


March 8, 2016
From Hadoop to Zeta: Inside MapR’s Convergence Conversion

If you’re a regular Datanami reader, you likely know MapR Technologies as a Hadoop distributor, one of the three “pure play” providers alongside Hortonworks and Cloudera. But with its integrated NoSQL database, a modified distributed file system, and an integrated stream processing engine that shipped today—key elements of its so-called Zeta Architecture–it’s become increasingly difficult to put MapR in the Hadoop bucket.
Jack Norris, the company’s SVP of data and applications, redirects the question about what exactly MapR is and has become. “We’re a converged data platform vendor,” says the former CMO, “and Hadoop is a really key aspect of that.”
To be sure, Hadoop is still important to MapR. It still ships Apache Hadoop-related products like Hive and MapReduce, touts binary compatibility with the Hadoop Distributed File System (HDFS), and attends Hadoop events like Strata + Hadoop World. But increasingly, the focus of this San Jose, California company appears to be shifting elsewhere.
For starters, on its website and in marketing materials, it nearly always mentions Spark alongside Hadoop. While the Hadoop phenomenon has long driven demand for MapR, the company is moving above and beyond Hadoop to address what it sees as a bigger opportunity in the evolving big data market.
 That shift is evident in today’s news about the general availability of the MapR Converged Data Platform, which is the new name MapR is giving to its flagship product that combines the Hadoop and Spark bits along with its NoSQL database (MapR-DB), its NFS-and HDFS-compatible file system (MapR-FS) and its Kafka-compatible real-time data processing system (MapR Streams).
That shift is evident in today’s news about the general availability of the MapR Converged Data Platform, which is the new name MapR is giving to its flagship product that combines the Hadoop and Spark bits along with its NoSQL database (MapR-DB), its NFS-and HDFS-compatible file system (MapR-FS) and its Kafka-compatible real-time data processing system (MapR Streams).
The shift in MapR’s messaging isn’t necessarily new. After all, the company has not been shy about discussing the practical shortcomings of HDFS as a high-speed read/write file system, which is why it created its own MapR-FS file system. But taken in whole, it appears the company has reached a tipping point in its shift away from Hadoop messaging, and towards its own data platform, where Hadoop is but one of many components.
Hadoop and Spark “are big consumers of data” on the platform, but they’re “not the only consumers,” Norris says. “This isn’t our first foray into that…It’s been a natural evolution and the market is starting to catch up because they’re realizing where some of the sharp edges of generic Hadoop are.”
With MapR Streams now GA as part of the Converged Data Platform, the company is eager to talk real-time processing and discuss how it fits into macro themes like data convergence. Clearly, the speed at which data is being created today is pushing organizations to ingest and process data and deliver insights more quickly than ever. Projects like Apache Kafka are thriving as a result of the focus placed on real-time processing of never-ending big data streams.
But to MapR’s way of thinking, having a Kafka cluster separate from your big data repository doesn’t make much sense. Instead, the whole shebang ought to be running under the same cluster and pouring data into the same data pool. Norris says convergence is critical to what he calls “real-time decisioning.”
 “It’s not just having some capability to handle streams, but how do you eliminate the latency between the various steps in an application?” Norris says. “That’s why the converged platform is so important, because…you don’t have data duplication across the cluster. You don’t have that latency.”
“It’s not just having some capability to handle streams, but how do you eliminate the latency between the various steps in an application?” Norris says. “That’s why the converged platform is so important, because…you don’t have data duplication across the cluster. You don’t have that latency.”
MapR also announced new security capabilities as part of today’s announcement. The delivery of new access control expressions (ACEs) should simply the process of granting permission to access data stored on MapR’s platform, no matter which engine is being used to process it. As Norris sees it, the new ACEs will replace the disparate access control lists (ACLs) that customers have traditionally used for each data processing engine that plugs into the platform.
Norris says ACE’s Boolean operators provide admins with powerful yet granular control over data access. “I can do things very simply. I can say ‘I want everybody in marketing but Jack to have access to this’ or ‘I want all managers in these three departments, plus this one individual to access this,'” he says. “In the past with ACLs you’d have to construct these various group memberships and have very complex specifications. There was no ‘not’ operator in ACLs.”
