


September 25, 2014
Hadoop Data Virtualization from Cask Now Open Source

Continuuity, a big data startup that seeks to drive complexity out of Hadoop by virtualizating data and applications, today announced that it’s changing its name to Cask and making its software open source. The company also open sourced a streaming engine now named Tigon, and announced the hiring of former Intel executive as COO.
Former Facebook engineer Jonathan Gray co-founded Continuuity with former Yahoo engineer Nitin Motgi about three years ago to address the challenges they saw enveloping the Hadoop world. While Hadoop technologies like MapReduce and Hive and HBase were providing powerful capabilities to manipulate massive amounts of data, they realized how difficult and time-consuming it was to build the low-level plumbing required to develop applications that traverse these different engines.
“We asked, ‘How do we make all this powerful stuff simple so developers are focused on doing their jobs and creating value, not wasting a bunch of time sitting on command lines writing glue and futzing around with these distributed systems,” Gray, the CEO of Cask, tells Datanami. “For an enterprise, it’s extremely difficult to deal with the influx of all these different technologies and projects. People are actually trying to get stuff done, and it’s very hard for them.”
So they developed a data virtualization product called Continuuity Reactor that does some of the plumbing work for the developer. That product, which is now known as Cask Data Application Platform (CDAP), provides an out-of-the-box way to ensure that data and applications developed with MapReduce can interoperate with data and applications developed in Hive, Hbase, Pig, and other Hadoop engines (support for Spark and Cascading has yet to be released).
 CDAP, which is now freely available under an Apache version 2.0 software license, introduces the twin concepts of data and application virtualization, Gray says. “Data virtualization is about a logical representation of the underlying data,” he says. “Traditionally with Hadoop, anytime I’m using a tool to access data in Hadoop, that tool is accessing Hadoop directly. It’s accessing the files, it’s accessing HBase tables directly, so it’s very difficult for an enterprise to have any kind of operational control.” In addition to slowing development by forcing programmers to become experts with the APIs of each Hadoop engines, it hampers monitoring during production.
CDAP, which is now freely available under an Apache version 2.0 software license, introduces the twin concepts of data and application virtualization, Gray says. “Data virtualization is about a logical representation of the underlying data,” he says. “Traditionally with Hadoop, anytime I’m using a tool to access data in Hadoop, that tool is accessing Hadoop directly. It’s accessing the files, it’s accessing HBase tables directly, so it’s very difficult for an enterprise to have any kind of operational control.” In addition to slowing development by forcing programmers to become experts with the APIs of each Hadoop engines, it hampers monitoring during production.
With CDAP, Cask is attempting to expose a single API to the developer, and allow him to access all the different engines, thereby simplifying data integration tasks. “It adds an abstraction layer on top of the low-level infrastructure that enables you to expose data sets in many different ways, without writing the code and logic to do so,” Gray says. “The ability to do that without actually having to implement it, is a vastly different experience from the way you use Hadoop technologies today.”
CDAP is not the be-all, end-all for data and application integration in Hadoop. The various engines—MapReduce, Tez, Spark, etc.–still need to be integrated at a deep level. That is the necessary and valuable work that Hadoop distributors like Cloudera, Hortonworks, and MapR Technologies are doing in concert with the Apache open source community. But whereas the distros and ASF may ensure that the various engines can play together nicely in Hadoop, they’re not necessarily in the business of simplifying those integration points. It’s still up to the developer to stitch their applications together, and that’s the pain point that Cask hopes to address with CDAP.
