


March 15, 2016
Why Hadoop Must Evolve Toward Greater Simplicity

(Nadezhda Molkentin/Shutterstock.com)
Developers have been filing the rough edges off Apache Hadoop ever since the open source project started to gain traction in the enterprise. But if Hadoop is going to take the next step and become the backbone of analytics for businesses of all sizes—as many hope it will—then the platform needs to shed some of its technical complexity and embrace simplicity.
There are many ways to parse this call for greater simplicity (which, ironically, is itself a source of complexity). Needless to say, the complexity that appears to be keeping Hadoop back lies primarily in how organizations build, deploy, and manage their Hadoop stacks and the big data apps that run on them.
Reduce the Churn
Take the Hadoop distribution shipped by Hortonworks (NASDAQ: HDP) as an example. Over the past couple of years, HDP customers have been inundated with new technology at a furious pace. Every few months, they were given the option to adopt new releases of Hadoop ecosystem components like Spark, Storm, Hive, and Hbase on top of new releases of Apache Hadoop itself.
While the releases represented real innovation by the various open source projects that make up the Hadoop ecosystem, it proved too much to absorb nonetheless. It “created confusion for customers,” Hortonworks vice president of product management Tim Hall told Datanami.
In response, the company adopted a new release strategy earlier this month that lets customers get off the treadmill of seemingly never-ending upgrades parts. Customers that value stability in their Hadoop clusters above innovation can stick to major releases of Core HDP services (HDFS, MapReduce, and YARN), which will get upgraded once a year, per the Open Data Platform Initiative (ODPi).
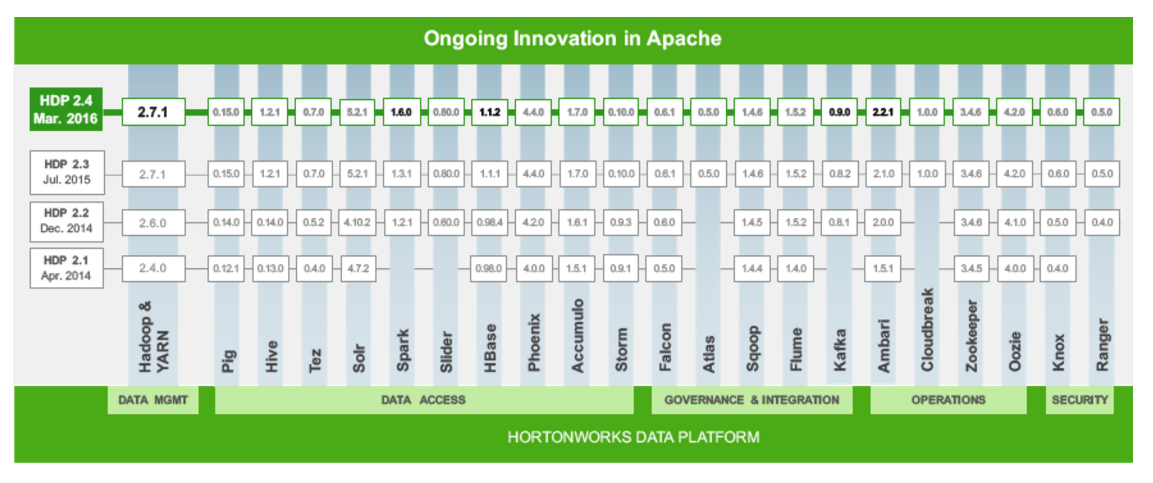
HDP is composed of nearly two-dozen related Apache projects
Meanwhile, customers who will trade some stability for greater innovation can still get that with more frequent updates to Extended HDP services like Spark, Storm, Hive, and HBase. “It eliminates unnecessary upgrade churn where they feel they have to continually adopt the latest and greatest platform when they have a job to do,” Hall says. “People want to run their business.”
The ODPi was founded a year ago to simplify life for software vendors, and to streaming the testing and validation of the various parts that make up the Hadoop stack. What’s interesting is that Hortonworks realized that Hadoop customers had the same concerns. While open source innovation is the lifeblood of the Hadoop ecosystem, it is possible to have too much of a good thing.
Simplify the Menu
The same dynamic that led Hortonworks to pare down on the bit churn led Hadoop as a service provider Altiscale to today’s announcement of the Altiscale Insight Cloud, which essentially provides a superset of the best and most commonly requested Hadoop capabilities around data ingest, transformation, and analysis.
“About 80 percent of our customers and prospects were all doing the same thing on top of Hadoop,” says Altiscale founder and CEO Raymi Stata. “We saw this over and over again. But when you have something raw in Hadoop, there’s lots of different ways to tackle each and every one of those steps.”
Previously, Altiscale would explain–in great gory detail–all the possible ways customers could do things in Hadoop. “We proudly were saying ‘There’s five different interactive Hadoop engines. Here’s six ways to do ETL on Hadoop, and here’s the pros and cons of each,'” Stata says. “We stepped back and realized we weren’t necessarily doing customers a favor by giving them a long menu of pros and cons.”

