


December 7, 2016
Code Modernization Enables New Economics in the Data Center

Through a collaboration with Intel to modernize code and take advantage of machine learning algorithms, Pikazo was able to drop the cost of their service to create high-resolution “artistic” images – suitable for framing or content creation – from $14 per image to $0.99. Code modernization is the key to the Pikazo runtime success story.
The CPU-based version of the Pikazo software now provides a 12x speedup over an NVIDIA (NASDAQ: NVDA) K40 GPU when processing high-resolution images according to Noah Rosenberg, CEO of Pikazo. “The biggest challenge is memory,” Rosenberg noted, “as 16 GB of memory is required to process a 1600×1600 pixel image. That just won’t fit on a GPU”.
Enabling new economics in the data center
The 14x cost reduction is the result of optimizations to the Torch middleware library that greatly reduced the time-to-solution when processing high-resolution images – from more than an hour to approximately 5 minutes on an Intel (NASDAQ: INTC) CPU. Corresponding reductions in the runtime for low-resolution images has reduced the overhead of the free image processing as well. The combination of significantly faster response time and lower costs have greatly increased Pikazo’s business. For example, Pikazo processed over 200,000 images the week of August 4, 2016.
The Torch library was chosen by Pikazo due to its open source licensing and large ecosystem of community-driven packages in machine learning and parallel image processing. The packages are written in the Lua scripting language that makes calls into the C-language Torch middleware. Pikazo also found the claim of “fast and efficient GPU support” on the Torch website to be initially attractive.
Pikazo – a small company of artists and content creators – had direct access to Intel library authors. As a result, Rosenberg explained that “the Pikazo team was able to focus on what they do best – generating pictures rather than modifying software”.
Rosenberg flatly stated, “Intel has completely enabled our economics.”
CPU-based computing opens new technical opportunities
The efficiency of the CPU processing also enables a fat-client, thin-server model, which virtually eliminates the overhead of creating the free Pikazo low-resolution images and effectively lets Pikazo dedicate their computing resources to paying customers.
A fat-client is a very economical model from a commercial application point of view as it utilizes local computing resources on the user’s cellphone, table, or computer. This equates to free computing resources for Pikazo as the low-resolution images can be processed responsively and for-free on the user’s hardware. Meanwhile, the thin-server computing model also means that the company can dedicate nearly all their hardware investment in servers to processing the for-profit high-resolution images. It’s a win-win for both users and the company.
 “A fat client model was just not practical when using GPU computing,” Rosenberg pointed out. The challenge is that Pikazo does not have any control over the client computing environment, which means the software cannot know if the client has a GPU or what, if any, computing capabilities might be available on the GPU. Instead, the CPU-based version utilizes a consistent SMP computing environment on the user’s device, which significantly reduces the complexity, support, and testing requirements of the downloadable fat-client application. Ultimately, users will go away if the software is buggy so consistency and testable code are key.
“A fat client model was just not practical when using GPU computing,” Rosenberg pointed out. The challenge is that Pikazo does not have any control over the client computing environment, which means the software cannot know if the client has a GPU or what, if any, computing capabilities might be available on the GPU. Instead, the CPU-based version utilizes a consistent SMP computing environment on the user’s device, which significantly reduces the complexity, support, and testing requirements of the downloadable fat-client application. Ultimately, users will go away if the software is buggy so consistency and testable code are key.
How Pikazo works
Rosenberg explained that deep learning is used to identify pixel regions in the user’s image that are amenable to further Pikazo processing to add realistic brush strokes and other artistic effects. “No art school degree is required,” he added.
This stylistic processing step is what makes Pikazo so popular and distinguishes it from other image processing projects such as Google’s deep dream, which only magnifies image characteristics. Instead Pikazo switches in brush strokes to recreate the image according to a desired artistic style. Pikazo users can choose from hundreds of ready-made styles on the website. Feeling creative and want to experiment your own style? Not a problem as Pikazo lets users upload any image so they can experiment with any creative style they wish.
Rosenberg is an advocate to bring art into the lives of everyone, and further that art should be both personal and expressive. The website states, “Pikazo was developed in 2015 using neural style transfer algorithms. It is a collaboration between human, machine, and our concept of art.”
