


February 23, 2016
Meet Alluxio, the Distributed File System Formerly Known as Tachyon
Today marks the availability of Alluxio 1.0, the first major release of the memory-centric, virtual distributed file system formerly known as Tachyon. The graduate of UC Berkeley’s AMPLab is already being used to manage petabytes of production storage at companies like Barclays, Alibaba, and Baidu, and now its creator, Haoyuan Li, says Alluxio is ready to spread its wings in the bigger big data world.
Li started developing Tachyon four years ago under AMPLab advisors Ion Stoicia and Scott Shenker to address what he saw as gap in the emerging big data architecture stack. “We saw from AMPLab tremendous work in the compute later, which became Apache Spark, and we have done a lot of work in the top resource management layer, which is Apache Mesos,” Li tells Datanami. “What’s missing is the storage layer.”
Most big data storage layers, such as HDFS and Amazon S3, were created to persist data to large banks of hard disks. But Li noted that the throughput of hard disks was increasingly slowly, while the throughput of RAM was increasing exponentially every year and decreasing in cost by 50 percent every 18 months.
Li saw that leaders on Wall Street and Silicon Valley had already embraced memory-centric computing, and decided it was the right time to bring it to the masses. “We believe now is the right time for the rest of the world to embrace this technology in the storage world,” he says.
So what exactly is Alluxio? Li describes the file system as being simultaneously memory-centric, virtual, and distributed. While it’s memory centric and resides primarily in DRAM, it can also work with data sitting on SSDs and hard disks. It’s virtual in that it can sit transparently next to existing file systems, such as HDFS, NFS, and Gluster. And it’s distributed in the sense that it describes a single addressable namespace that sits across a cluster composed of hundreds of nodes.
To Li’s way of thinking, Alluxio is the missing piece of the big data puzzle, the glue that holds together increasingly disparate and disjointed big data architectures.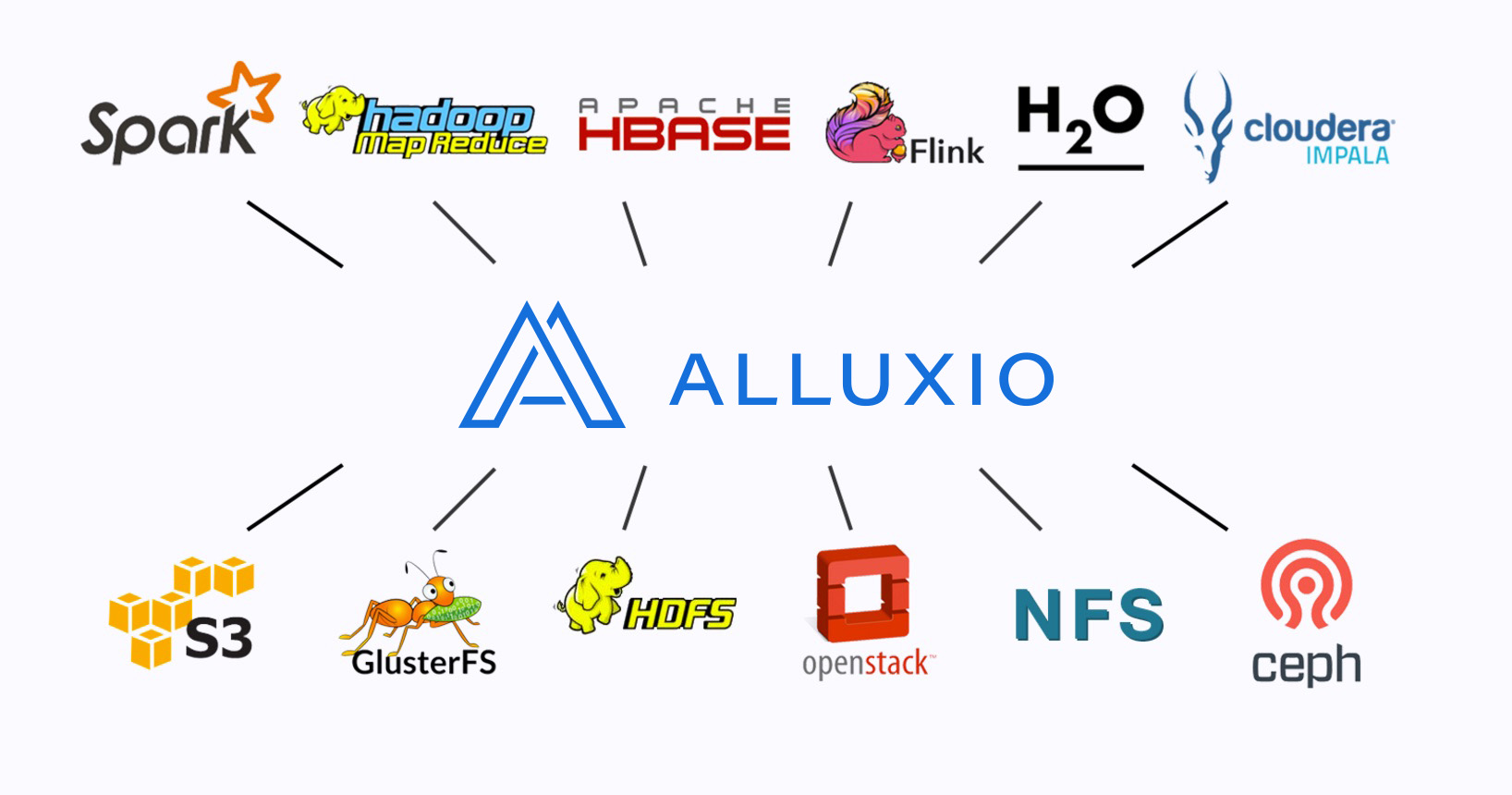
“Alluxio sits in the middle,” says Li. “We become this unified access point which enables different frameworks to access data stored in different storage systems. Beyond the performance benefits, we also enable these frameworks to access the data anywhere. Or, this data stored in any [file system] can be analyzed by any computation framework.”