Altiscale is offering customers a simpler menu of Hadoop options
The new Altiscale Insight Cloud represents the company’s efforts to simplify the options without compromising on functionality. The service is composed of a Web-based user interface that front-ends Oozie (for data ingestion) and Spark SQL (for analysis). Altiscale delivers some of its own basic transformation capabilities via the Web-based UI, but recommends customers write Spark scripts for more complex transformations. (Apache Spark, by itself, is a powerful force for simplification in Hadoop.)
Customers with complex Hadoop needs can still count on Altiscale to help them get it running. But Stata realized that for some customers, less is more.
“We have two classes of customers,” Stata says. “We have Hadoop veterans, people who have Hadoop in production…But increasingly we want to serve the greenfield customers, people who want to get into big data but they haven’t gotten there yet. How do we help them get business value more quickly?”
“I was personally slow to come to that realization,” Stata continues. “I was quite proud of the fact that we had great list of pros and cons and we were very impartial about it. But I realized that it is overwhelming. A lot of times, for newer customers, they’ve never used any of these systems. They can look at pros and cons, but they really didn’t appreciate what they meant and how they applied to their context.”
Data Format Normalization
Striving for simplicity in Hadoop runs counter to the momentum in the world around us. Data volumes are growing geometrically, and much of the data we’re storing in Hadoop is messy and lacks structure. It’s a veritable breeding ground for complexity.
Depending on what you want to do with the data (i.e. crunch it using a SQL engine, run machine learning algorithms, archive it), a Hadoop user may store the data in different data formats, such as Avro, Parquet, or optimized row column (ORC) formats. However, converting the formats consumes considerable amounts of time and CPU power, which are increasingly scarce commodities.![]()
Recently, a new project called Apache Arrow sprung up to solve this problem by providing a standard data format for all in-memory columnar analytic engines running on Hadoop. The technology, which is being adopted by projects like Drill, Impala, Phoenix, and Spark, should speed up data access times by SQL-on-Hadoop engines by one to two orders of magnitude in part by leveraging the single instruction, multiple data (SIMD) capabilities of Intel processors.
Projects like Arrow show how the Hadoop community is responding to complexity by embracing industry standards. The work that went into Arrow is anything but simple, but the project itself actually promotes simplicity by shielding the rest of the industry from technical complexity. The next test is how developers will respond to the vast amounts of machine data emanating from the Internet of Things (IoT).
Real-Time’s Complexity
Hadoop was initially designed to crunch massive amounts of data in batch-oriented MapReduce jobs. The platform did that job well, but as the data volumes grew, customers increasingly wanted to ingest and analyze the data more quickly.
This has spurred the creation of separate big data architectures, such as Apache Kafka, designed to help companies manage the enormous volumes of real-time data. While many Hadoop distributors include Kafka in the binaries they ship to customers, Kafka doesn’t actually run on Hadoop. This has fueled the rise of separate data clusters for Hadoop and Kafka which (you guessed it) increases complexity.
Jay Kreps, who led the design of Kafka at LinkedIn, has told Datanami he hasn’t heard a good argument for making Kafka part of Hadoop proper, and that having separate clusters enables each to do its job in the most effective way. There are efforts to bring Kafka into the Hadoop realm (see: Project Koya), but for now the Confluent co-founder and CEO is resisting those efforts and maintaining a best-of-breed outlook.
With Kafka increasingly at the center of the real-time data universe, it’s led Hadoop distributors to adopt different strategies. Hortonworks’ answer to the IoT question is a new product called Hortonworks Data Flow (HDF). The HDF engine, which runs separately from Hadoop and front-ends Kafka, enables customers to ingest and analyze data at massive scale.
Another option is Kudu, the fast new in-memory storage engine unveiled by Cloudera last year. With Kudu, Cloudera aimed to split the difference between HDFS and HBase in an effort to “dramatically simplify” the increasingly convoluted Hadoop architectures used to support real time use cases, particularly those involving fast-moving machine data emanating from the IoT (where many organizations are employing Kafka). Kudu is currently incubating as an Apache project.
To the folks at MapR Technologies, these efforts just add to complexity. The big data software vendor addressed this complexity by creating a single platform that seeks to address these different needs. The HDFS and NFS-compatible file system, dubbed MapR-FS, is at the heart of the MapR Converged Platform, which houses the company’s Hadoop, NoSQL, and Kafka-compatible software.
Signs In the Clouds
The cloud and virtualization technologies are also poised to help reduce the complexity of Hadoop and to get big data benefits into people’s hands more quickly. Wikibon‘s big data analyst George Gilbert advocates that customers look to hosted Hadoop and big-data services, such as Amazon (NASDAQ: AMZM) Web Services, Google (NASDAQ: GOOG) Cloud Compute, or Microsoft (NASDAQ: MSFT) Azure to solve what he calls Hadoop’s “manageability challenge.”
“Hadoop already comes with significant administrative complexity by virtue of its multi-product design,” Gilbert notes. “On top of that, operating elastic applications couldn’t be more different from the client-server systems IT has operated for decades.”

(bluebay/shutterstock.com)
For years, CIOs have been looking to virtualization tools like VMware to mask operational complexity, and this is another trend worth watching in the big data space. Look to Cloudera, which hired former Google Kubernetes guru Daniel Sturman last June to lead its engineering efforts, for potential breakthroughs here.
There’s also some work being done by folks like MapR, which is now supporting Docker containers with its unified big data distribution. Elsewhere, third-party vendors like BlueData and Denodo are making progress in the data virtualization space by enabling users to (among other things) quickly spin up Hadoop, Spark, Cassandra, and Kafka clusters atop hypervisors or virtualized containers, like Docker. Developers, meanwhile, are looking to frameworks like Cask and Concurrent to simplify programming on increasingly complex big data architectures.
There’s no way to completely avoid complexity within Hadoop or the applications that run on it. The technology and the data itself are moving too quickly for that. But by keeping simplicity one of the goals when designing Hadoop software or services, engineers will be able to mask some of the underlying complexity, thereby enabling regular folks to more easily interact with Hadoop-based systems, and that benefits everybody.
Related Items:
From Hadoop to Zeta: Inside MapR’s Convergence Conversion
Hortonworks Splits ‘Core’ Hadoop from Extended Services
Ex-Googler Now Helping Cloudera Build Hadoop
Leading Solution Providers

















