


March 14, 2017
Cloudera Gives Data Scientists a New Workbench

Data scientists will get the flexibility of a data science notebook with the security and governance of a locked-down Hadoop cluster through the Data Science Workbench, a new Web-based product unveiled by Cloudera today at the Strata + Hadoop World conference.
Companies are suffering from an impedance mismatch that exists between the open source Python- and R-based tools that data scientists want to use and what Hadoop provides, says Cloudera director of product management Matt Brandwein.
“The way IT exposes Hadoop is as this incredibly secure, highly governed data source, and as a result the only way the data science team can use their favorite tools and packages is to extract it from the cluster and put it somewhere else,” Brandwein. “This is obviously bad, and getting worse.”
Removing the data from a secured Hadoop environment to a Jupyter or iPython notebook not only raises the risk of data loss and compliance violations, but it creates data synchronization and forking issues. “This is bad for the data scientists because they’re working with subsets of data yet again,” Brandwein tells Datanami. “When you’re looking for needle in a haystack, you kind of need a haystack.
It’s become even more of a problem in light of the new deep learning technologies that data scientists want to start experimenting with, he adds. “But IT is pretty hesitant to install those things on the cluster because they have production data that’s secured,” he says.
The new Data Science Workbench will address that impedance mismatch by giving data scientists access to all the latest data science tools within a centralized and controlled environment. After getting access to Data Science Workbench (it has Kerberos built in), users can run just about data science tools against the Hadoop-resident data from the comfort of a Web browser.
