


June 18, 2014
Meshing Advanced Analytics with Hadoop

The rapid maturation of Hadoop is evident not only with the progress of open source Apache projects that drive the core stack, but also with the vendor community that build commercial tools. This week, two advanced analytic tool vendors, Alteryx and RapidMiner, revealed new ways they’re helping to drive insight out of data stored in Hadoop.
Alteryx today announced that the next release of its flagship analytic tool, Alteryx Analytics, will feature read-write access into HDFS, which will give users fast and direct access into the broad array of data stored in Hadoop.
The popular analytics tool currently features an out-of-the-box connector for pulling in Hadoop data via SQL queries governed by Impala and Hive. That works well for data that has already been refined to an extent, but it doesn’t allow Alteryx users to get at the treasure trove of semi-structured and unstructured data in Hadoop, including clickstream data, location data, and machine data.
“This gives us the ability to get unstructured data very rapidly,” Paul Ross, vice president of product and industry marketing, tells Datanami. “It’s a much faster way to do it, because customers have direct access to the file system itself…. You don’t have a layer disintermediating the process.”
The new feature will empower data analysts to blend and analyze a variety of data types that organizations are storing in Hadoop and other locations. Users will be able to access Hadoop-resident data, blend it with other data sources, such as transactional data or demographic data from public sources, and then append the file with a write back to HDFS.
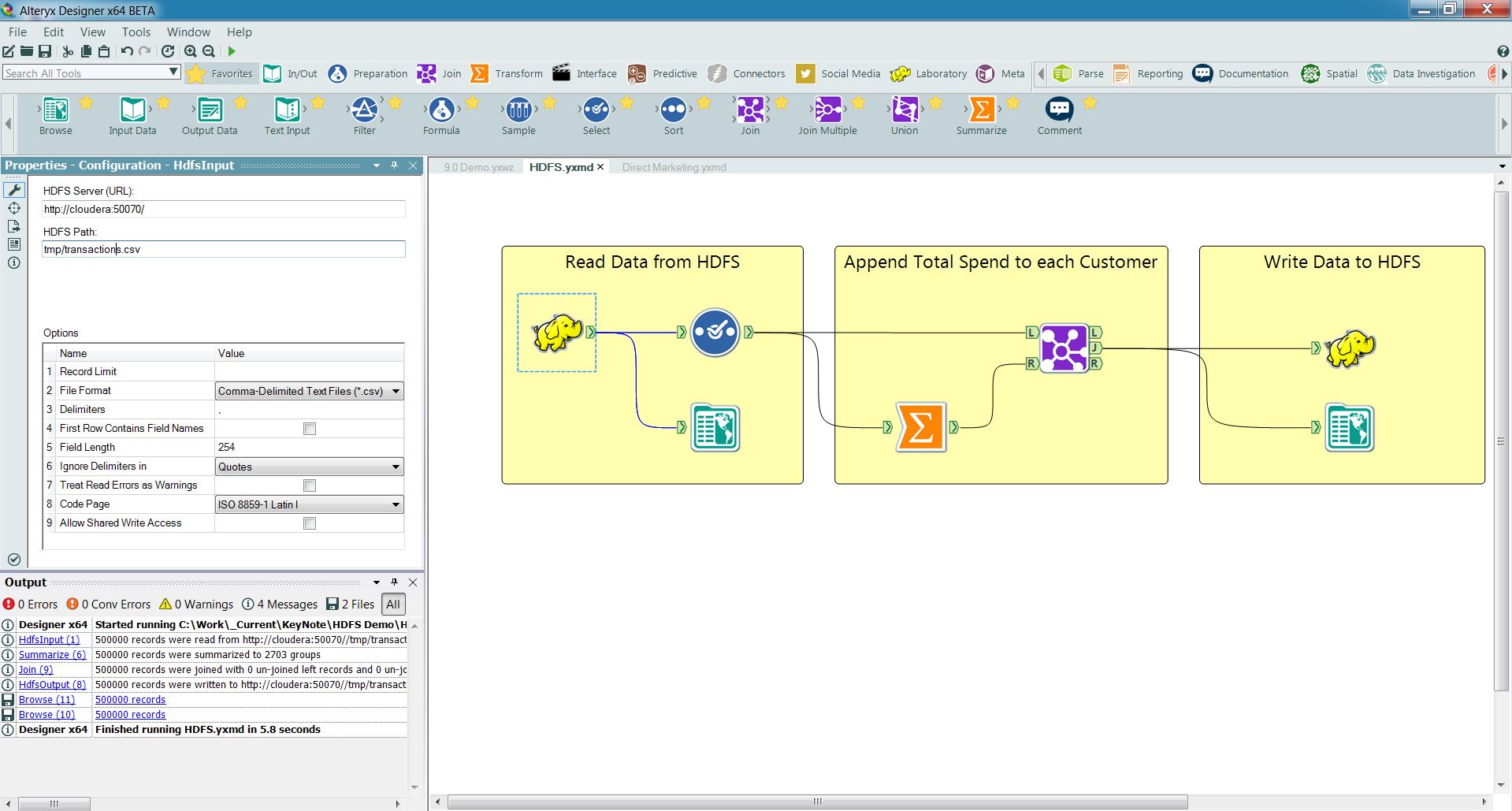
Alteryx customers can now access HDFS data directly via the GUI
That type of advanced analytic workflow was previously the domain of data scientists with Java programming and MapReduce skills. But the words “programming” and “MapReduce” are taboo in the Alteryx world.