In that sense, Alluxio breaks the grip that MapReduce has on HDFS. The file system can not only expose MapReduce (or Spark or Flink or H2O or Impala or HBase) to data stored in HDFS, but expose those frameworks to data stored in S3, GlusterFS, NFS, Ceph, and (soon) GPFS.
Stoica, who’s the executive chairman of the Apache Spark development company Databricks, once said that Alluxio is to storage as Internet Protocol (IP) is to the Internet. That’s a powerful endorsement of a technology that some see helping to unify a big data stack that’s becoming increasingly diverse and scattered.
“Alluxio preserves the investment that customer have put into a previous storage systems,” Li says. “They do not need to move the data anymore. They don’t need to do ETL, so all this data movement can be handled by Alluxio efficiently.”
Today marks the release of Alluxio 1.0, which is a significant milestone for any open source project. While Li says whether Alluxio is ready for production will “depend on the organization,” he also notes that the software has seen tremendous improvement over the past two to three years, and that it’s already been put into production at places like Barclays, Baidu, and Alibaba. “More and more companies will feel comfortable deploying Alluxio in a production environment,” he says.
Baidu is using Alluxio to manage upwards of 2 PB of storage on a large cluster that’s used to serve queries to the Internet giant. “Our deployment of Tachyon cluster has already reached 1,000 workers, which is one of the largest Alluxio clusters in the world,” says James Peng, Chief Architect at Baidu. “We are seeing an average 10-fold, and up to 30-fold performance improvement in supporting interactive query system and other types of workloads. This greatly improved the speed in making important business decisions,” Peng says in a press release.
Barclays has also deployed Alluxio, and has seen the latency of its end-to-end workflows decrease from hours to seconds, according to Li. Alibaba and Rackspace are also using Alluxio to bridge analytic applications with the object storage systems they expose to customers.
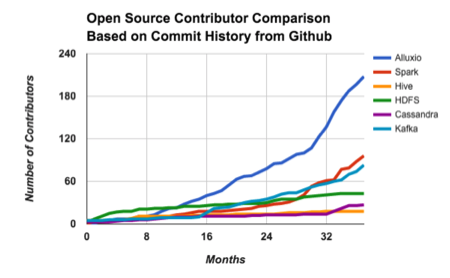
Li says Alluxio has become one of the most popular open source big data projects
Despite the publicity that today’s announcement will bring to Alluxio the technology, Alluxio the company still exists in stealth mode. The San Mateo, California-based company received $7.5 million in funding from Andreessen Horowitz last year, and still has enough cash to fund development, Li says.
It’s not clear what Alluxio’s business strategy will be at this point. Considering that the product is a file system, it’s hard to see a bifurcated commercial open source strategy that offers a bare-bones community version and a supped-up enterprise version. Li confirms that he has talked with Hadoop distributors, but says there is nothing to announce yet.
In any case, fears that Alluxio poses a threat to HDFS are misplaced. “We’re not replacing HDFS,” Li says, “Were in the middle. We’re another layer. Below us is all kinds of persistent storage like Amazon S3, like HDFS, like Google Cloud storage, like EMC storage, like NetApp storage, GlutserFS etc.”
It seems as if Alluxio will be the next AMPLab project to have major impact, just as Spark did before it. “We see it playing a huge disruptive role in the evolution of the storage layer to handle the expanding range of big data use cases,” says Michael Franklin, professor of computer science and director of the AMPLab at UC Berkeley,
While other AMPLab projects like Spark and Mesos have gone on to become Apache Software Foundation projects, for now Alluxio will remain separate. To that end the company today announced that the software will be developed within the Alluxio Open Foundation. “We believe this is the best way for the project to move forward,” Li says. “This is very similar to other very successful projects, like … Docker.”
Related Items:
Tachyon Nexus Gets $7.5M to Productize Big Data File System
AMPLab’s Tachyon Promises to Solidify In-Memory Analytics
Applications:
Complex Event Processing
Technologies:
Frameworks
Sectors:
Retail
Tags:
Alluxio, amazon, AMPLab, Baidu, distributed file system, file system, google, in-memory, Tacyhon, virtual
Leading Solution Providers
















