


May 31, 2016
Why Self-Service Prep Is a Killer App for Big Data

(PopTika/Shutterstock)
If you’re embarking upon a big data analytics project, you’re likely considering some sort of self-service data preparation tool to help you cleanse, transform, and standardize your data. And if you aren’t, you probably should be.
From a product standpoint, self-service data preparation tools represent one of the most remarkable success stories of the big data revolution. Sure, platforms like Hadoop and Spark have removed technological tethers and turbo-charged our capability to store and process massive amounts of data, in an affordable and reliable manner.
That it itself is a big deal, no doubt about it, especially when it comes to unstructured data, which tends to make up the majority of new data types. But without the capability to cleanse, transform, and standardize all that data at the scale required, all that power could be for naught.
That’s because one of the dirtiest little secrets of the big data world has been the janitorial work that data scientists must do. Despite all the magic that these unicorns can work on data, many of them spend up to 70 percent of their time manually prepping data, as opposed to doing actual analytics.
For all the talk of using big data and parallel processing as a lever to create an advantage in today’s digital economy, that manual munging work represent a weak fulcrum that threatens to topple the big data investment into a shattered heap.
That, in a nutshell, is why self-service data prep is booming, and why many big data practitioners are investing in a set of tools to bolster their analytic projects.
A Booming Market
Until recently, Gartner analysts predicted that the self-service data preparation market would be subsumed into the larger market for business intelligence (BI) tools. After all, self-service data preparation has been one of the things that BI tools from Tableau, Qlik and others have done for years, and many folks expected this suddenly hot new capability to go back from whence it came.
But earlier this year, Gartner analysts changed their minds and predicted that the market would stay separate. What’s more, they predicted that the self-service data preparation software market would reach $1 billion by 2019, and that the current adoption rate of 5 percent would grow to 10 percent by 2020.
Other analysts firms also noted the acceleration in the segment, including Forrester, which will be publishing its first Forrester Wave analyst report on self-service data prep tools later this year.
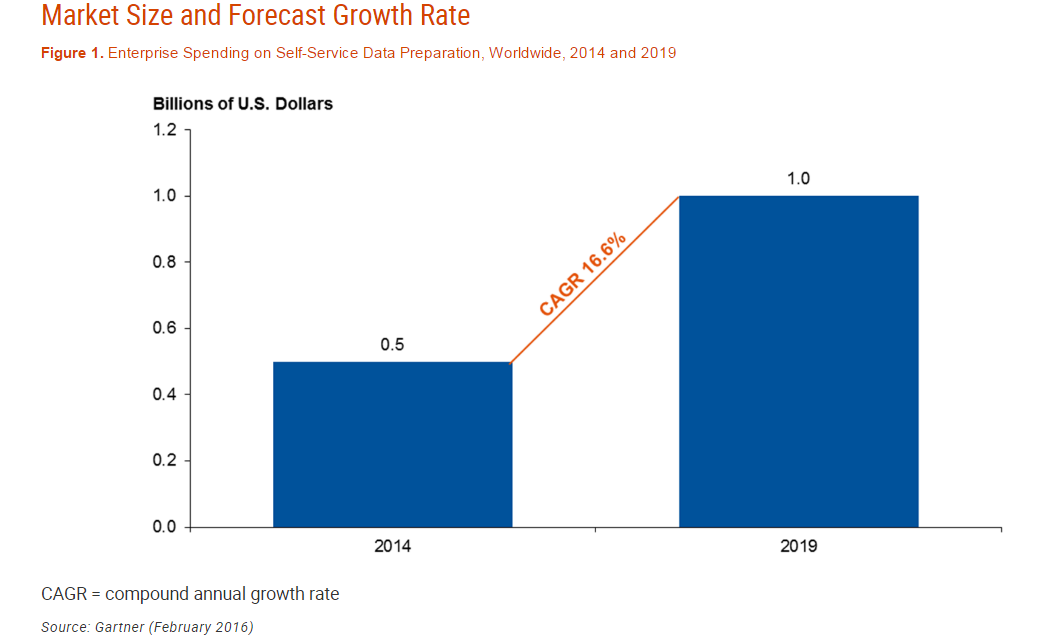
Gartner thinks self-service data prep will be $1 billion business in three years
Depending on how you count them, there are anywhere from 20 to 50 providers of self-service data preparation tools. However, they’re not all equal, and users should carefully examine the offering to make sure they’re getting what they expect. For starters, many BI vendors have jumped onto self-service data prep hayride, even if their capabilities aren’t separate from their core analytics offerings.
