


July 14, 2016
Concord Claims 10x Performance Edge on Spark Streaming
Organizations that are looking for a stream processing engine upon which to build fast data applications featuring high-throughput and low-latency may want to check out Concord, a new framework that emerged from the ad-tech world and reportedly runs 10 times faster than Spark Streaming and Storm.
Concord is gaining momentum as another real-time data processing framework worth considering. The stream processing field is getting crowded with an assortment of frameworks like Storm, Spark Streaming, Flink, Beam (based on Google Cloud DataFlow), and Apex (based on DataTorrent RTS)–not to mention Kafka Streams.
But Concord stands out for several reasons. First, the framework is event-based, meaning it processes every message one at a time in a low-latency (tens of milliseconds) fashion, as opposed to Spark Streaming, which uses a micro-batch paradigm. Concord’s jobs (based on “operators” created by developers) also runs as a containerized service on Mesos, which is emerging as a potentially solid alternative to Hadoop.
The Concord client API also supports a plethora of languages, including Java, Scala, Go, Python, Ruby and C++ (Spark Streaming, by comparison, supports Java, Scala, and Python). Performance of the core Concord service (written in C++) is reportedly quite good: up to 10x faster than Spark Streaming, according to Concord’s benchmark tests against Spark 1.6.
Lastly, its dynamic topology model enables users to modify jobs or even change code while the service is running, thereby protecting against downtime—something that most other frameworks struggle.
Concord Background
Concord.io co-founder Shinji Kim came up with the idea for Concord while working as a developer and product manager at the mobile ad exchange network YieldMo, which was founded in 2012 and today is one of the largest providers of ads to mobile devices, serving companies like CNN, Trulia, and others.
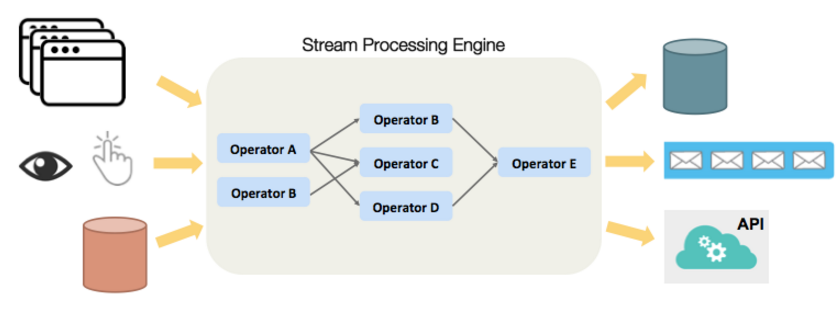
Concord provides a framework for processing events in real-time using operators developed with the API
Kim joined YieldMo during its early growth phase. At that time, the company was struggling to keep up with the number of user events that its clients were asking it to process. Every time YieldMo added a new publisher, it meant adding another 60 million to 100 million events per day to the system, which was based on Storm, Kafka, and Hadoop.
YieldMo realized it needed a new architecture. “At the time, because we had a lot of trouble scaling Storm past 500 million to 1 billion events per day, we were evaluating not a lot of solutions that we could replace it with, such as Spark, Samza, and a few others messaging queue systems,” Kim says in an interview with Datanami.
“We basically weren’t able to find something that we were able to manage the processes at scale, but also be really flexible about the jobs we wanted to run,” she continues. “These jobs aren’t for crunching reports. These are jobs that need to be live and in production to serve an ad and actually run an auction. If any of these jobs or applications go down, we lose money.”
Since YieldMo couldn’t find what it was looking for, Concord.io co-founders Kim and Gallego decided to build a new framework from scratch.
The two found inspiration for the new framework in Google’s MillWheel white paper. “We really liked the approach that they were taking,” Kim says. “We also thought the model of providing a very strong isolation guarantee for all containers from Apache Mesos was the right model for streaming applications to run.”
The isolation that Mesos provided could protect against potentially devastating cascading failures that could occur in a Hadoop paradigm. That technical superiority was attractive, and the fact that Mesos was just beginning to catch on at companies like Twitter, Airbnb, Ebay, and Paypal alieved any concern that Mesos would be a bust. And since then, Kim notes, Mesos has been adopted by Verizon, Ford, and Apple, which uses Mesos to run Siri.
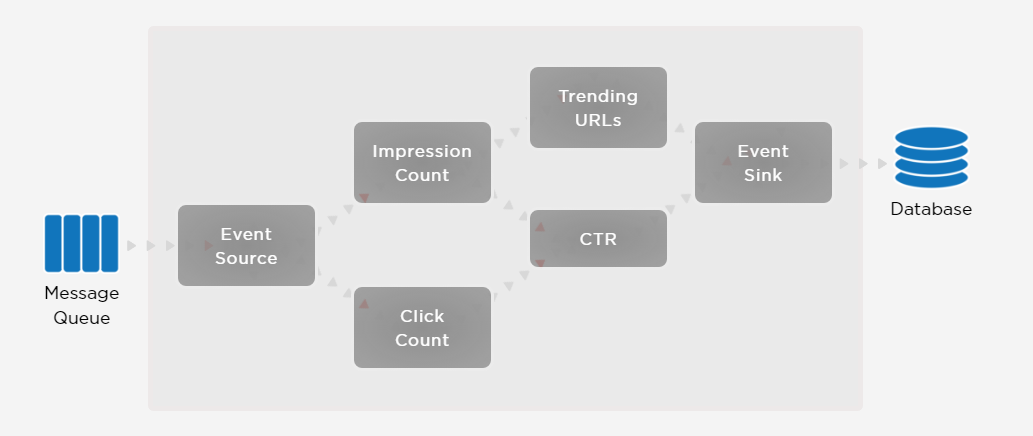
Concord offers built-in support for metrics like event source, trending URLs, event sinks, and impression counts.
And by writing the core of the distributed Concord engine in low-level C++ code, they avoided the high-memory overhead and garbage collection problems that often occur in Java-based designs. That’s a knock on Hadoop, which was written in Java to run the MapReduce batch-processing framework. Hadoop has struggled to adapt to the streaming data analytic paradigm.
Above all, Kim and Gallego wanted to make Concord easy to use for developers. “We wanted a lot of automation around tooling so that a user or developer that’s executing or implementing business logic can really focus on what they want to do, not necessarily worrying about the details of which job runs on which machine, and what needs to happen when there’s a failure,” Kim says.
Dynamic Topology
Concord’s dynamic topology model provides flexibility where other frameworks impose rigidity, with the possible exception of Samza, according to Kim.
“If you compare it to Storm, Flink, and Spark Streaming, these three frameworks run on a very static topology model, meaning you have to define a full job, whether it’s some transformation or enrichment–from the beginning to the end,” she says. “You have a full job. Once you deploy them, if you want to make any changes to it … you have to basically restart the whole topology.”