“It’s like a collaborative notebook,” Brandwein says. “I can run Python and R code. I can install third-party packages through the browser as an end user, and I can share those projects …. with my colleagues. So effectively I can get what I get with a notebook, because it’s built with notebook technology, but I also get the collaborative, the environment management, the security, and the ability to work with Hadoop clusters directly.”
Cloudera’s new Data Science Workbench
The product uses Docker containerization technology to isolate each user and his tools from every other users and their tools. “So a user can have this version of Python this version of Pandas or Matlib, while other user can install Tensorflow without disrupting anybody else,” Brandwein says. “Everything is on a container, and you can’t possible do too much damage.”
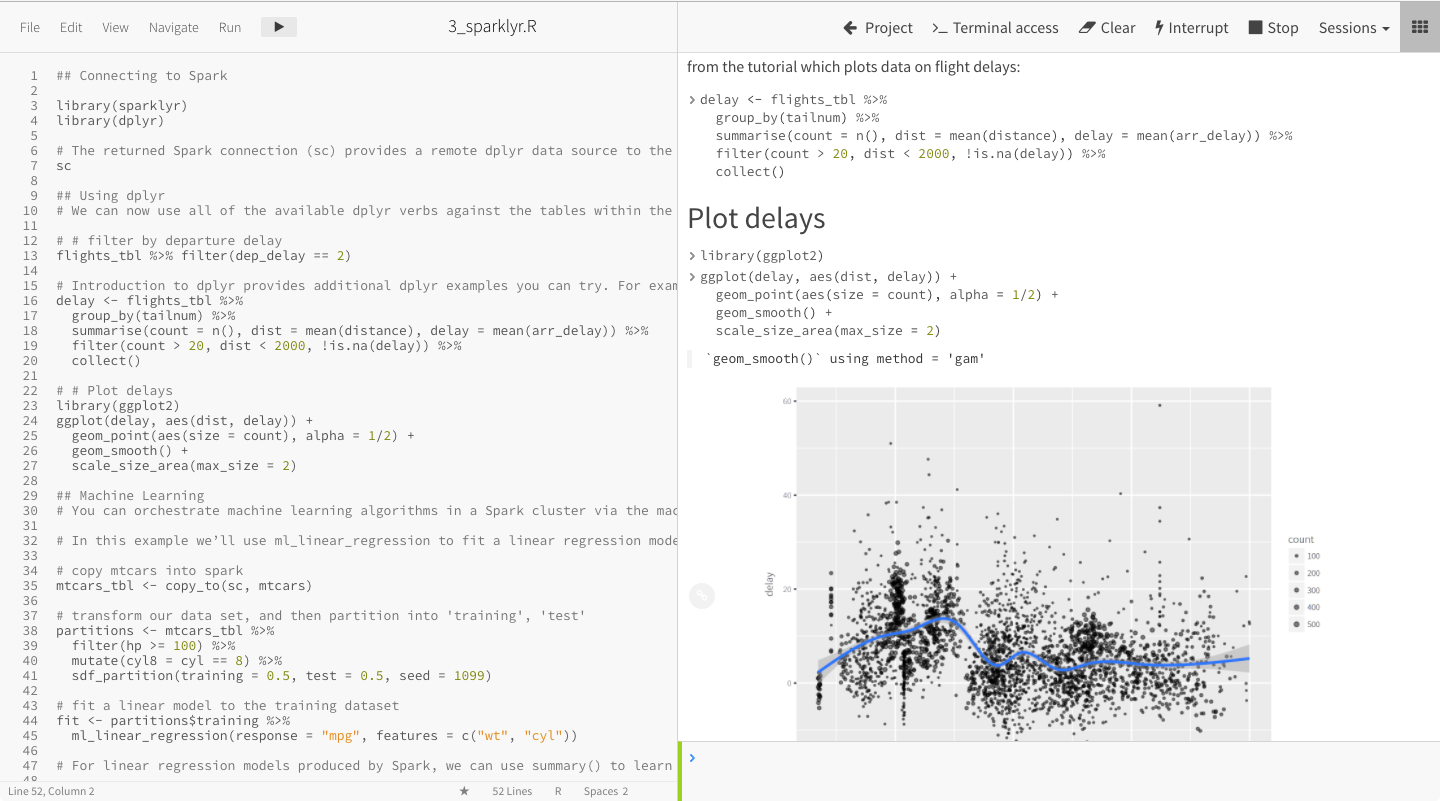
The software is based on Jupyter data science notebook technology. It looks and functions like a notebook, and is compatible with documents from those notebooks. But Data Science Workbench is not notebook, because you can’t actually download the data and work with it offline.
The data stays on Hadoop, and can only be accessed through the tool. Users can’t download the data to their PC or laptop, which increases security. “A lot of our financial services customers don’t want the data checked into GitHub,” Brandwein says.
The Data Science Workbench looks a bit like a modern integrated development environment (IDE), Brandwein says. Users see the code on the left side of the screen and on the right side they see an interactive shell. When the user runs code, it’s rendered just like a notebook. “Your visualization will render the way they would as a notebook,” he says.
In addition to letting users work with their favorite R, Python, or Scala packages, the Data Science Workbench also lowers the barrier of entry to using Apache Spark.
“By making Spark more accessible to these users through Python and R, we’re now making it possible for these users to build and test models on full data sets as opposed to subsets,” Brandwein says. “Historically getting a notebook to work with Spark on a secured cluster was basically impossible.”