Personal art is important as it lets users create images that have meaning for them. Images of family members, selfies, pets, familiar landscapes can all be turned into personal art that can enrich people’s lives. Alternatively, content creators can use art to attract attention and generate business. The barrier of entry is very low: two clicks using the free app and a $0.99 cost when you want to print a high-resolution image.
Code Modernization for efficient CPU-based computing
In brief, code modernization focuses on revising existing software to: (a) increase parallelism, (b) efficiently utilize the CPU’s vector units.
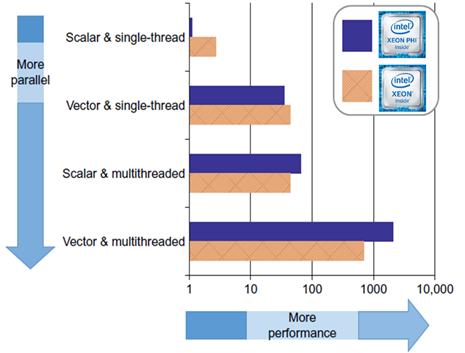
Figure 1: The importance of using both parallelism and vectorization (Image courtesy Intel).
The speedup can vary by problem size. For example, Pikazo observed the following speedup on a 3200 sized tensor after optimization on two different Intel platforms.
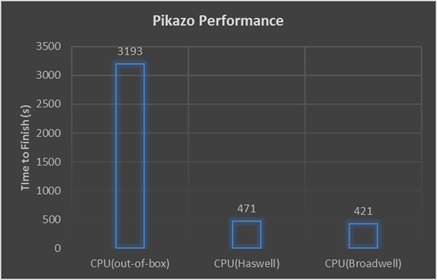
Figure 3: Example Pikazo performance compared to optimized performance on a size 3200 tensor. (Source: Pikazo)
Torch Optimization Extend to Intel Xeon Phi
Accessing Intel expertise is not a requirement to achieving significant performance improvements. As a commercial company, Pikazo is out of necessity focused on delivering and improving the end product of the computation – in this case images their customers like and buy. Thus the Intel collaboration provided Pikazo with the technical expertise they needed to get the optimization done while providing Intel with a use case showing that code modernization can greatly benefit and expand the opportunities for machine learning and commercial users. However, accessing the knowledge of the Intel development teams is not required. Other technically savvy companies can achieve significant speedups simply by following good code modernization practices.
For example, Colfax International also observed a significant speedup after modernizing the Torch middleware. Succinctly, the Colfax study achieved a 28x speedup on a NeuralTalk2 case study when running on a dual-socket Intel Xeon processor E5-2650 v4. Further, they observed a 55x speedup when running on an Intel Xeon Phi processor 7210, while also noting that they only restricted their code modernization efforts to the Torch middleware. Rio Asai (programmer, Colfax International) said that it should be possible to increase the parallelism of the NeuralTalk2 source code to achieve additional speedups on Intel Xeon Phi.
Intel has been pushing optimized codes upstream to open source developers. In the meantime, the Colfax team uploaded their changes to https://github.com/ColfaxResearch/neuraltalk2 so others can reproduce their work and enjoy the benefits of the optimized Torch middleware.
Summary
The code modernization benefits observed by Pikazo are consistent with improvements observed by other groups who have modernized the CPU code efficiency of open source machine learning packages. The Colfax International Torch middleware study is one example. The Kyoto University Graduate School of Medicine research team modernization effort of the open source Theano C++ multi-core code is another. (Theano is a Python library that lets researchers transparently run deep learning models on both CPUs and GPUs. It does so by generating C++ code from the Python script for the destination CPU or GPU architecture.)
A wide variety and large number of detailed case studies – including working code examples – are provided in the High Performance Parallelism Pearls series (vol. 1 and vol. 2). Those interested in code modernization for Intel Xeon Phi processors should look to the Intel Xeon Phi Processor High Performance Programming: Knights Landing Edition 2nd Edition. Developers should also checkout the extensive technical material and training around Code Modernization at the Intel Developer Zone: https://software.intel.com/modern-code. In addition, see how to apply Machine Learning algorithms to achieve faster training of deep neural networks https://software.intel.com/machine-learning.
About the author: Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at [email protected].
Applications:
Artificial Intelligence
Sectors:
Retail
Leading Solution Providers
















