


April 22, 2015
A Shoebox-Size Data Warehouse Powered by GPUs

When it comes to big data, the size of your computer definitely matters. Running SQL queries on 100 TB of data or joining billions of records, after all, requires horsepower. But organizations with big data aspirations are increasingly able to satisfy their data processing needs with much smaller computers, thanks to the dense power boost provided by GPUs.
Graphic processing units were initially adopted by gamers to drive graphics in video games (hence the acronym). As the game developers delivered ever-richer and more life-like visual displays, they increasingly expected their customers to have the multi-thousand-core GPUs from the likes of Nvidia to power the math behind the stunning vector graphics. Without a screaming fast GPU loaded into your gaming PC, the games were slow, pixelated, and totally lame.
At some point, the HPC community dove headlong into the GPU world and began leveraging graphic chips from Nvidia, and then Intel, as processing multipliers to boost the throughput and capacity of supercomputers. The transformation was so complete that most of today’s most powerful supercomputers have as many GPUs as traditional CPUs, and that balance is shifting toward even more Nvidia Teslas and Intel Phis loaded into next-gen supers.
The big data analytics world hasn’t been as quick to latch onto exotic hardware such as GPUs and field programmable gate arrays (FPGAs) as the HPC world, with a few exceptions. Indeed, most of today’s big data software, from Hadoop to various types of NoSQL databases, have gravitated to the standard stack of Linux running on Intel X86 processors. (At least today’s Hadoop does run on modern 64 bit processors.)
But as big data workloads increasingly come up against the processing wall of traditional CPUs architectures, there are rumblings of change within the community, and some entrepreneurs are increasingly looking to GPUs (and FPGAs) for solutions.
One of those startups leveraging GPUs for big data analytics is a company called SQream Technologies. Based in Israel, SQream developed a column-oriented database designed to leverage the power of Nvidia GPUs to run data warehousing workloads with a fraction of the computing hardware than would traditionally be required.
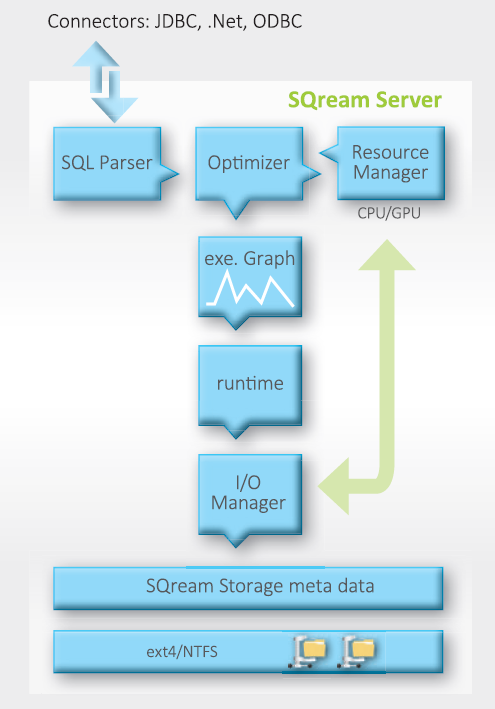
The SQream DB architecture.
According to SQream CEO and founder Ami Gal, customers can get the same analytical performance out of a $35,000 Dell server equipped with GPUs and the SQream DB as they can with a million-dollar server running analytical database from Teradata, Oracle, and IBM. “You don’t need to do data massaging, create cubicles, run indexes, or play with in-memory stuff,” Gal tells Datanami. “What you get is a standard database that can scale to very large numbers on a very small hardware footprint. What you get is a data warehouse in a shoebox.”
Best of all, Gal says, the SQream DB uses the same old ASNSI SQL that millions of analysts are already familiar with–the same SQL that’s generated from your standard business intelligence tools from TIBCO Spotfire, QlikTech, and Tableau Software. “It’s pretty clear to us that most of the big data projects are still done with SQL,” Gal says. “Even if they do it on a Hadoop cluster, they’re trying to find ways to run SQL layers on top of it. For me it’s very clear that SQL is still around, big time. It is in every corner you look.”
The core intellectual property in SQream lies in how the developers leverage the GPUs. The company used Nvidia’s CUDA programming language to parallelize a single SQL queries into thousands of smaller queries that run on each core in the GPU. After the queries run on the 6,000 cores (for a single GPU, or 12,000 for a dual-GPU setup), SQream DB aggregates the results together and presents the result back to the user.
“Our special sauce is how we do the pre-processing, the decompiling,” Gal says. “We actually wrote a complete compiler to do that. We wrote a common database designed specifically for GPUs, for highly parallelized, single instruction, multiple-processor architecture, like the GPUs, from the ground up. It was pretty challenging but this is how we do it.”
Because SQream can bring so many cores to bear on the problem, it doesn’t pay the performance price when massive compression is used, Gal says. Huge joins that would typically take 70 to 80 TB of storage takes less than 1/10 of that in actual storage requirements. Each 2U server running SQream DB can handle about 100 TB of raw data, but use only about 10TB of actual nearly storage.
![]() The company claims its GPU-powered database can run SQL queries up to 100 times faster than traditional data warehouses. “We’re enabling smaller companies, or budget-limited companies, to actually solve big data problems with less money,” Gal says. “And it usually runs much faster than the competition. We’re not in the market for doing stuff in nanoseconds or milliseconds. But if you’re doing a join between 300 billion and 30 million records, it takes you seconds as opposed to hours and minutes coming from the competitors.”
The company claims its GPU-powered database can run SQL queries up to 100 times faster than traditional data warehouses. “We’re enabling smaller companies, or budget-limited companies, to actually solve big data problems with less money,” Gal says. “And it usually runs much faster than the competition. We’re not in the market for doing stuff in nanoseconds or milliseconds. But if you’re doing a join between 300 billion and 30 million records, it takes you seconds as opposed to hours and minutes coming from the competitors.”
Since SQream DB began shipping in late 2014, it’s been adopted by companies in financial services, cybersecurity, telecommunications, and genomics. Yesterday the company unveiled a new product designed specifically for companies in the genomics field. Called GenomeStack, the software features SQream DB under the covers and is designed to help researchers manipulate and query files stored in the BAM format.
GPUs aren’t turning the big data world on its head, at least not yet anyway. But if solutions such as SQream find traction, you can bet that more customers will be looking to GPUs to accelerate their big data workloads.
Related Items:
FPGA System Smokes Spark on Streaming Analytics
GPU-Powered Terrorist Hunter Eyes Commercial Big Data Role
MIT Spinout Exploits GPU Memory for Vast Visualization
Leading Solution Providers
















