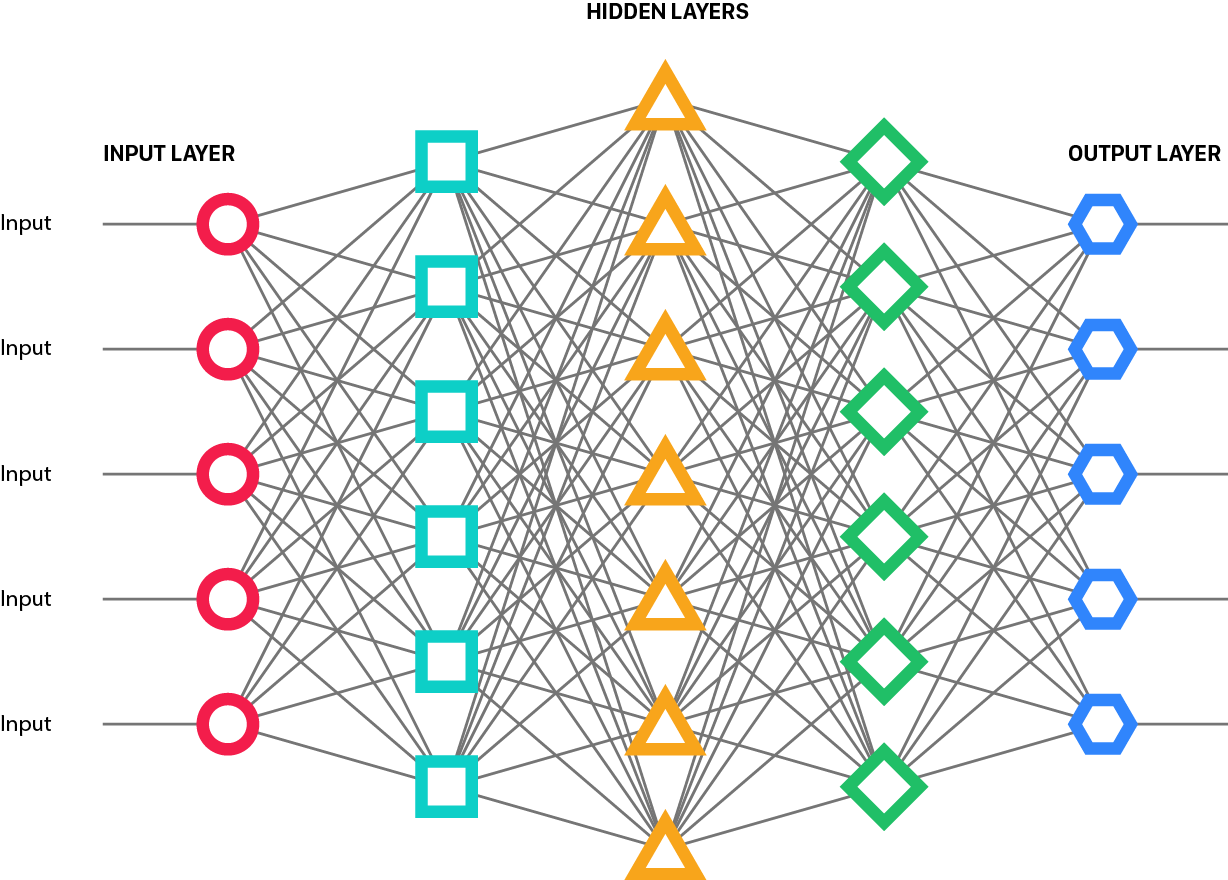 Ideally, engineers have access to a curated, labeled dataset they use to train the network. This training data is fed into the input layer and propagated through the network computations. When data reaches the output layer, the output values are compared to the desired label, and the network weights are updated to maximize the correct output response. Repeatedly sending the training data through the network trains the network to respond with the correct output labels for given input vectors. Once the network is trained, new uncategorized data is sent through the network computations and the output nodes are examined to determine a predicted label for the new data.
Ideally, engineers have access to a curated, labeled dataset they use to train the network. This training data is fed into the input layer and propagated through the network computations. When data reaches the output layer, the output values are compared to the desired label, and the network weights are updated to maximize the correct output response. Repeatedly sending the training data through the network trains the network to respond with the correct output labels for given input vectors. Once the network is trained, new uncategorized data is sent through the network computations and the output nodes are examined to determine a predicted label for the new data.
