


October 26, 2016
Über File System from Alluxio Gaining Enterprise Traction

(Tatiana Shepeleva/Shutterstock)
It took several years, but now we’re starting to see multi-hundred-node deployments of Alluxio, the distributed in-memory file system that was developed alongside Spark and Mesos at Cal Berkeley’s AMPlab. By greasing the flow of data between 30-odd storage systems and 30-odd processing frameworks, the open source software is delivering big processing speed-ups on the order of 10x to 30x—in some cases over 300x—for global firms like Alibaba, Baidu, and CapitalOne.
The premise behind Alluxio (formerly called Tachyon) is deceptively simple. Instead of hand-coding your Spark, MapReduce, or Samza application to read data from HDFS, GlusterFS, or S3 data stores, you point all the data and apps to Alluxio, which does the hard work of making sure data is where it needs to be when it’s needed. It that sense, it functions like an über file system of file systems.
In a briefing with Datanami this week, Alluxio co-creator Haoyuan (HY) Li, the CEO of the company of the same name, and Alluxio’s vice president of product, Neena Pemmaraju, elaborated on the unique approach taken with the file system, and the real-world impact it’s having on some pretty big names in big data.
Virtualized Data Access
“We’re observing an explosion in terms of big data frameworks in the ecosystem. In meantime there are so many storage products and enterprise data is lost in different silos,” Li says. “But the issue is the ecosystem becomes very messy. The performance is very bad because these systems were not built for this particular workload.”
Alluxio addresses the data connectivity and performance issue by presenting a single virtualized data pool that can talk multiple storage protocols. By simply installing the software (directly next to the compute engine, preferably) and configuring the connectors, a Spark application that was originally configured to pull data from HDFS can now pull data from all the other data sources supported by Alluxio.
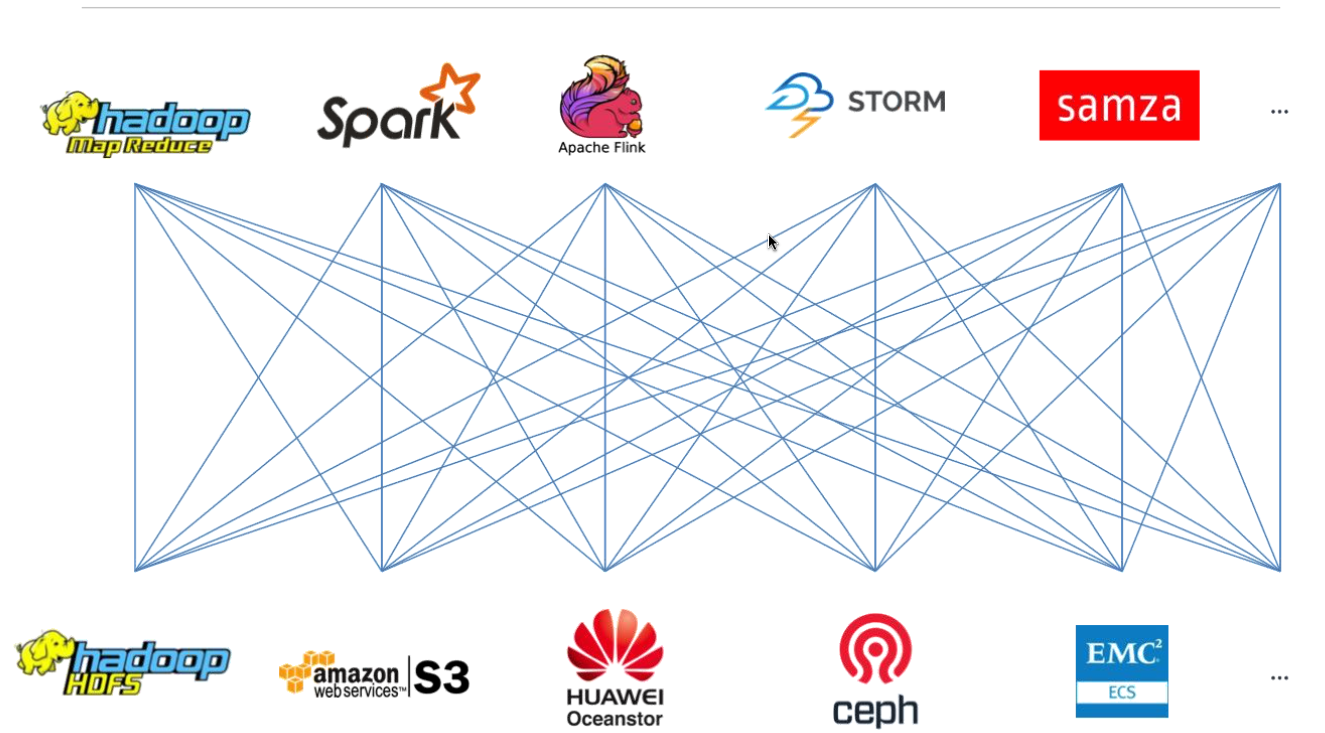
Alluxio enables 30-plus computing frameworks to directly access data residing in 30-plus storage systems at in-memory speeds
When the Spark application needs data, Alluxio serves it. If it’s saved locally on the local Alluxio cluster (again, preferably right next to the computing framework), the Spark application gets the data at in-memory speeds. If the data is stored remotely, such as on Amazon S3, it will come over the wire. (No, Alluxio does not perform magic by eliminating latency introduced by moving data over the Internet, although it might seem to at times.)
A Single Namespace
All the data stored under Alluxio appears to reside in a single namespace to the user and the application, even if it’s stored in different storage systems, data centers, and public cloud providers, Pemmaraju says. This is a key part of the value that Alluxio can deliver to enterprise shops struggling to make multiple storage systems and compute frameworks work together.
“The user is not restricted to just the data that’s available in the Alluxio cluster, because Alluxio is virtualizing across all the different storage systems that are underneath Alluxio,” she says. “So the entire data set is available to the user.”
This brings a number of benefits. First, it eliminates the need to ETL data from place to place, and gives the user a big step in getting out of the data-silo juggling game. In this sense, Alluxio acts as the glue that unifies data and applications across the many repositories in the enterprise.

