


September 27, 2016
Data Engineers in Hot Demand

(Dean Drobot/Shutterstock)
The big data community has been dealing with the data scientist shortage ever since big data became a thing. Now we’re learning that there’s possibly an even bigger shortage of another type of data professional: the data engineer.
Data engineer is a relatively new position that’s a hybrid of sorts between a data analyst and a data scientist. Whereas data scientists are at home creating and tuning sophisticated machine learning models and other types of analysis, data engineers excel at manipulating huge amounts of data and ensuring the entire big data software stack can scale to support massive workloads.
“A data engineer is the all-purpose everyman of a big data analytics operation, working between downstream analysts on the one hand, and upstream data scientists on the other. They will often come from programming backgrounds, and are experts in big data frameworks, such as Hadoop. They’re called on to ensure that data pipelines are scalable, repeatable, and secure, and can serve multiple constituents in the enterprise.”
Trifacta co-founder and CTO Sean Kandel noted an uptick in demand for data engineers two years ago. “I’m definitely seeing that title pop up more, and seeing more postings for it,” he told us back then.
Now, that little surge in demand seems to be blossoming into a full-blown data engineering shortage. According to a new report released by Stitch and Galvanize, there are only 6,500 self-reported data engineers across the whole country according to an analysis of their LinkedIn profiles, but more than 6,600 job openings for data engineers–in the San Francisco Bay Area alone.
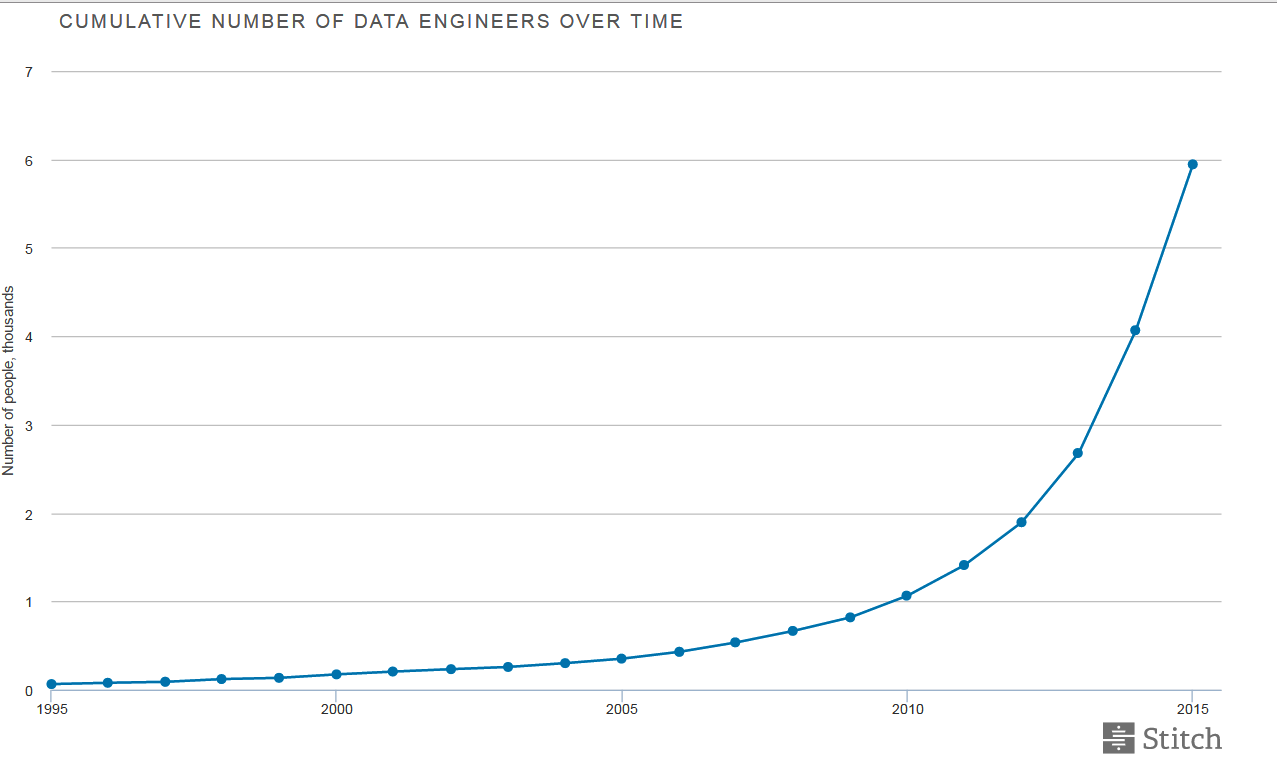
The number of LinkedIn profiles using the title of “data engineer” is growing quickly according to Stitch
According to the study, the number of data engineers has doubled from 2013 to 2015, with the biggest concentration of data engineers in the information technology and services industries. The top five skills needed by data engineers are SQL, Java, Python, Hadoop, and Linux.