“What we see is that Hadoop is becoming very much a tier one data store for organizations, , and that directly impacts the lives of the analysts who come to our shows and use our product everyday,” Ross says. “We want to enable analysts to get access and be able to blend data from Hadoop in the same way they would be with an Oracle database, Excel spreadsheet, flat file, or Salesforce.”
Getting direct access to HDFS is not an extraordinary feat in its own right. What makes Alteryx’s work different is the way it simplifies access to data in HDFS through the product’s drag and drop graphical, Ross says. “So essentially Hadoop, big data, just becomes another core data source for us versus a scary different thing that only a specialist can access,” he says.
Moving up the Hadoop stack will definitely win Alteryx points with customers who are adopting the big yellow elephant. But the company has even bigger plans to integrate with Hadoop, including possibly running as a service within Hadoop, which would eliminate the need to move data between the Hadoop and Alteryx environments. Ross also mentioned Apache Spark as a target of future development efforts.
Alteryx made the announcement today during its annual user conference in San Diego, which attracted about 700 users. The new feature will ship next quarter with an as-yet unidentified new release of Alteryx Analytics.
Another up-and-coming advanced analytic tool vendor who made some big Hadoop news this week is RapidMiner, the German-born software company that recently moved its headquarters to Cambridge, Massachusetts. Its acquisition this week of the Hungarian software company Radoop gives RapidMiner an immediate boost in the world of Hadoop analytics.
 RapidMiner and Radoop already had a close partnership whereby Radoop enabled RapidMiner’s suite of predictive algorithms—including neural network, linear and logistic regressions, K-means, and decision trees—to run on Hadoop. Radoop helps simplify programming in Hadoop by presenting operators as building blocks that users can assemble to perform specific operations, such as ETL, data cleansing, aggregations, and joins.
RapidMiner and Radoop already had a close partnership whereby Radoop enabled RapidMiner’s suite of predictive algorithms—including neural network, linear and logistic regressions, K-means, and decision trees—to run on Hadoop. Radoop helps simplify programming in Hadoop by presenting operators as building blocks that users can assemble to perform specific operations, such as ETL, data cleansing, aggregations, and joins.
RapidMiner co-founder and CEO Ingo Mierswa says the acquisition of Radoop’s technology and technical expertise gives the company a unique edge in the field of big data Hadoop analytics.
“Radoop is a big data analytic technology that lowers the barrier of using Hadoop systems by combining the strength of RapidMiner Miner and Hadoop,” Mierswa says in a video posted to the RapidMiner website. “Radoop enables companies to work with very large data sets within RapidMiner’s graphical user interface, enabling ETL and data analysis on Hadoop clusters. The result is a higher performing and easy to use data transformation and analysis solution.”
Radoop version 2, which was released in April, introduced more than 50 Hadoop operators, including support for YARN, thereby ensuring that the product plays well with others living in the modern Hadoop 2.0 stack. Radoop also sported integrations with MapReduce, Hive, Impala, Mahout and Pig; partnerships with Hadoop distributors Cloudera and Hortonworks; as well as a partnership with NoSQL database vendor DataStax.
While Hadoop isn’t just for data analytics, it’s becoming clear that analytics is its strongest hand. As more data gets stored in Hadoop, users will increasingly look to tools that not only let them analyze it, but to run machine learning and predictive analytic routines against it. With this weeks’ news, RapidMiner and Alteryx appear to be two of the advanced analytic vendors well-positioned to capitalize on this trend.
Related Items:
Radoop: A Predictive Analytic Alternative to R on Hadoop
SAS and IBM King of Analytics Hill, But for How Long?
Technologies:
Middleware
Leading Solution Providers
















