


April 27, 2016
SnappyData Gets Funded for Spark-GemFire Combo
SnappyData today announced it has received $3.65 million in Series A funding to build a business around its real-time analytics platform that combines Apache Spark, Pivotal’s GemFire data grid, and an innovative data approximation method that makes big data more manageable.
SnappyData was spun out of Pivotal earlier this year to pursue development of its technology platform, which essentially combines the data manipulation capabilities of Apache Spark and Spark Streaming, the in-memory persistence of the GemFire’s data grid, and an approximate query processing (AQP) method that makes huge gobs of data manageable and query-able.
The product (which is called SnappyData, just like the company) is designed to solve certain types of data analysis and processing challenges—in particular those that require customers to not only land and persist a large influx of fresh and ever-changing data, but to also combine it against a historical repository of data and then make the resulting data set something that can return queries quickly.
These are the types of problems that have thwarted Pivotal’s customers and technologists working at companies in multiple industries, says SnappyData’s CTO, Jags Ramnarayan.
“From our customer base in telecommunications, finance, and ecommerce, people are saying it’s not enough that I can stream real-time data and do some analytics on the stream,” he says. “But I might have to do some correlation with the history. I might be looking at real-time trends in relation to history.”
Companies may want to analyze that data using a visualization tool such as Tableau or Zoomdata. But that typically requires whittling the big data set into something more manageable and staging it in a separate server to expose to the analyst. “That data you want to run a query on is so massive that before you can visualize anything, it takes half an hour, if not more,” Ramnarayan says. “How can I paint a picture literally right away, is the key innovation here. And to be able to do that in true interactive times, is the underpinning technology around our product.”
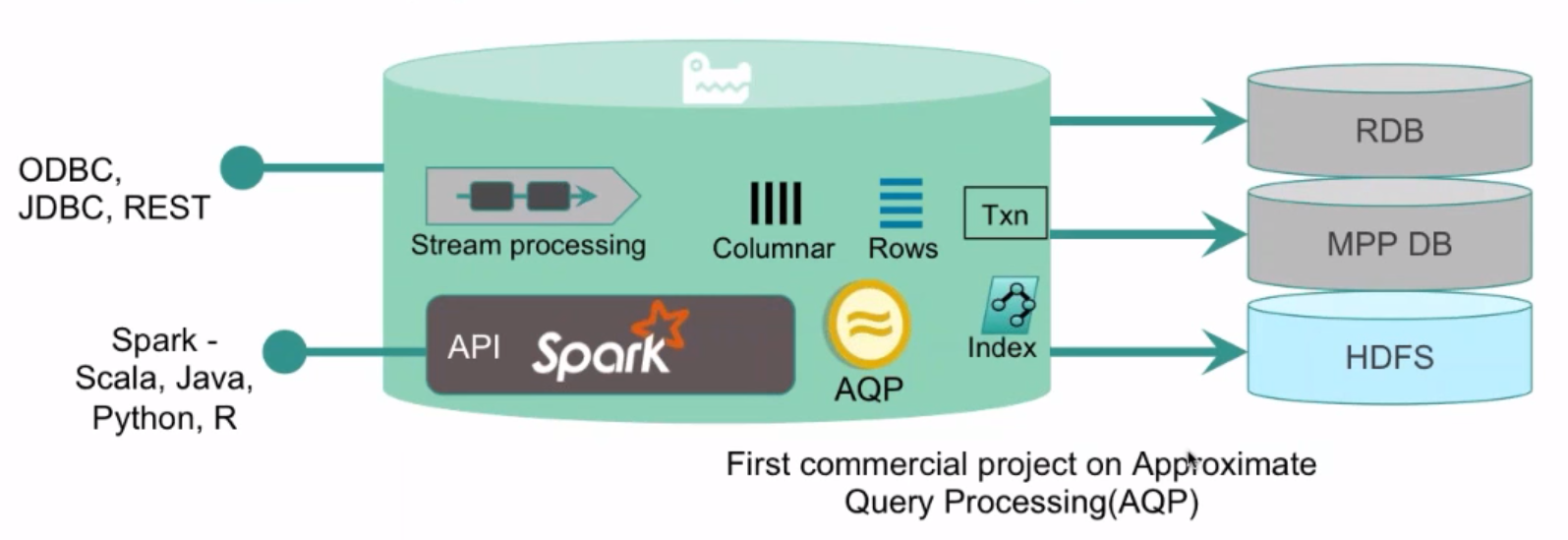
The SnappyData platform gets there by combining what its founders consider two leading products: Apache Spark, which excels at batch-oriented processing and in-memory OLAP processing, and GemFire (and in particular GemFireXD), which excels at high concurrency low-latency data management and OLTP. “You combine the two together, and it’s a single unified cluster that offers streaming analytics, OLTP and OLAP in a single cluster with both Spark and SQL programming models,” says Ramnarayan, who was formerly the chief architect of fast data at Pivotal.