Simple, right?
Hardly. The average engineer is not thinking about bias or proper provenance when designing a neural network. They are focused on nuances such as ideal network topology, activation functions, training gradients, weight normalization, and data overfitting. Once a model is trained, engineers quite frequently lack understanding of the model’s actual decision-making process. What if they’re called on to explain why a model made the decision that it did—to prove, for example, it didn’t make a legally questionable decision, like discriminating on the basis of race? What if a data subject seeks to exercise her right to prevent her data from being used to train the model, or used in the model at all, a right protected by the EU’s primary data protection regulation, the GDPR? This is where today’s governance models start to break down.
To cite another example, imagine being an engineer at a large, multi-national bank who needs to build a new ML-based fraud detection model, using the type of neural net depicted above. The data sources you are using may come from different countries that impose different restrictions on how this data can be leveraged. In the case of the GDPR, these restrictions can have huge consequences on how you build and deploy your model. Article 6 of the GDPR, for example, lays out six — and only six — conditions under which you can process EU subjects’ data. This means that you need to understand what types of limitations govern each of the data sets you’re using. Each time you introduce a new data set with new restrictions, you introduce new limitations.
Enterprises that can’t make these limitations clear have a choice: use data without understanding its restrictions (ending the regulatory audit trail, and potentially violating regulations or enterprise policies), or abandon the project. Neither is a viable outcome.
This is why metadata management is the key to understanding risk. Enterprises need to be aware of changes in rules governing data as well as updates or gaps in the data used to train existing models. In all of these situations, engineers need to be equipped with the proper governance controls. Only then can they understand how rule changes applied to data affect their models and subsequently retrain these models in ways that decrease risk.
When it comes to this type of risk management, the tools that engineers and data scientists currently use to create ML models are woefully inadequate. Popular ML computation frameworks like Tensorflow and CNTK, for example, make it easier to build ML models, but they also increase risk. They don’t provide any support to apply policy controls on input data, enforce rules as data is merged, manage the feedback loop on how the model is performing, or keep track of features as they are introduced into a ML model.
As engineers merge and feed data sources into a ML model, the model’s most important features need to be flagged. If not, it’s nearly impossible to understand whether regulations on controlled data may force them to retrain the model.
The data management process is complex and must be carefully managed. Most engineers, quite frankly, are not thinking about this process. They’re just trying to figure out how to build or retrain their models.
So how do we address governance problems created by the increasing use of ML?
To begin with, integrating governance functions into data-science tools needs to become a higher level priority. Data-science tools should enable data scientists to easily incorporate proper governance into machine-learning operations. Governance features should be baked into data-science tools, and these features should include data management (covering what data exists, what it describes, along with user and purpose-based access controls); feature definitions and algorithm transparency (making clear what features are being used in which models); flagging and feedback loops (illustrating when data or policies change, when is better data available, and more); robust auditing (what data and models are being used by whom, and for what purpose); and privacy preserving features such as masking, anonymization and differential privacy (so that sensitive information is only used when absolutely necessary).
Meanwhile, the bodies regulating data use need to better understand data usage in order to appreciate the effects of certain restrictions. Just as engineers need to recognize the nuanced governance requirements in developing their ML models, so too do the governing entities setting these policies need to understand the nuances and capabilities of machine learning as well as the processes engineers can deploy to secure and protect data. Only then will they be able to design nuanced rather than wholesale restrictions.
With access to new tools focused on governance in machine-learning, enterprises will be able to create models that minimize a wide array of regulatory and ethical risks. These models will need to ensure privacy; they should be fully auditable, and easy to retrain. Governance teams, development teams and data owners will need to embrace tools that foster efficient collaboration if they are to effectively manage risk and conform to volatile regulatory controls.
Ultimately, governance can enhance ML rather than stand in its way. 
About the author: Matthew Carroll is President and CEO of Immuta, the unified data platform for the world’s most secure organizations. Carroll has spent the past decade analyzing complex and highly-regulated datasets in an effort to support multiple US Intelligence Community customers. Follow him on Twitter here.
Related Items:
Scrutinizing the Inscrutability of Deep Learning
Leading Solution Providers
















