


December 7, 2016
This Week in Graph and Entity Analytics

(Sergey Nivens/Shutterstock)
Yahoo, Cambridge Semantics, and Ravel Law are among the companies making news this week in the burgeoning field of graph and entity analytics.
Wouldn’t it be nice to automatically extract meaningful information from text, such as what it’s about and identifying the major entities (people, places, things) without explicitly training a program to do so? That’s essentially what Yahoo does with its Fast Entity Linker, which is an unsupervised entity recognition and linking system.
The big news out of Sunnyvale, California today is that Yahoo has decided to make Fast Entity Linker freely available as an open source product. Now, anybody can use software to automatically extract entities and perform basic link analysis on text.
One of the cool things about Fast Entity Linker is that it supports not just English, but also Spanish and Chinese. That makes it one of only three freely available entity recognition and linking systems that support multiple languages. The others, according to today’s Yahoo Research blog post, are DBpedia Spotlight and Babelfy.
Yahoo’s Fast Entity Linker (FEL) core was trained with text from Wikipedia, and uses entity embeddings, click-log data, and efficient clustering methods to achieve high precision, according to Yahoo Research engineers. “The system achieves a low memory footprint and fast execution times by using compressed data structures and aggressive hashing functions,” the company says.
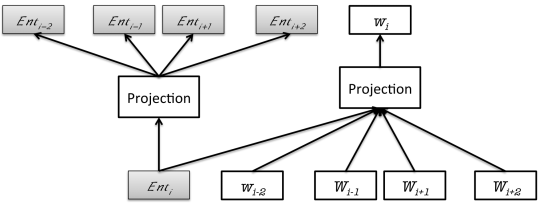
How Yahoo’s FEL trains word embeddings and entity embeddings simultaneously. (Image courtesy Yahoo Research)
Named entity extraction and linking systems like FEL are critical elements for many text analytics projects. The approach is particularly useful for fine-tuning search engines, recommender systems, question-answering systems, and for performing sentiment analysis.
You can download Yahoo’s contribution at github.com/yahoo/FEL.
A Triple Crown
We also have news out of Boston, Massachusetts, where Cambridge Semantics claims it has “shattered” the previous record for loading and querying humongous sets of linked data, or “triples” that include three pieces of related data, including a subject, a predicate, and an object.
The company says its Anzo Graph Query Engine, which it obtained with its 2016 acquisition of Barry Zane’s SPARQL City, completed a load and query of one trillion triples on the Google Cloud Platform in less than two hours. That is 100 times faster than the previous solution running the same Lehigh University Benchmark (LUBM) at the same data scale, the company claims.
 To put that into perspective, one million triples occupies the same amount of data as six months of worldwide Google searches, 133 facts for each of the 7 billion people on earth, 100 million facts describing all the details of each of 10,000 clinical trial studies, or 156 facts about each device connected to the Internet, according to Cambridge Semantics.
To put that into perspective, one million triples occupies the same amount of data as six months of worldwide Google searches, 133 facts for each of the 7 billion people on earth, 100 million facts describing all the details of each of 10,000 clinical trial studies, or 156 facts about each device connected to the Internet, according to Cambridge Semantics.
Zane, who is Cambridge Semantics vice president of engineering, says long load times have been a big hurdle for enabling semantic-based analytics. “With the LUBM results, it’s been validated that a loading and query process that once took over a month’s worth of business hours can now be completed in less than two hours,” he says in a press release.
Anzo Graph Query Engine is a clustered, in-memory graph analytics engine designed to enable users to write and run ad hoc and interactive queries using open semantic standards, like SPARQL, which is a query language for Resource Description Framework (RDF).
Zane, who also created the ParAccel column-oriented database that today is at the heart of Amazon’s RedShift offering, says the graph approach is needed because increasing data volumes will break traditional analytics built atop inflexible relational databases.
“This benchmark record set by our Anzo Graph Query Engine signals a paradigm shift where graph-based online analytical processing (GOLAP) will find a central place in everyday business by taking on data analytics challenges of all shapes and sizes, rapidly accelerating time-to-value in data discovery and analytics,” he says.