Stitch’s analysis (conducted in SQL, Python, and Jupyter, naturally) found that while there are currently twice the number of data scientists as data engineers, the number of data engineers is growing much faster than any other position.
That gap spells trouble for digital companies hoping to hire big data engineering talent, including high-flying Silicon Valley firms like Uber, Airbnb, and Spotify. But it smells like an opportunity for folks like Galvanize CEO Jim Deters, who says his company is working to satisfy both sides of the house through bootcamp-style programs for both data scientists and data engineers.
“There’s huge demand on both sides,” Deters tells Datanami in a recent interview. “For those who are just starting to dabble their toes into understanding they’re a software company and a data company, they might not be as sophisticated with where they’re going. They’re graduating from different business intelligence tools and using R.
“But those that are getting further along the maturity curve,” he continues, “that’s where we see the highest demand for data engineer. That’s where we’ve retooled. We’ve taken our curriculum and instead of making it consumer facing, we’ve addressed the enterprise and helping existing data analyst and data scientist become data engineers.”
Data engineers must be skilled at moving and transforming huge amounts of data, which means they must be familiar with ETL tools and techniques. In the Hadoop world, data transformation often occurs when the data is read, not when it’s initially loaded, and data engineers need to be on top of that.
Being able to find relevant information in the modern schema-on-read environment is a key skill that data engineers must possess, according to Will Smith, a principal data engineer and architect at MIT, who participated in the Stitch study.
“Imagine you have terabytes of log data from ad impressions in JSON,” Smith writes in the report. “The data engineer has no idea what they will find in that data. The skillset now requires the developer to do data discovery and develop code, rather than just using straight SQL. This is a very different skill set than is needed in the schema-on-write environment.”
The growing realization that data lies at the heart of what companies do today is driving the growth of data engineers, says Jonathan Coveney, a data engineer at Stitch. “There’s a growing sense today that data isn’t just a byproduct, but rather it’s a core part of what a company does,” Coveney says in the Stitch report.