“‘Data preparation’ has become something of a bandwagon and a number of vendors are claiming to offer it even though they offer a paucity of required features,” Bloor Research analyst Philp Howard writes in his 2016 report on self-service data preparation and cataloguing software.
IDC analyst Stewart Bond concurs. “The market itself has been very active,” he said. “There’s a lot of software vendors who are trying to get in on this and say ‘Hey we have self-service data preparation capabilities.’ When you look at the software they have, well they’re just trying to latch onto a trend. What they have really isn’t” self-service data prep.
With that said, Howard identified Alteryx, FreeSight, Tamr, Trifacta, and Paxata as the top established players, and called out Unifi as a highly ranked newcomer. Looking forward, the Bloor analyst liked the potential of Alation, Datawatch, Experian, and Talend for the future.
IDC’s Bond is monitoring the entrance of BI vendors into the game. “Qlik has now announced their self-service data prep. Tableau hasn’t gone there yet but I’m speculating they might be working on something,” Bond said. “I’ve also seen Informatica with Rev trying to come up the stack and take some of their data integration capabilities, technology and IP and put it in the hands of analysts with user friendly, intuitive user interfaces.”
But according to Bond, the self-service data preparation pure-plays have an advantage. “Then there’s players like Unifi and Paxata and Trifacta who are trying to come right in in the middle there and really trying to solve the problem and bring products to market in a very new innovative disrupting ways,” Bond says. “They don’t have the baggage of the data integration or BI vendors. They’re just coming at it fresh and brand new, and that’s why we’re seeing some really innovative stuff in the middle.”
Not Fully Automated
There’s a perception that self-service data prep tools can fully automate the process of transforming data. That’s not quite true. While the machine learning algorithms do help with the statistical profiling of large data sets, such as identify outliers and means, they don’t power the transformations themselves.
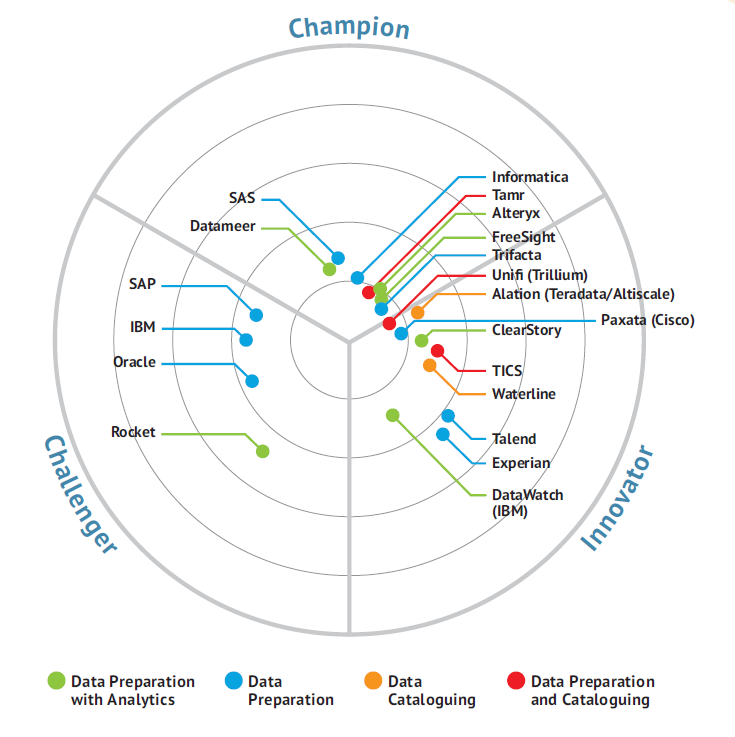
Bloor Research recently rated self-service data prep vendors
“I don’t think we’ve gotten to point where they can automatically clean everything up,” says IDC’s Bond. “We’re seeing the machine learning offer more suggestion than doing it. There are some automated transformations, but that’s not machine learning. It’s rules.”