Alluxio is the fastest growing big data project and now has over 400 contributors
However, because it’s virtualizing data access, Alluxio also enables the separation of compute and storage. This allows users to grow or shrink compute and storage nodes separately, instead of forcing them to rise and fall in lock-step, as with traditional Hadoop deployments.
“It’s not atypical in an enterprise that you have data in a lot of different storage systems,” Pemmaraju says, without a hint of understatement. “As the need for enterprises to extract value from that increases, with the Alluxio layer, you can seamlessly access the data or add it to an existing cluster and extract whatever value you’re looking from it.”
Big Data Folders
Alluxio was first conceived at AMPlab to serve as the storage system to feed data to Spark back in 2012. As Li and his co-creator got into the project, they realized the potential application of a generalized super file system would be much more useful. So insteadl, they created a software defined storage product that could essentially enable any application to see and access data in practically any other location as if it were a folder appearing in Windows PC.![]()
“As a PC user you will never care whether your SSD or HDD is from Western Digital or Seagate. You only see a folder in your file system,” Li says. “We do the same thing. You can mount HDFS as a folder in Alluxio or mount Ceph as a folder in Alluxio. We provide a unified API and a global file system namespace to our users. We hide all the complexity of data storage, of data management, under us. That’s what we do.”
This deceptively simple storage approach is delivering some big results for some of the biggest names in business. Alluxio shared some of the real-world success it’s having with early adopters of the technology.
Early Success
Here are some of the public case studies Alluxio is touting:
- Baidu: The Chinese Web giant is using Alluxio to accelerate the I/O for Spark SQL applications running atop a 200-node Spark cluster with 2PB of data. By putting Alluxio I charge of 50TB of RAM, Spark SQL queries now run from 5x to 30x faster with Alluxio compared to running without it. That means batch queries are now running at interactive speed. “The performance was amazing,” Baidu states in Alluxio’s presentation. “With Spark SQL alone, it took 100-150 seconds to finish a query. Using Alluxio, where data may hit local or remote Alluxio nodes, it took 10-15 seconds.”
- Barclays: The European bank is using Alluxio to speed access to data for queries and machine learning running atop Teradata and Spark. The workflow iteration time (or the time it takes to complete a single analytical job or group of jobs) has decreased from hours to seconds atop a six-node Spark cluster, according to Alluvia. “Thanks to Alluxio, we now have the raw data immediately available at every iteration and we can skip the costs of loading in terms of time waiting, network traffic, and RDBMS activity,” Barclays says.
- Qunar: The Chinese travel website is using Alluxio to streaming the flow of data from HDFS and Ceph into Spark and Flink processing engines, which are used to serve advertisements in real time. Performance has increased an average of 15x on the 200-node cluster, while some models are running over 300x faster.
Today the company formally announced the availability of its first commercial product. Alluxio Enterprise Edition (AEE) builds on the core open source file system by adding security and authentication capabilities, including support for Kerberos, Active Directory, and LDAP. AEE also provides 24/7 technical support for customers. AEE is priced on a per-node basis; pricing was not available when this story was published.
Organizations looking to get started with Alluxio may download Alluxio Community Edition (ACE) free of charge. ACE combines the core open source product along with the Alluxio Manager component. For more information see www.alluxio.com.
Related Items:
Meet Alluxio, the Distributed File System Formerly Known as Tachyon
Tachyon Nexus Gets $7.5M to Productize Big Data File System
AMPLab’s Tachyon Promises to Solidify In-Memory Analytics
Vendors:
Alluxio
Tags:
Alluxio, AMPLab, big data, ETL, file sytsem, HY Li, separation of storage and compute, Tachyon
Leading Solution Providers
