In a Concord.io benchmark test, the Concord framework ran an overlapping window computation nearly 10x faster than Spark Streaming,
It’s relatively easy to change horses in midstream with Concord, Kim says. “In Concord, if you want to change what’s currently running–like if you wanted to update a part of your machine learning model that’s running in Concord or if you want to deploy a new job that listens to the same data set–you don’t have to touch the current system that’s already running. You can deploy a new operator that also consumes from the same streams of data, without affecting the other jobs that are running.”
That gives Concord users more flexibility to modify jobs, deploy new jobs, scale existing jobs, pointing existing jobs at new data streams, or even change the underlying code in a job without taking the system down.
Most Concord users feed the framework data from Kafka, according to Kim. Today, the company announced a new release of Concord that utilizes open source Kafka to provide at-least-once processing (to complement its existing at-most-once processing) and to provide additional protection against job failures.
Building Momentum
Concord has caught the eyes of several industry luminaries. On its website, Concord.io has quotes from several prominent experts in the stream processing field who sound impressed with the framework.
Richard Tibbetts, the co-founder and CTO of StreamBase, which was acquired by Tibco, said: “Concord is resolving the key issues of high performance stream processing for today’s demanding environments, including throughput, latency, scalability, and ease-of-operational-maintenance.”
Benjamin Hindman, the creator of Apache Mesos and co-founder and chief architect at Mesos-backer Mesosphere, says: “I have yet to see a system like Concord that integrates with Mesos so well to provide full high availability and dynamic task management for stream processing.”

Former YieldMo colleagues Shinji Kim and Alexander Gallego are the co-founders of Concord.io
Business Model
Concord.io Systems recently launched a public beta for the software, which is available from its GitHub page.
Currently, the core of Concord is not open source; even though various operators and connectors are open source, the actual Concord engine is still proprietary technology. However, the company plans to eventually make the software open source. But first the company hopes to be taken under the wing, so to speak, of a larger company that can really put Concord through the paces.
“What we’re really looking to find is getting to more companies and developers that need this type of environment,” Kim says. “What we really hope to achieve is to get to a place where we know there’s a community of programmers that likes Concord and also for us to find partner to work really closely with.
“Just as Kafka had LinkedIn, Storm had Twitter, and Cassandra had Facebook, we think that having a close partnership with a company that can utilize the framework in multiple places and can work closely with us to iterate on our next version is quite important on the business side.”
While Spark has achieved a considerable amount of momentum over the past three years, there is still room for additional technologies. The future has not yet been written, and it’s possible that Concord, which appears to have some advantages over Spark and the incumbent Storm, could grab a piece of the emerging market for stream processing.
Related Items:
Merging Batch and Stream Processing in a Post Lambda World
The Real-Time Rise of Apache Kafka
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
Leading Solution Providers

