Graphing Legal
This week also saw the launch of new semantic technology from Ravel Law, a San Francisco-based startup that’s looking to bring advanced analytics to the legal domain.
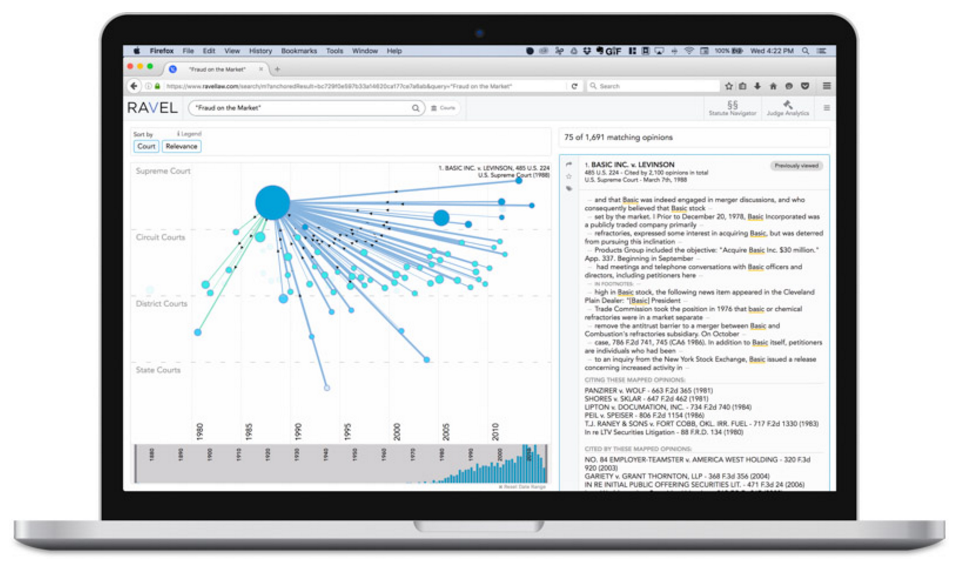
Ravel’s Court Analytics gives the user a graph-based interface to explore connections among judges, courts, and cases in the legal world.
Ravel’s new Court Analytics offering combines natural language processing, machine learning, and semantic technology to help lawyers get a leg up in court. By analyzing millions of court opinions and identifying patterns in language and case outcomes across 400 federal and state courts, the software enable lawyers to make better decisions when comparing forums, assessing, possible outcomes, and writing briefs, the company says.
“Attorneys can inform their strategy with objective insights about the cases, judges, rules and language that make each jurisdiction unique,” Ravel CEO and co-founder Daniel Lewis says in a press release.
The product builds on the company’s exclusive access to one of the country’s largest libraries of case law: the one at Harvard University, which is second only to the Library of Congress. Harvard Law School has tapped Ravel in a partnership called the Caselaw Access Project to digitize 40 million pages of text across 43,000 volumes to make them freely accessible online. In exchange for doing the OCR grunt work, Ravel gets an eight-year license to commercially exploit redacted files.
The company, which was founded by Stanford Law graduates, looks to be doing exactly that. Court Analytics is its third product, behind Judge Analytics and Case Analytics. And it appears the company is aiming for more. “Judges are just one entity,” Lewis tells ABA Journal. “You can use analytics for individual firms, lawyers and companies. There’s fertile ground for new insights there.”
It’s unknown exactly what technologies Ravel uses. But according to a recent job posting for a lead data scientist, the company was looking for somebody familiar with named entity recognition systems, semantic relatedness, topic modeling, and automatic document summarization. Expertise in Spark, Weka, H2O, Python, MLLIB, Scala, Java, Python, and SQL were also listed.
Related Items:
Text Analytics and Machine Learning: A Virtuous Combination
Yahoo Shares Algorithm for Identifying ‘NSFW’ Images
5 Factors Driving the Graph Database Explosion
Technologies:
Middleware
Leading Solution Providers
















