


January 26, 2016
Data Quality Trending Down? C’est La Vie

One of the biggest impediments to becoming a data-driven organization is tackling the problem of data quality. Data is often too dirty and discombobulated for use in high-end decision-making, and the increasing volume and diversity of data compounds this problem. But according to data quality experts, executives brush off the problem with a choice French phrase or two.
Blazent today unveiled the results of a study commissioned by analysts at 451 Group that looked into data quality. Executives with the company, which develops analytic software used to help large IT departments take better stock of their assets and use that to make better decisions, knew from experience that data quality is a big issue facing their clients. But they wanted to gather some empirical data to help drive their message home.
451 Group’s survey of 200 leading IT executives, which is called the 2016 State of Enterprise Data Quality, yielded some insights into the state of data quality across industries, and identified some puzzling contradictions in executive viewpoints that could provide a foothold for change.
For starters, 451 Group found only 40 percent of respondents are “very confident” in their organization’s data quality management (DQM) practices and the quality of their data.
Additionally, more than 80 percent of survey respondents believe their data quality to be better than it actually is (451 Group found a way to measure it by proxy), despite the fact that nearly every company surveyed had a DQM plan or project in place.

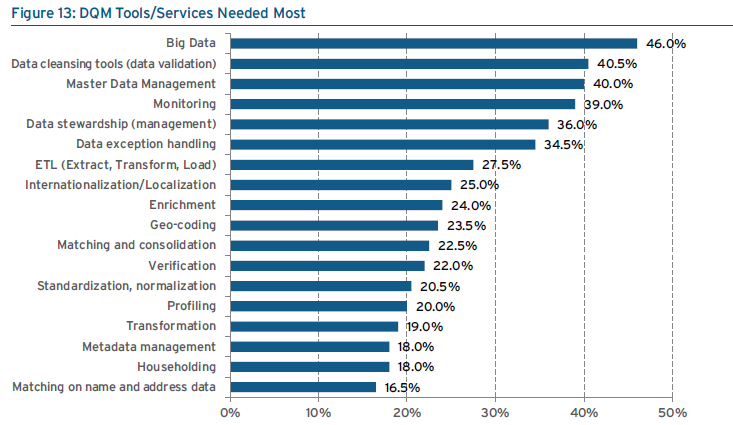
source: 451 Group
Carl Lehmann, the senior 451 analyst who was the lead author of the report, says the survey indicate that IT execs “are pretty casual about their attitude to data quality and data quality management in their enterprise,” Lehmann tells Datanami. “It’s sort of a laissez faire attitude. They think the data they use in day to day operations is OK.”
Despite the humdrum state of data quality, IT executives show they know how important data quality is to their companies. In the survey, 65 percent of respondents believe that 10 percent to 49 percent of business value can be lost due to poor data quality, while 29 percent said they thought that more than 50 percent of business value can be lost.
There is clearly a cost to bad data, and IT execs are aware of it, but they just aren’t doing anything about it. That disconnect surprised Lehmann. “That kind of flies in the face of having a laissez faire attitude to data quality and DQM,” he says. “If it has such a dramatic impact, then why such a casual approach to understanding or improving upon data quality and DQM in the enterprise?”
Lehmann has some thoughts on the source of the problem, and it lies in the relationship between the IT department that has traditionally been in charge of master data management (MDM) and DQM initiatives, and the business people who are charged with actually using the data in support of the business.
“The responsibly for data capture and curation and the responsibility for its quality for use in enterprise is separated,” Lehmann says. “Mostly it’s the IT organizations who are responsible for quality, but the systems that capture and curate data are not part of the purview of the IT organization.”
That sounds about right to Nenshad Bardoliwalla, the co-founder and chief product officer at Paxata, the developer of self-service data preparation tools for big data environments like Hadoop and Spark. But that doesn’t it has to be that way.
“If you look at the current state of the enterprise, the only way that people have traditionally been able to create high-value information is to go through their IT department,” Bardoliwalla tells Datanami. “But their IT departments have been stuck with a hodge-podge of legacy tools from legacy vendors that were acquired from a variety of acquisitions that they did, designed only for IT people, designed only for relational databases, designed to allow those IT people to manually go through the process of creating information.”
source: 451 Group
The only way to tackle the problem of poor data quality impacting day-to-day decision-making is to give line-of-business people the capability to do their own data prep, of which cleansing is a key part, he argues. After all, these data analysts, sales managers, and marketing directors have come to expect that level of self-service capability since Tableau Software set off the self-service BI revolution 10 years ago, he says.
“The [data quality problem] is getting worse. It’s getting much, much worse!” Bardoliwalla says. “It’s gotten much worse because the variety, volume, and velocity of data that’s being thrown at the traditional tools is completely discrepant with what those tools are actually capable of handling.”
However, that’s not to say that every piece of data has to be cleansed to perfection, he adds. People must learn to be more flexible in their DQM and MDM initiatives, which for most organizations means moving away from the rigid, top-down attempts to obtain and maintain that “golden record.” (However, companies in highly regulated industries, like financial services, must keep more stringent definitions of data quality, or risk paying massive fines.)
“If you look at data quality for data quality’s sake, if you just say, ‘Oh our data is bad,’ it’s not going to move the needle at all,” Bardoliwalla says. “Where you have to go and attack data quality is where it ties to the mission-critical objectives of an organizations. Is it preventing them from making money? Is it costing them more than they should? Is it exposing them to the potential of going to jail? If your data quality is not tied to one of those three things, then absolutely executives won’t care about it.”
On January 27 Paxata unveiled the Winter Release of its flagship data prep tool, which employs machine learning technology to automate much of the work of integrating, cleansing, transforming, and enriching data in support of analytic initiatives. Among the new features is a new capability to infer and fill in missing values, which will be useful for standardizing things like names (it doesn’t work with numbers). It also offers full support for the Hadoop distribution from Hortonworks (NASDAQ: HDP). Previously it was only certified with Cloudera.
Related Items:
How to Talk to Your Boss About Needing Better Data Quality Tools
Is Bad Data Costing You Millions?
What Lies Beneath the Data Lake
Technologies:
Middleware
Leading Solution Providers
