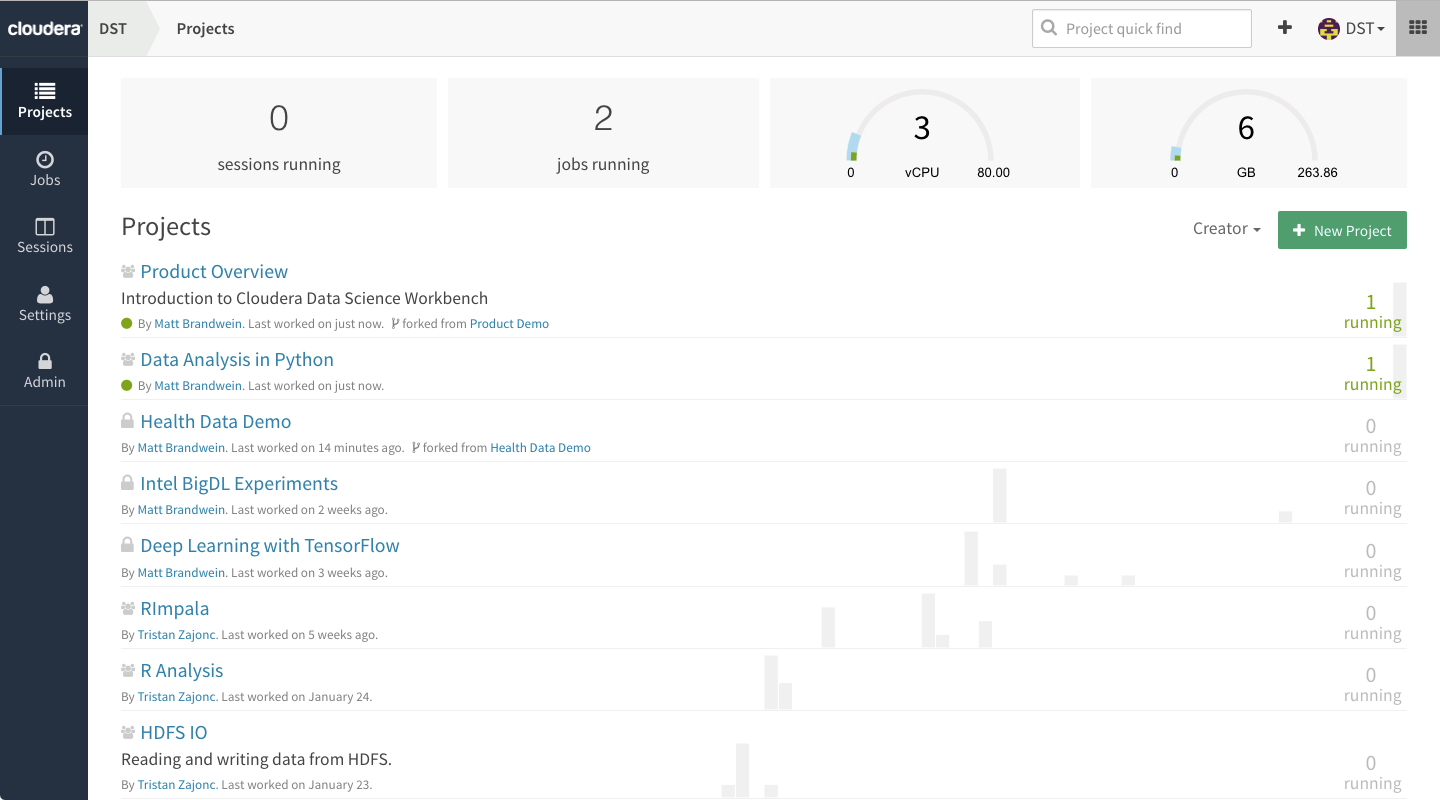
Cloudera hopes to bolster data science productivity with its new offering
Any Hadoop engines can be accessed through the tool. “You can do whatever you like,” Brandwein says. “Spark is the most clear cut fit for data science workload, but you can connect to Impala, and you can run other frameworks as well. Anything you can call from Python or R or Scala, you can run here.
“Think of it as a safe pale to let 1,000 flowers bloom,” he says.
The offering bears resemblance to an emerging class of tool called a data science platform that’s designed to help customers automate and manage data science processes and tasks. In the future, Cloudera will work to bolster the product’s data science lifecycle audit functionality to help ensure compliance with regulations. The company is also exploring ways to hook the Data Science Workbench into its cloud strategy.
The Data Science Workbench is not yet available, but will become available shortly. For more information, see the company’s website.
Related Items:
A Platform Approach to Data Science Operationalization
8 New Products You’ll See At Strata + Hadoop World
Spark Is the Future of Hadoop, Cloudera Says
Vendors:
Cloudera
Leading Solution Providers
















