


December 2, 2015
ScaleOut Pushes the Bottleneck in Latest IMDG Update

Each computer architecture, by definition, has a bottleneck that prevents it from performing faster. With the latest release of its in-memory data grid (IMDG) for performing data-parallel analytics, ScaleOut Software has continued to push the bottleneck out of the CPU and put it firmly into the network’s lap.
The latest release of ScaleOut StateServer version 5.4 represents the work ScaleOut Software did to eliminate instances of lock contention when running upon multi-core CPUs. As ScaleOut’s CEO and founder Dr. William L. Bain explains, the work was done in conjunction with testing StateServer on a 160-core IBM Power8 system.
“We were able to get our code up and running on Power8 very rapidly then immediately hit a wall with not being able to take advantage of all the cores,” Bain tells Datanami. “We just put our heads down and spent the better part of a year identifying and resolving the bottlenecks and incorporating the latest technology to do that.”
The advent of many-core CPUs has helped chipmakers like IBM (NYSE: IBM) and Intel (NASDAQ: INTC) keep pace with Moore’s Law. While the latest Power and Xeon processors provide plenty of computational oomph, relatively few applications are actually able to take full advantage of it.
“If you take code written from 2005 and run it in on a large multi-core system, you’d see two or three cores would be busy and the rest would be idle,” Bain says. “So we had to go back and re-think all of the implementations to eliminate lock contention. Data sharding is the principal technique to overcome that bottleneck.”
ScaleOut has always used data sharding in some manner in its IMDG, which are typically spread across clusters ranging from a few dozen nodes to a few  hundred. For example, sharding is critical for enabling the client cache (which Bain describes as a “big bag of recently accessed structures”) to be accessible to different threads running within the client application.
hundred. For example, sharding is critical for enabling the client cache (which Bain describes as a “big bag of recently accessed structures”) to be accessible to different threads running within the client application.
“If you can shard that client cache so that different threads running in the client application access different parts of the client cache without contention,” Bain says, “you can get much better multi-thread utilization of a client application.”
A slightly different approach was needed to implement data sharding on a scale-up architecture, such as the large symmetric multi-processor (SMP) servers that IBM is known for building. Bain and his firm developed those sharding techniques, and the result is a 2x to 4x improvement in performance for ScaleOut-based IMDGs running on SMPs, he says.
The work stemmed from ScaleOut’s work with IBM and Power8, but it applies to any multi-core architecture, including X64. “With this multi-core optimization in version 5.4, we can dramatically reduce the number of servers in the cluster, because we can get a lot more work out of each server,” he says.
This brings other benefits too. A typical 20-node deployment may encompass 1TB of memory for the IMDG to execute its data-parallel analytics upon, and users can now keep more of those cores working upon data residing in memory, instead of moving the data off to other systems. The more data customers can keep off the network, the better.
“The real value of this approach is that the computing is being done within the server, without moving the data,” he says. “The number one value from our architecture is data locality. You don’t find that to be the case in the data warehouse world, where they routinely move data, because they’re not worried about keeping the latency as low as it can be.”
ScaleOut may have popped the balloon of one bottleneck—multi-core CPUs going to waste—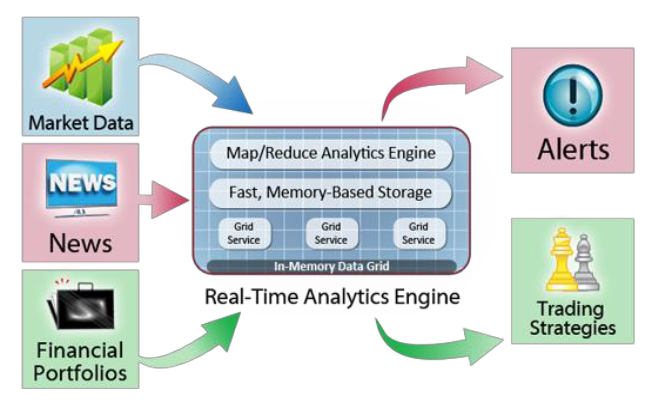 but more bottlenecks loom. “The technologies are like horses in a race,” Bain says. “At this point, the horse that’s lagging is the network bandwidth horse. People need to start moving to 10GbE to get that bottleneck out of the way and move it back somewhere else.”
but more bottlenecks loom. “The technologies are like horses in a race,” Bain says. “At this point, the horse that’s lagging is the network bandwidth horse. People need to start moving to 10GbE to get that bottleneck out of the way and move it back somewhere else.”
When the company started over 10 years ago, 1GbE networks were quite rare, but the CPUs were the bottleneck in most real-world implementations, so the company did all kinds of things to optimize processing.
These days, companies are relatively rich with processing power (even if they can’t access all the capabilities their multi-core CPUs can offer). But thanks to the big data boom, they are reaching the limits of what their networks can perform. Moving to 10GbE may not be enough, with InfiniBand and 100GbE available. “Anything you can do to minimize network overhead, the better,” Bain says.
ScaleOut Software has over 420 deployments of its core IMDG technology over the past decade, including about 10 percent of the Fortune 500. The primary use case for its IMDG is performing operational intelligence to extract insight upon fast-changing data on live systems, whether they’re used in cable TV, healthcare, financial ![]() services, logistics, ecommerce, or the payment processing industries. The company’s ScaleOut ComputeServer and ScaleOut hServer provides operational intelligence and MapReduce functionality, respectively.
services, logistics, ecommerce, or the payment processing industries. The company’s ScaleOut ComputeServer and ScaleOut hServer provides operational intelligence and MapReduce functionality, respectively.
ScaleOut also unveiled yesterday a new release of its Object Browser, which is used to visualize data held in the IMDG. The new Browser can handle many more objects–measuring into the millions, Bain says. Lastly, the company announced compatability with Microsoft‘s Windows Server AppFabric (WSAF) Caching APIs, thereby enabling customers to move off the AppFabric to ScaleOut’s IMDG.
Related Items:
Streaming Analytics Ready for Prime Time, Forrester Says
In-Memory Computing Is the Key to Real-Time Analytics
ScaleOut Ships Its Own MapReducer for Hadoop
Leading Solution Providers
















