


April 21, 2015
WANdisco Opens Up the Dance Floor Beyond Just Hadoop
WANdisco today launched WANdisco Fusion, its new flagship data replication product for Hadoop. The new software delivers real-time replication of data not just among plain-vanilla Hadoop clusters, but also among HDFS-compatible file systems, such as those used by MapR Technologies, EMC Isilon, Amazon S3, and Teradata.
WANdisco made its name in the Hadoop world with NonStop Hadoop, which provided very fast and reliable data replication for enterprises like banks that required strong high availability and disaster recovery capabilities with its Hadoop clusters.
While it was powerful and widely adopted in production Hadoop settings, the software was fairly invasive and had its limitations. For starters, since NonStopHadoop installed on the NameNode (the single-source-of-failure that had to be bolstered with WANdisco’s “consensus node” appraoch), technicians had to be very careful to get their NonStop Hadoop implementations right.
Any tweaks made to the underlying Hadoop cluster or NameNode configuration could throw replication, which necessitated a deep level of certification work between WANdisco and the Hadoop distributors. Because of this work, WANdisco focused its certification work with the major open source players who used HDFS: Cloudera and Hortonworks.
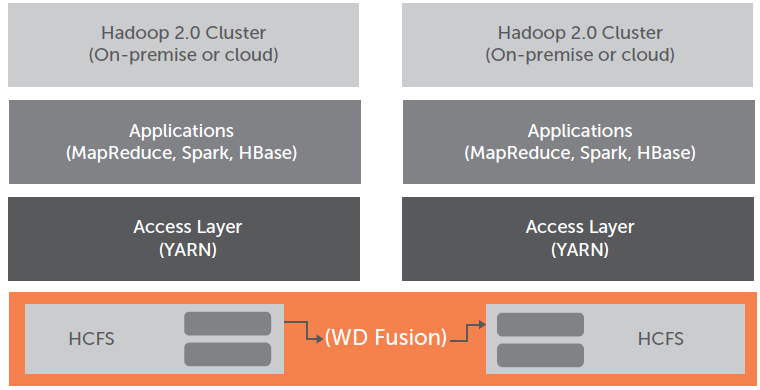
WANdisco Fusion introduces a simpler architectural diagram.
The company abandoned this invasive approach with WANdisco Fusion (WDF). While WDF uses the same underlying data replication engine, called DConE, it installs the technology on a server adjacent to the Hadoop cluster it’s working with instead of on the NameNode itself.
This makes WDF an evolution of the NonStop Hadoop product, says Randy DeFauw, director of product marketing for the San Ramon, California company. “It’s still active-active replication, but we’re sitting at a much higher level in the Hadoop stack,” DeFauw says. “Instead of working deeply at the NameNode level, it actually works as a proxy application to the Hadoop file system.”
From a user’s perspective, WDF sits between HDFS and the application they’re using. The only change required to use WDF is to change the HDFS access path via the URI setting. “Architecturally we look a lot like any other Hadoop application that’s sitting outside of a Hadoop cluster,” DeFauw says.
Moving the DConE replication engine up the Hadoop stack brought several benefits. For starters, it greatly simplifies the installation and eliminates the need for deep technical certifications with the Hadoop distributors. Customer can get it up and running in a matter of hours, and begin replicating data from one cluster to another.
Secondly, WDF supports more Hadoop-compatible file systems than just plain vanilla HDFS. “Previously our product was certified on Hortonworks and Cloudera,” DeFauw says. “Now we’re able to work on those as well as EMC Isilon storage, MapR, Amazon S3 and Teradata.”