That’s essentially how Paxata’s product works, says Nenshad Bardoliwalla, chief product officer and co-founder of Paxata. The key advantage of this approach, he says, is that regular business users and analysts are visually creating transformations, as opposed to shunting the job off to IT.
“We use algorithms to automatically detect variations in word patterns or email addresses or other pieces of text, or to figure out how to connect different data sets together,” Bardoliwalla said. “It is that combination of the interactively and the data-first approach, with the visual capability and the algorithms, that allow someone to work with large-scale data, but in a way that actually scales from technology and human perspectives.”
Separate But Equal?
So what’s driving all the interest in self-service data prep, and why did Gartner suddenly decide that it has legs? The key reason why self-service data prep will survive as its own category entity is the growing realization that data preparation needs to be kept separate from analysis.
Trifacta CEO Adam Wilson said a lot of the value of the Wrangle platform lies in neutrality and interoperability. “Trifacta is the decision you make in order to guarantee that your other decisions are changeable,” Wilson said. “That’s an important point to bring out because technology trends will change. We know that because a lot of the decisions made today are different than the ones you made five years ago, so it stands to reason that they’ll be different five years from now.”
Paxata’s Bardoliwalla said something similar. “It would be a bad thing if you had a calculation that defined revenue in BI tool number one and a separate tool and calculation for BI tool two,” he says. “It’s probably useful [to have self-service data prep] if you’re only using that tool. But the second you have more than one BI tool, or multiple data sources, it’s really rather dangerous to go the embedded data prep route.”
The number of data sources will not be decreasing, and neither will the number of BI tools. To that end, it’s likely that self-service data prep will remain a product category unto itself for the foreseeable future.
Running Data on the Horizon
Self-service data prep tools like the ones from Trifacta and Paxata were developed to harness the power of Hadoop and other parallel architectures. To that end, the tools typically executed their transformations largely in a batch mode, although the recent move to adopt Spark has bolstered the capability of analysts to perform transformations in a more interactive manner.
As the move to real-time streaming analytics continues to unfold and stream processing frameworks like Apache Kafka, Spark Streaming, Apache Storm, Apache Flink, and Apache Apex continue to gain traction, vendors like Trifacta and Paxata are working to evolve their products and to keep pace.
“We’re seeing an increasing number of real time use cases which has caused us to spend more time in the labs, investing in those areas,” Trifacta’s Wilson says. “At the same time, for the vast majority of analytic use cases we see today, many of them are still batch, even if the batch windows are increasingly shrinking.”

Self-service data prep vendors are anticpating how their wares will work with real-time streaming
Trifacta is currently working with StreamSets, a data quality startup aiming to provide protection from “data drift” in real-time environments, to address the real-time issue. “We want to help customer that are struggling with massive amount of data, increasingly coming at a variety of different latencies, where data quality and data prep has become the significant bottleneck in what they’re trying to do with information,” Wilson says. “They want one environment or solution that can handle the data, whether it’s big or small, relational or Hadoop, whether it’s structured or unstructured, real-time or batch. To occupy that space in the architecture and the platform is critical.”
Not to be outdone, Paxata—which narrowly beat Trifacta to market with its spreadsheet-like data transformation tool—is also working on the real-time problem. In fact, Paxata signed a partnership deal with South Korean BI software vendor Zalesia to help it bring self-service data prep to the Internet of Things (IoT).
“We are starting to see those use cases crop up,” Bardoliwalla says. “They’re all looking at how data prep becomes part of the IoT world. What we’re thinking is that people want to be able to use the algorithms and visualization tools on continuous streams of data.”
While Paxata is moving to address the real-time streaming, Bardoliwalla insists there’s a larger opportunity here. “We’re moving into something broader that we’re calling about connected data platform,” he says. “It’s not just batch or Hadoop. It’s time in the industry for there to be a new set of information platforms that can handle the new types of use cases today. So whether it’s streaming or contextual or interactive use cases, we are expanding our platform in such a way that we can become the enterprise standard in this new enterprise information platform. space.”
Related Items:
Can Smarter Machines End the Pain and Expense of Data Wrangling?
Hellerstein: Humans are the Bottleneck
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers
