The security of data in Hadoop environments is perhaps a bigger problem than people may realize. Norris cites a 2015 study by a North Carolina State computer science professor who found that only 75 percent of data corruption issues in HDFS were not properly identified. What’s more, the organization never knew about more than 40 percent of those cases of data corruption.
“It really calls into question expanding HDFS, extending Hadoop into these mission-critical, systems-of-record types of application with that as the platform,” Norris says. “One of the issues is how do you scale data properly, how do you protect data properly, given this data corruption study?”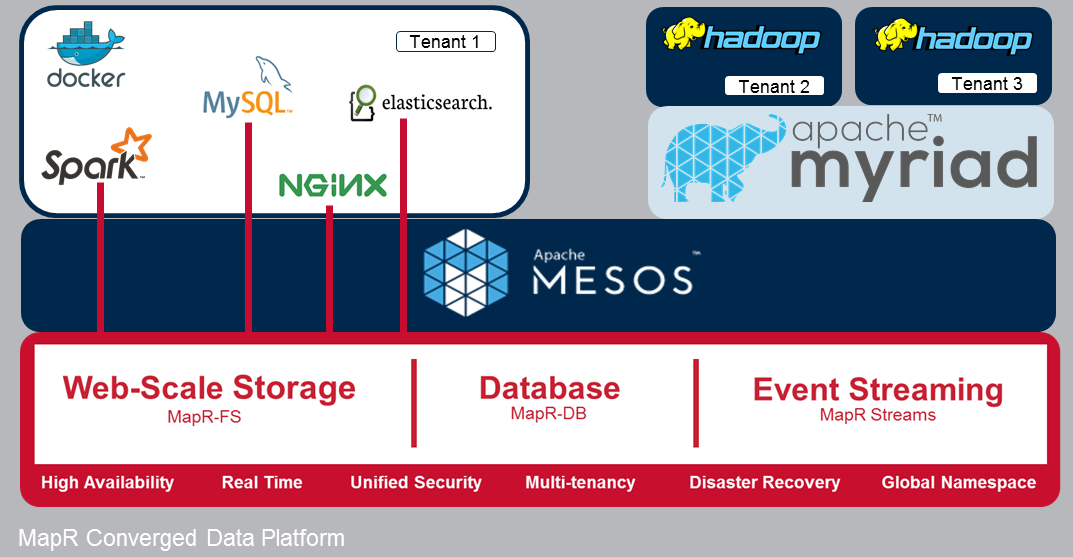
Last but not least, MapR made two announcements around containerization. First it announced that the MapR platform now includes Apache Myriad, which enables Hadoop jobs running under YARN to be managed by Apache Mesos, the AMPLab-developed data center operating system (DCOS) at the center of many containerization initiative. The company also announced a new MapR POSIX Client that will allow the MapR platform to work in Docker environments.
The containerization is part and parcel of MapR’s philosophy of creating a new modern data architecture, which it says is based on the promise of the Zeta architecture. On its website, MapR says the Zeta architecture is not unlike the Lambda architecture that gained fame several years ago, but with some differences.
“The Zeta Architecture is an ideal implementation model that captures the importance of containerization as an inherent part of data center deployments,” says Jim Scott, MapR’s director of enterprise strategy and architecture. “Based on feedback from our customers, MapR offers the only platform that can deliver on the vision of big data containerization.”
To be sure, MapR’s competitors aren’t sitting still, and perceived advantages may not last. Whether you call it a Zeta architecture or a Lambda architecture, there is clearly an emerging requirement among data-driven organization to blend real-time data ingest and awareness with the types of insights that can only be gleaned from deep and ongoing number crunching.
Related Items:
MapR’s Top Execs Sound Off on Hadoop, IoT, and Big Data Use Cases
Project Myriad Brings Hadoop Closer to Mesos
Vendors:
MapR Technologies
Leading Solution Providers
