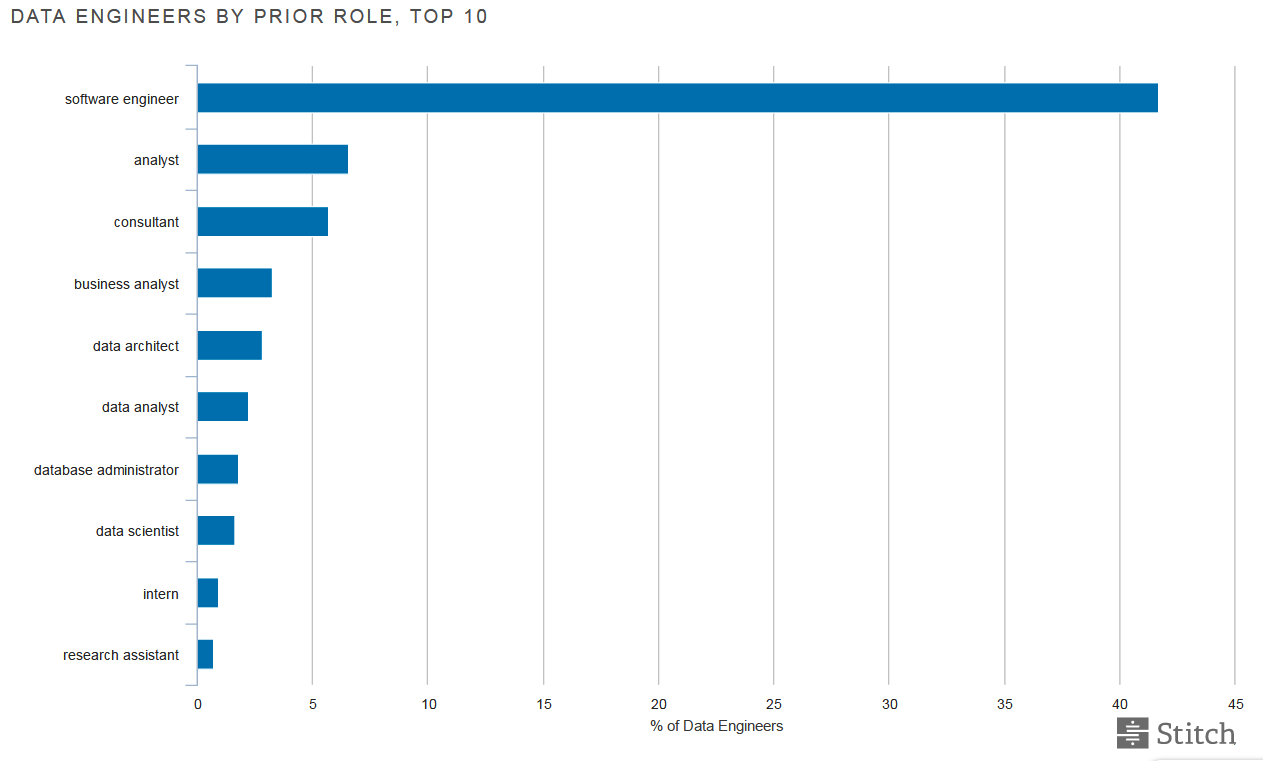
Data engineers often don’t even know they’re data engineers
Most data engineers live and work in the U.S., which isn’t surprising. The San Francisco Bay Area is a hotbed of data engineering talent, thanks to the proximity to UC Berkeley and Silicon Valley Web giants like Google, Facebook, and LinkedIn, which train and employ their employees to do data engineering work.
What is interesting that is that most data engineers don’t define themselves as “data engineers” at all. Instead, software engineers is the most common title for folks doing data engineering work, followed by analyst, consultant, business analyst, data architect, and data analyst. Some data engineers at Silicon Valley firms earn up to $500,000 per year, although those sort of salaries are rare, according to Stitch, which found most job openings for data engineers pay in the low six-digits.
As the title suggests, engineering is at the heart of a data engineer’s job. “A data engineer needs to be far more sophisticated in actual software engineering at the end of day,” Galvanize’s Deters says. “A data engineer is massively deep in the pluming and understanding ETL tools understanding Python and Python libraries, and getting more deeply into the software side and the software stack involved with managing and manipulating massive amounts of data.”
As the rate of change of big data technology continues to accelerate, so too do the skills requird to make use of it. It’s not easy to keep up. “That’s a big trend that’s going on,” Deters says. “These technologies continue to evolve and get more complex and granular. As companies adopt more of these technologies, to actually get more value out of them, they have to continue to invest and build the skill sets.”
Related Items:
Data Science Education Evolves to Meet Surging Demand
9 Must-Have Skills to Land Top Big Data Jobs in 2015
Technologies:
Middleware
Sectors:
Academia
Leading Solution Providers
















