


August 4, 2015
Yahoo Casts Real-Time OLAP Queries with Druid

Yahoo is in the process of implementing a big data tool called Druid to power high-speed real-time queries against its massive Hadoop-based data lake. Engineers at the Web giant say the open source database’s combination of speed and usability on fast-moving data make it ideal for the job.
Druid is a column-oriented in-memory OLAP data store that was originally developed more than four years ago by the folks at Metamarkets, a developer of programmatic advertising solutions. The company was struggling to keep the Web-based analytic consoles it provides customers fed with the latest clickstream data using relational tools like Greenplum and NoSQL databases like HBase, so it developed its own distributed database instead.
The core design parameter for Druid was being able to compute drill-downs and roll-ups over a large set of “high dimensional” data comprising billions of events, and to do so in real time, Druid creator, Eric Tschetter wrote in a 2011 blog post introducting Druid. To accomplish this, Tschetter decided that Druid would feature a parallelized, in-memory architecture that scaled out, enabling users to easily add more memory as needed.
Druid essentially maps the data to memory as it arrives, compresses it into a column, and then builds indexes for each column. It also maintains two separate subsystems: a read-optimized subsystem in the historical nodes, and a write-optimized subsystem in real-time nodes (hence the name “Druid,” a shape-shifting character common in role playing games). This approach lets 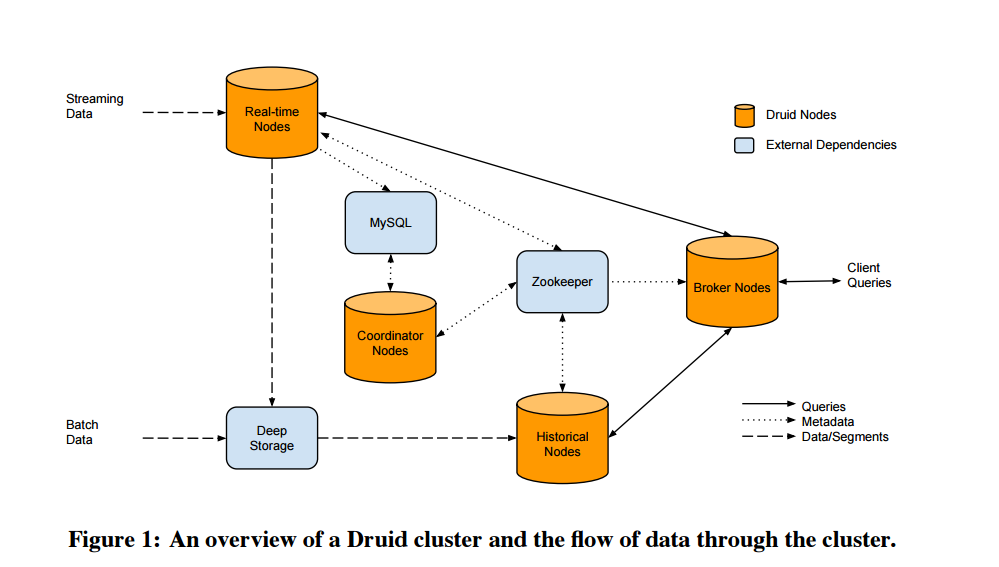 the database query very large amounts of historical and real-time data, says Tschetter, who left Metamarkets to join Yahoo in late 2014.
the database query very large amounts of historical and real-time data, says Tschetter, who left Metamarkets to join Yahoo in late 2014.
“Druid’s power resides in providing users fast, arbitrarily deep exploration of large-scale transaction data,” Tschetter writes. “Queries over billions of rows, that previously took minutes or hours to run, can now be investigated directly with sub-second response times.”
Metamarkets released Druid as an open source project on GitHub in October 2012. Since then, the software has been used by a number of companies for various purposes, including as a video network monitoring, operations monitoring, and online advertising analytics platform, according to a 2014 white paper.
Netflix was one of the early companies testing Druid, but it’s unclear if it implemented it into production. One company that has adopted Druid is Yahoo, the ancestral home of Hadoop. Yahoo is now using Druid to power a variety of real-time analytic interfaces, including executive-level dashboards and customer-facing analytics, according to a post last week on the Yahoo Engineering blog.
Yahoo engineers explain Druid in this manner:
“The architecture blends traditional search infrastructure with database technologies and has parallels to other closed-source systems like Google’s Dremel, Powerdrill and Mesa. Druid excels at finding exactly what it needs to scan for a query, and was built for fast aggregations over arbitrary slice-and-diced data. Combined with its high availability characteristics, and support for multi-tenant query workloads, Druid is ideal for powering interactive, user-facing, analytic applications.”
Yahoo landed on Druid after attempting to build its data applications using various infrastructure pieces, including H![]() adoop and Hive, relational databases, key/value stores, Spark and Shark, Impala, and many others. “The solutions each have their strengths,” Yahoo wrote, “but none of them seemed to support the full set of requirements that we had,” which included adhoc slice and dice, scaling to tens of billions of events a day, and ingestion of data in real-time.
adoop and Hive, relational databases, key/value stores, Spark and Shark, Impala, and many others. “The solutions each have their strengths,” Yahoo wrote, “but none of them seemed to support the full set of requirements that we had,” which included adhoc slice and dice, scaling to tens of billions of events a day, and ingestion of data in real-time.
Another property of Druid that caught Yahoo’s eye was its “lock-free, streaming ingestion capabilities.” The capability to work with open source big data messages busses, like Kafka, as well as working with proprietary systems, means it fits nicely into its stack, Yahoo said. “Events can be explored milliseconds after they occur while providing a single consolidated view of both real-time events and historical events that occurred years in the past,” the company writes.
As it does for all open source products that it finds useful, Yahoo is investing in Druid. For more info, see the Druid website at http://druid.io.
Related Items:
The Real-Time Future of Data According to Jay Kreps
Glimpsing Hadoop’s Real-Time Analytic Future
Druid Summons Strength in Real-Time
Technologies:
Middleware
Sectors:
Retail
Leading Solution Providers
