While Hadoop has just started to gain traction as a single data lake where you can store all your data, the various engines threaten to re-build the old data-silo problem that is driving many to centralized Hadoop in the first place. “You’re going to have an end-by-end problem where each system needs to communicate with each other system 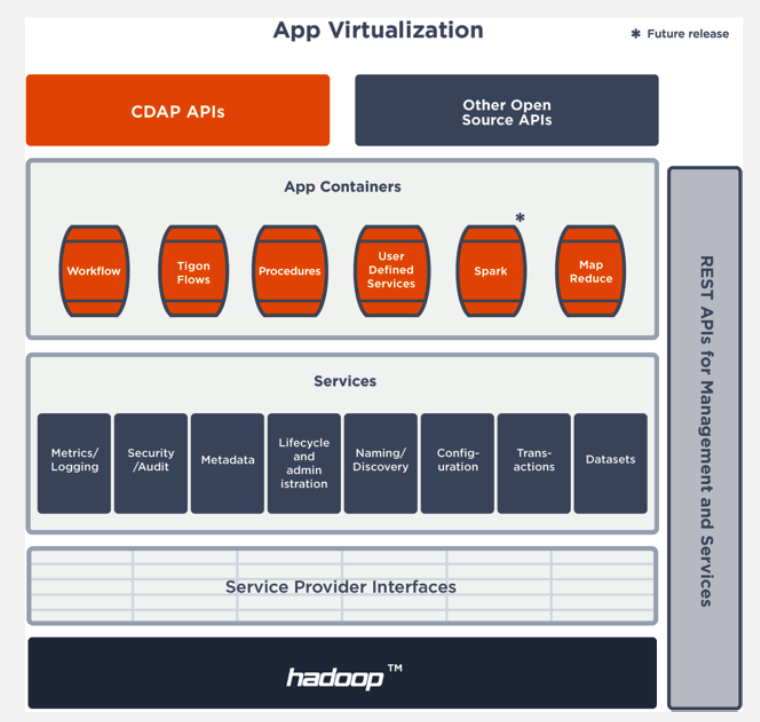 and it just becomes very difficult,” Gray says. “Our belief is there’s a need for a virtualization layer on top of the wide variety of open source products to create some standardization and semblance of consistency so that people can become far more productive.”
and it just becomes very difficult,” Gray says. “Our belief is there’s a need for a virtualization layer on top of the wide variety of open source products to create some standardization and semblance of consistency so that people can become far more productive.”
If you think that Cask, or something like it, ought to be developed by the Apache Hadoop project itself, then Gray may agree with you. “Our goal is to drive a standard,” he says. “Our goal in going open source is to be a community-driven project. Our goal is not to maintain control over this in the long term. We feel there’s a need for this. Just like there have been other standards, like Java application server standards, we think there’s such a thing as the data application platform standard.”
Cask’s approach to Hadoop virtualization has attracted attention from renowned venture capital firm Andreessen Horowitz, which participated in Series A and B rounds totaling $12.5 million. Also backing the data and app virtualization approach is Mike Olson, chief strategy officer at Cloudera, who says that it will “expand the market by enabling new use cases and accelerating application development.”
The company also announced the availability of a developer preview of Tigon, a real-time streaming analytics framework for Hadoop that will compete against Storm, S4, Spark Streaming, Datatorrent, and other streaming frameworks. Tigon which was originally called jetStream (and is now open source, like CDAP), combines Cask’s BigFlow product with a 10-year-old complex event processing (CEP) product from AT&T Labs that was used to process Ma Bell’s massive streams of call records.
Gray expects Tigon to see good uptake among Hadoop developers because of its support for “exactly-once” transaction processing. That capability to guarantee transactional consistency is the result of BigFlow’s reliance on another open source project Cask is involved with, called Tephra, that’s a transactional plug-in for HBase (Gray is an HBase committer with the ASF and used HBase to lead the development of the Messages feature at Facebook before leaving to found Continuuity).

Cask CEO and co-founder Jonathan Gray
“When an application developer is writing the logic of Tigon flows, they don’t really worry about kind of common things you worry about in a distributed system, which are failures and retries,” Gray says. “Because everything is a transaction, you just have an assumption that all your data operations and everything you have in your application are atomic.”
The Palo Alto, California company also announced a new release of Coopr, its Hadoop cluster provisioning and management product that was formerly called Continuuity Loom. Version 0.9.8 adds several new multi-tenancy features that should help IT administrators and DevOps groups control their clusters.
As if a new company name and re-branding, a shift to open source, and two new releases of other products wasn’t enough for one day, Cask also announced that it has hired Boyd Davis to be its new chief operating officer. Davis previously was vice president of the Data Center Group at Intel and general manager of the Datacenter Software Division, which included Intel’s distribution for Hadoop. He’ll be asked to lead the sales and marketing teams at Cask.
If you watch the Hadoop space, keep your eye on Cask, which seems to be in a hurry to get wherever it’s going. “We’ve built a lot of cool stuff in the last three years,” Gray says, “and we’re putting it out there so that we can try and help a lot more people get a lot more value more quickly.”
Related Items:
Intel Exits Hadoop Market, Throws In with Cloudera
Leading Solution Providers
















