


March 31, 2015
Battling Big Data’s Tribal Knowledge Problem

One of the practical data-related problems that people struggle with today is just finding the right piece of data hidden among various sources. If you’ve ever asked for a specific data set, only to be told “Ask Suzy in accounting,” you’ve experienced the tribal knowledge problem. The thing is, “Ask Suzy in accounting” doesn’t scale with big data.
The tribal knowledge problem affects all sorts of organizations using all sorts of techniques. No matter whether you use Hadoop, Teradata, or relational database management systems, there’s a level of obscurity surrounding data sources that confounds your ability to get the right piece of data.
Traditional master data management (MDM) and data governance techniques propose to solve the problem with a top-down approach and rigid categorization. But the speed at which data types and data sources are changing confounds this approach, says Satyen Sangani, who worked in Oracle’s data warehouse division before co-founding Alation, which today came out of stealth with a new product aimed at closing the tribal knowledge gap.
“While everybody is focused on problem of how to visualize the data and how to make the compute go faster and how do we store the information more efficiently, we’ve seen little about the fact that there’s just so much more data out there,” Sangani tells Datanami. “There’s a fundamental information relevance problem. How do you get the data when you need it, how do you sort through it, how do you filter down the data to get what you’re actually looking for? That’s fundamentally a problem that we see our customers deal with.”

Sorry Suzy, but you just don’t scale
Alation’s solution to the problem is to leverage the power of machine learning to automatically map the access paths that people naturally take to access data. Its software installs an agent in various data sources that access logs and certain metadata components to ascertain what pieces of data are most popular; it also takes a sample of the actual data for indexing purposes. It’s sort of like Google‘s PageRank algorithm, but applied within a customer’s own data environment.
This is a novel approach that yields powerful insights for search and discovery of data, Sangani says. “When you go into database system like Oracle or Teradata, it doesn’t tell you any of the information about who’s using it, when it’s used, what’s touching it, and what that data goes to,” he says. “All that information has to be effectively machine learned by either accessing the query logs or by more fundamentally asking people.” In other words, go see Suzy in accounting.
By understanding the larger context surrounding the data, Alation can help business analysts, IT administrators, or business managers figure out which data sets are the most pertinent for their needs. In that manner, it’s sort of like Yelp for business data, Sangani says.
“Yelp gives you a response and says ‘Here’s not only the result, but the reason the result is right is because 15 other people used this data, it was last refreshed on this date, there are 400 other people who are subscribing to this data, and there are 25 reports hanging off it,'” he says. “We give you a ton of context and it’s really that context that makes the search hum.”
 In addition to building the core search and discovery foundation, Alation’s Postgres-based platform includes a collaboration layer that allows people to work together to better understand and annotate data sources as they explore them. In this manner, Alation hopes to engender more strategic data governance and management initiatives organically at customer sites, as an offshoot (or continuation of) the tactical application of search and discovery.
In addition to building the core search and discovery foundation, Alation’s Postgres-based platform includes a collaboration layer that allows people to work together to better understand and annotate data sources as they explore them. In this manner, Alation hopes to engender more strategic data governance and management initiatives organically at customer sites, as an offshoot (or continuation of) the tactical application of search and discovery.
Alation is coming out of stealth today, but it already has a fairly impressive list of early adopters, including EBay, MarketShare iHeart Media, Square, and Inflection. At Ebay, the product is used by business analysts charged with analyzing petabytes of data sitting across multiple systems.
“What they [Ebay] ended up doing was using Alation in order to present not just the data and the context around the data, but also as a knowledge management tool to say, ‘Hey for calculating churn, here are the ways you can do it,'” Sangani says. “So it really helps the analysts accelerate their work process and work product by helping them find the information and getting them to the data sets and the answers they need.”
Currently Alation supports Hadoop (including HDFS and Hive); data warehouse platforms such as Teradata, Oracle, and IBM’s Netezza; and most relational database systems. The has NoSQL data stores on its roadmap, as well as possibly object-based file systems.

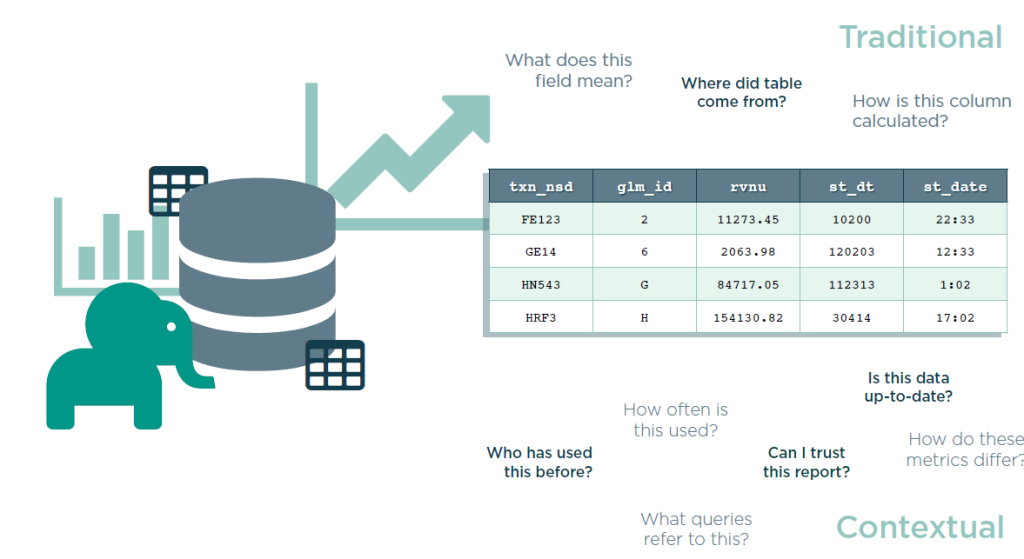
Alation builds a sort of graph that maps the use of data in an enterprise
Sangani doesn’t believe that machines can take the place of humans for data curation. MDM initiatives will continue. But machines can augment humans and make them and the MDM initiatives more powerful and successful.
“The problem with MDM is it’s effectively all top down all human curation,” Sangani says. “Our observation has been that’s just not scalable. It never was scalable previously, which is why I founded this company. But it works even less now.
“If you think about the amount of data that’s being generated, that’s one factor. But the data is also becoming more complicated. On top of that, there’s just very little in resources to manage the data. There has to be more people managing the data, more people accessing and touching the data, to talk about it and describe it. But there also have to be automated techniques in order to enable people to do that management work faster.”
Whether Alation ultimately solves the data tribalism problem remains to be seen. What isn’t up for debate is the bona fides of the Redwood City company’s co-founders, including Sangani, who worked at Oracle for many years; Aaron Kalb, who helped build Siri at Apple; machine learning expert Feng Niu; and Venky Ganti, who developed artificial intelligence at Microsoft.
Related Items:
What Lies Beneath the Data Lake
The Land of a Thousand Big Data Lakes
Technologies:
Middleware
Leading Solution Providers

