The entire big data industry is struggling with the question of how best to integrate batch, interactive, and streaming analytics. There are many ways to skin this cat. If Spark is your starting point, you can run a combination of Spark and HBase on a Hadoop cluster, or Spark on a NoSQL or NewSQL database like Cassandra or MemSQL. Apache Beam has emerged from Google (NASDAQ: GOOG) as a potential way to unify these analytic approaches, as has Apache Flink, which is emerging to challenge Spark.
In SnappyData’s case, the company is looking to leverage the popularity and ease of development of Spark and Spark Streaming, by combining the Spark stack with the GemFire persistence layer (which it calls Snappy-Store), and stitching it all into a single integrated cluster that delivers on the concurrency and latency requirement, but without the complexity and expense of manually integrating these tools yourself.
The technology was incubated at Pivotal for the past seven months before the principles decided it needed its own footing. With the blessing of Pivotal CEO Paul Maritz, the company set out on its own, with Pivotal as its lead investor, along with GE Ventures and GTD Capital.
The approximate query processing (AQP) capability is one of the unique aspects of the platform—and, not ironically, the one piece of the platform that is not open source. With AQP, SnappyData gives customers the capability to analyze data sets that are many orders of magnitude bigger than what will fit into memory, and to do it with sub-second latency. It’s a new take on archiving and sampling, designed to overcome the gravity of massive data sets and let people work with them. The one caveat: the answers it generates are only approximates, or about 99 percent accurate, the company says.
 “We can be looking at taking the last five year’s worth of data, which could be 50 TB of data, and condense that data into some extremely small subset, say 0.5 percent of the data,” Ramnarayan says. “You keep it in main memory and allow folks to ask arbitrary, interactive analytic class queries on that data, and be able to respond to those questions in less than a second. It’s an approximate answer but the idea is you can get 99 percent accuracy to the question you’re asking.”
“We can be looking at taking the last five year’s worth of data, which could be 50 TB of data, and condense that data into some extremely small subset, say 0.5 percent of the data,” Ramnarayan says. “You keep it in main memory and allow folks to ask arbitrary, interactive analytic class queries on that data, and be able to respond to those questions in less than a second. It’s an approximate answer but the idea is you can get 99 percent accuracy to the question you’re asking.”
AQP gives SnappyData a potentially powerful solution to sell to big banks that are struggling with massive data sets, says SnappyData Co-Founder and President Richard Lamb, who was a co-founder of GemFire before it was acquired by VMware.
“With things like Dodd-Frank, the amount of compliance and regulatory information that has to be kept available has absolutely ballooned,” Lamb says. “Most banks were keeping two years of data. Now the regulation is seven years. We’re taking about going from hundreds of terabytes to petabytes. How are you going to query that information quickly? If you have to scan all that, you’ll never get there.”
SnappyData is seeing that particular problem repeating itself over and over again. “We’re seeing repetitive use cases in banking, because they have to address that issue, and in IoT, where the amount of data is enormous,” Lamb continues. “Customers who are using conventional tools or status quo tools aren’t going to meet that need. There’s an opportunity here with the unique capabilities that AQP brings.”
SnappyData has a beta version of its product out, and several proofs of concept (POCs) running, including one at General Electric, which is running SnappyData along with its Predix software to do analytics on IoT data. The company expects the software to become generally available in early May.
For more info, see the company’s website (www.snappydata.io) or view the introductory webcast (below).
Related Items:
Apache Beam’s Ambitious Goal: Unify Big Data Development
Don’t Overlook the Operationalization of Big Data, Pivotal Says
Leading Solution Providers
