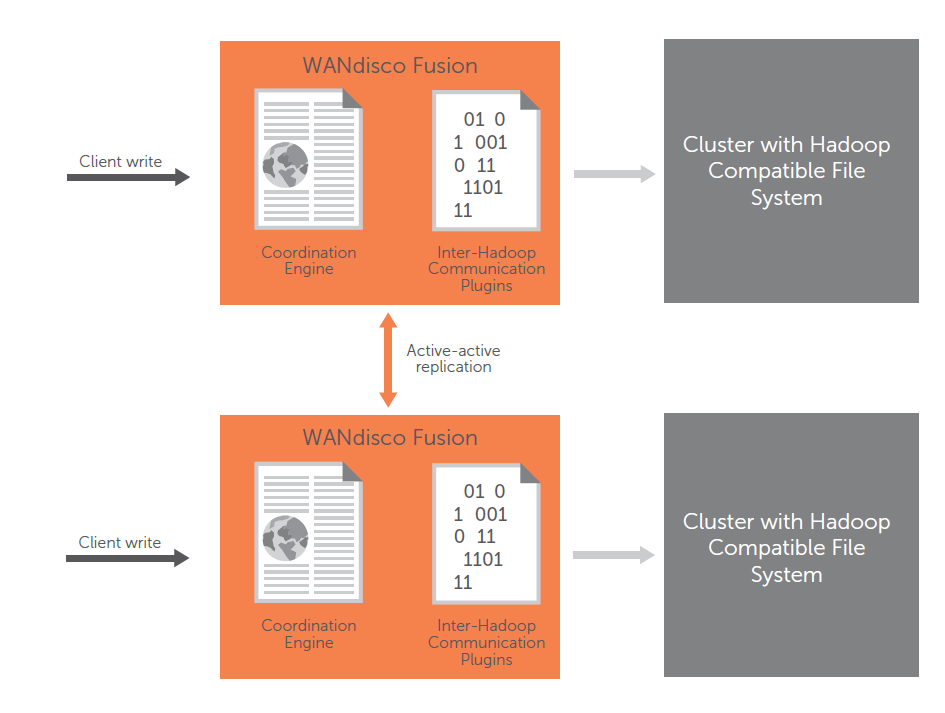
WDF supports active-active replication
While these vendors don’t use HDFS, they have HDFS-compatible file systems, including NFS in MapR’s case and object storage systems in EMC and Amazon’s case. You can expect WANdisco to support some of the OpenStack object storage systems in the near future.
Mixing up the backend storage enables WDF customers to create and use a single global namespace for all of their data storage needs, says WANdisco CEO David Richards.
“We saw an opportunity not to rely just on Hadoop, but to create a simple global namespace across a mixed variety of storage,” Richards says. “Really that’s what WDF is designed to do: To be completely non-invasive, to work with any HDFS-compliant file system without any modifications to the underlying file system, and to bring it all together into a single global namespace.”
While some Hadoop distributors may want Hadoop to serve as the be-all, end-all data lake for every piece of data under the sun, that’s likely not going to be how big data storage evolves, Richards says.
“What we’re seeing with the banks, for example, is Hadoop is good for fast-flowing data, but it’s not as dense as it might be, so for archival purposes, a lot of banks run Isilon,” he tells Datanami. “I can have different storage platforms for different use cases, and…it enables you to run one single name space across all underlying storage, no matter what it is.”![]()
WANdisco cites Wikibon’s recent Big Data Analytics Survey, which found that 70 percent of big data early adopters have more than one cluster. While Hadoop is gaining ground among enterprises, clearly it’s not the only game in town, says Jagane Sundar, CTO for WANdisco and the primary architect for WDF.
“Hadoop is spurring innovation in the traditional enterprise vendors as well,” he says. “We find places where S3 is excellent. We find places where Isilon is outstanding. HDFS excels in some places. Our customers recognize that and our product helps customer manage these disparate storage solutions in a strongly consistent manner with very little administrative overhead.”
WDF also enables Hadoop customers to use their clusters more effectively, whether they’re running on-premise or the cloud. “You can run different applications [on different clusters] for performance reasons to take advantage of different types of hardware,” DeFauw says. “Each cluster can potentially have a different hardware profile to maximize use of things like Spark for in-memory analytics.”
NonStop Hadoop featured “active-active” data replication, and that’s a theme that WANdisco is hammering with WDF too. In many situations, customers will have a secondary Hadoop cluster that serves as backup to the production system. With WDF, both the production and the secondary clusters—which might be Hadoop or an Isilon or Teradata cluster–are available to run workloads.
And just as WDF can move data, it can also smooth Hadoop upgrades and migrations, between on-premise cluster or the cloud. “One of the big pieces of market feedback we got was just moving from one version of the same distro to another version was a giant exercise for customer,” Sundar says. “WDFusion insulates customers from that problem also.”
Related Items:
The Land of a Thousand Big Data Lakes
Battling Big Data’s Tribal Knowledge Problem
WANdisco Plots Growth Solving Hadoop’s NameNode
Leading Solution Providers
















