


June 16, 2016
Is Spark Overhyped?

(Leigh Prather/Shutterstock)
There’s no doubt that the Apache Spark phenomena has taken the big data world by storm. But can the technology actually deliver according to the tremendous hype that is accompanying it, or has it been oversold? There were some interesting takes on that question during last week’s Spark Summit.
Thomas Dinsmore, an analytics consultant who has worked with companies like IBM (NYSE: IBM), SAS, AT&T (NYSE: T), and Citibank (NYSE: C) over his 30-year career in analytics, made valuable points on the Spark hype curve during the Spark 360 panel discussion moderated by O’Reilly Media‘s Ben Lorica.
First, Dinsmore pointed to the sell-out crowd of 2,500 who were attending the third-annual Spark Summit conference in San Francisco, not far from Databricks headquarters.
“There are some large number of people who are attending this conference who are voting with their feet and saying we think Spark is on the upside of the innovation-adoption cycle,” he said. “Certainly, if you look at the numbers of people adopting and the reported customer successes, the number of contributors to the open source project, and the number of contributions and so forth–all of it says Spark is on the upside.”
There isn’t much question that many in the big data community have rosy opinions about Spark’s potential. You wouldn’t have to go far to find somebody willing to say Spark is the best thing since materialized views. As we get closer to the GA of Spark 2.0 and its new structured streaming approach that will unify development of batch and streaming apps, we’ll undoubtedly hear more praise of the versatile big data framework.
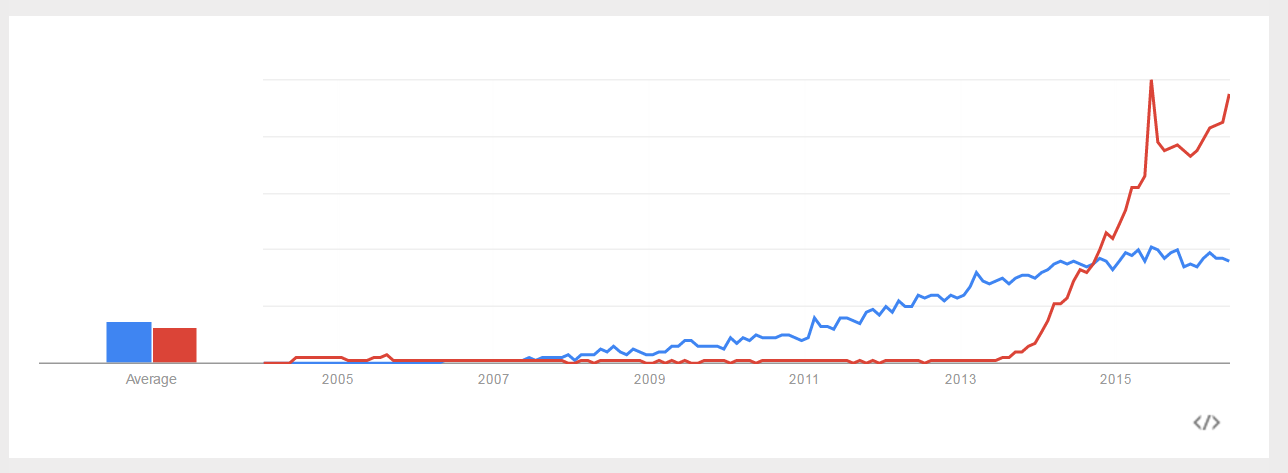
Spark (red line) has outpaced Hadoop (blue line) on Google Trends since 2014
“You do also see individual examples of hype and you’ll see more of that as more big budget vendors with large marketing budgets come in and contribute or just try to cash in on this space,” Dinsmore said. “And I’m not naming names. That’s sort of inevitable in any technology. And it’s not necessarily bad. It generates excitement and makes people look at it.
“Is it overhyped?” Dinsmore continued. “Is there anything that can replace Spark? Well I don’t know. In five years, there may. But as of today, there’s nothing out there in the space that offers comparable functionality and capability to Spark and that is why every single BI and analytics [company], every single commercial vendor is pushing down into Spark or they’re madly developing the capability to push down, because they don’t want to be left behind. And that includes SAS, who developed their own proprietary distributed in-memory engine and were more or less forced to innovate with Spark in their latest product.”
That is certainly a ringing endorsement of Spark. While it’s difficult to track the number of analytic and BI tool vendors who have incorporated the open source technology into their products, there have been many over the past 12 to 24 months.
Spark’s tremendous flexibility is perhaps its greatest asset. Whether it’s creating production ETL jobs, doing ad hoc data discovery, or building machine learning pipelines, Spark provides one framework for doing it all.
 During the Spark Summit panel, Nik Rouda, an analyst with ESG Global, pointed out that Spark’s flexibility was its main strength among developers.
During the Spark Summit panel, Nik Rouda, an analyst with ESG Global, pointed out that Spark’s flexibility was its main strength among developers.
“People want to choose the programing language, choose the environment, choose the data store,” Rouda said. “We’re getting away from the tyranny of the hardware infrastructure. By that I mean you can choose if you want to run on commodity hardware. Do you want purpose-built appliance? Do you want to have a cloud environment? That gives you a lot more flexibility as well.”
Spark clearly has the attention of big data application developers, for all the right reasons. It packs a load of functionality into an open source package, can be used with Python, Scala, Java, and SQL, and it can run practically anywhere. But what does Spark need to get to the next level? According to Mark Schreiber of Cloudwick, it needs to get easier to use.
“A lot of you out here are data engineers, data analyst and data scientists. One of the biggest challenges and opportunities for us now is to move into the early majority phase and really propagate the business use cases of how and why you use Spark to achieve business outcomes,” Schreiber told Lorica.
“This is still an early adopter’s space,” he added. “We’re in a build market right now and this is one of the challenges that IT and analysts and line of business guys have is how do I build a use case for using Spark to replace my data warehouse, to replace my BI, my ETL etc.”
Netflix (NASDAQ: NFLX) is a big supporter of Spark, and is gradually replacing tens of thousands of Pig and Hive jobs with ones written in Spark. But according to Kurt Brown, Netflix’s data platform director, there are things that could make Spark more user friendly to business analysts.
“At this point, Pig and Hive just work for us, partly because we have a lot of expertise in it and a lot of maturity,” Brown said. “Getting to the point [in Spark] where you don’t have to fiddle with configurations and figure out parallelisms and it just sort of tunes things for you–that’s key,” Brown said, while also mentioning a need for better debugging messages.
“It’s the reality of a maturing product,” Brown continued. “But until you get over that hump completely, the analyst and the ones who don’t want to be pioneers—who just want to do their business job—it’s going to be harder to get those people on board.”
Related Items:
Apache Spark Adoption by the Numbers
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
Spark Streaming: What Is It and Who’s Using It?
Applications:
Enterprise Analytics
Technologies:
Frameworks
Sectors:
Financial Services
Vendors:
Databricks
Leading Solution Providers
















