


February 28, 2017
8 New Products You’ll See At Strata + Hadoop World

In two weeks, big data enthusiasts from around the world will converge on San Jose for the semi-annual Strata + Hadoop World conference. Existing products like Spark and Kafka are destined to be the stars of the show, while new technologies like Hoodie and Sparklyr aim to gain traction.
Here are eight new big data products that will be presented at Strata + Hadoop World that you that should be on your radar:
PyTorch
PyTorch is a new deep learning framework designed to enable developers to rapidly prototyping of deep learning models for image, text, and time-series data. The software, which was created by a group of developers working for Facebook, Twitter, and Salesforce, is based on Python, and is designed to be more flexible than alternatives like TensorFlow.![]()
According to the PyTorch website, PyTorch helps users build tensors and dynamic neural networks in Python with strong GPU acceleration, although it can also be used with CPUs. The package brings a collection of APIs, commands, libraries, optimizers, and utilities for building neural networks and tensors-based programs.
PyTorch allows developers to use other Python packages, like NumPy, SciPy and Cython, to extend their PyTorch programs. Salesforce Researche’s James Bradbury will present a session on PyTorth on Wednesday March 15 at 2:40 p.m.
Hoodie
Hoodie is the name of a new Hadoop-based storage system developed by Uber to improve on the old batch-style processing used before. The open source software, which is available from Github, was designed to manage storage for large analytical data sets stored on HDFS.![]()
Hoodie serves data via two types of tables, including Read Optimized tables, which provides excellent query performance via purely columnar storage (like Parquet); and Near Real-Time tables, which provides queries on real time data using a combination of columnar and row-based storage (like Parquet and Avro).
“By carefully managing how data is laid out on storage and how it’s exposed to queries,” the; Hoodie website reads, “Hoodie is able to power a rich data ecosystem where external sources can be ingested into Hadoop in near-real time.”
Among the benefits of this approach include making real-time data available for interactive SQL engines like Presto and Spark while simultaneously enabling derived datasets to be created; enforcing HDFS minimum file size limits;
Uber engineers Prasanna Rajaperumal and Vinoth Chandar will be discussing their work with Hoodie during a Strata session on Thursday, March 16, at 1:50 p.m.
Sparklyr
Sparklyr is a new open source package released by RStudio last October to provide an R-based interface to Apache Spark’s machine learning library.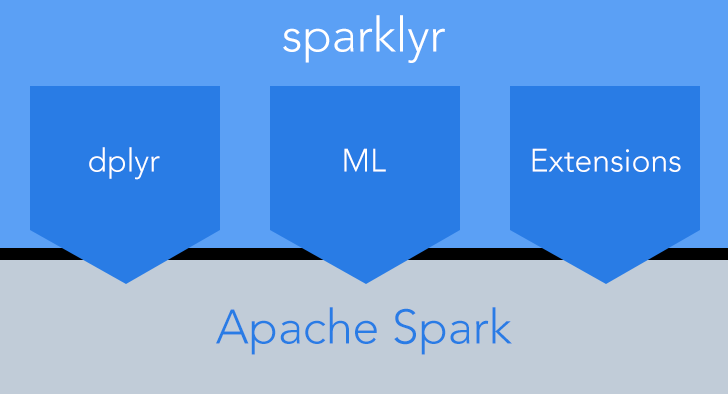
The idea behind Sparklyr, which was developed with help from IBM, Cloudera, and H2O, was to make it easy to analyze big data using R. The free Sparklyr software was designed to let users interactively manipulate Spark data using familiar tools, aggregate Spark datasets using R; and orchestrate distributed machine learning from R using Spark ML or H2O Sparkling Water.
Rstudio Solutions Engineer Edgar Ruiz will be presenting a session on Sparklyr at Strata at March 15 at 2:40 p.m.
RubiX
RubiX is the name of a new cross-engine data caching solution designed by Qubole to deliver memory-like performance for a variety SQL engines for files stored in the cloud. The software is open source and available on Github.
The Hadoop-as-a-service provider unveiled RubiX last July to essentially solves a problem it experienced with its first-gen cache related to performance penalties customers experienced when using Presto to query data stored in columnar layouts, such as ORC and Parquet.
By improving the caching for tables stored in columnar formats; freeing the cache work with other engines, like Hive, Spark, and Tez; and allowing the cache to be shared across multiple JVMs/tasks, the company has seen big improvements in data access times for S3 files.
Qubole’s Shubham Tagra will be presenting a session on RubiX on March 15 at 2:40 p.m.
DistributedLog
Apache DistributedLog is the name of a new low-latency, high-throughput replicated log service that’s currently incubating at the Apache Software Foundation. The software was originally developed at Twitter, which was also the birthplace of Apache Storm, Summingbird, and Heron.
DistributedLog is able to provide milliseconds latency on durable writes with a large number of concurrent logs, and handle high volume reads and writes per second from thousands of clients, according to the DistributedLog website.
Twitter has relied on DistributedLog for years, and says the technology is the foundation for its real-time data services that processes more than 1.5 trillion (17 PB) events per day. Sijie Guo, the tech lead of Twitter’s Messaging group, will be presenting a session on DistributedLog on March 15 at 5:10 p.m.
Fregata
Fregata is the name of a new lightweight machine-learning library for Apache Spark. The software, which is open source and available on GitHub, can give the user either better accuracy or faster performance than the standard machine learning algorithms that ship with MLlib.
Fregata includes four algorithms, including logistic regression, combined features logistic regression, SoftMax, and random decision trees. Since Fregata uses the standard Spark Scala API, it can be dropped into existing Spark applications to provide an easy speed up or accuracy boost.
The software was developed by TalkingData, a Chinese big data service platform provider. Xiatian Zhang, an engineer at TalkingData, will present a session on Fregata on March 15 at 5:10 p.m.
iobeamDB
IobeamDB is a new distributed time-series database out of Princeton University that’s designed to efficiently store query data collected as part of IoT workloads.
Traditionally, time-series data has been stored in column-oriented databases, which support fast roll-ups on data. However, according to the backers of iobeamDB, these column stores can’t handle complex queries.![]()
The database, which is being developed by the company iobeam, essentially presents the user or the BI tool with the illusion that it’s storing data in a single continuous database table across all time and space, even though this table is split into many chunks across servers, the company says.
Iobeam co-founder and CTO Michael Freedman will present a Strata session on iobeamDB on March 15 at 5:10pm.
Weld
Weld is a new product designed to optimize distributed big data workloads to the specific hardware it’s running on.
While big data developers are finding great ways to use out-of-the-box machine learning, graph analytics, and SQL engines to crunch big data, the workloads often run less efficiently than if they had hand-coded them.
Weld—which is to be open-sourced soon–helps to narrow the gap between the runtime efficiency of hand-coded applications and the developer productivity enjoyed by using out of the box engines like Spark SQL, TensorFlow, and NumPy. It does this by capturing the structured of diverse data-parallel workloads and then using a cost-based optimizer to get them running faster.
Weld was developed by Shoumik Palkar, a second-year Stanford University Ph.D. candidate studying under the tutelage of Stanford Professor Matei Zaharia, the creator of Apache Spark. Palkar will present a Strata session on Weld on March 16 at 11:50am.
Related Items:
Feature Articles from Fall Strata 2016
Feature Articles from Spring Strata 2016
Tags:
big data, DistributedLog, Hoodie, iobeamDB, new products, PyTorch, RubiX, Sparklyr, strata hadoop world, Weld
Leading Solution Providers
















