


May 30, 2014
Deep Neural Networks Power Big Gains in Speech Recognition

Ten years ago, Bill Gates declared speech recognition as one of the “holy grails” of computing challenges that would fall within the next decade. Right on cue, Microsoft this week revealed that its research in deep neural networks and machine translation have yielded major advances in the field, the results of which will be included in a new real-time language translation product for Skype expected by December.
Microsoft Research has been working on speech recognition and related topics in the field of natural language processing (NLP) for the better part of two decades. Breakthroughs in the field have been few and far between, as then-chairman and chief software architect Gates admitted during the March 2004 Gartner Symposium held in San Diego. Although small advances have been made, getting computers to understand in an accurate way the words human say–let alone to translate those words and sentences to and from different languages–has proved to be an extremely challenging task. The struggles have also confirmed, in a way, the hidden power of the human brain.
But according to Microsoft, enough progress has been made in computerized speech recognition and the related field of machine translation and synthesized speech that it felt comfortable rolling out a product based on them. The new Skype Translator offering, slated for availability as a Windows 8 beta product by the end of the year, will deliver real-time audio translation between different languages, thereby allowing two users who speak different languages to communicate.
Skype Translator will showcase the advances Microsoft Research has made in these NLP disciplines. “We felt speech translation was a very natural evolution o f the text-translation work we’ve been doing,” Chris Wendt, program manager of the Machine Translation team at Microsoft, said in a Microsoft Research article this week.
f the text-translation work we’ve been doing,” Chris Wendt, program manager of the Machine Translation team at Microsoft, said in a Microsoft Research article this week.
In the speech recognition space, Microsoft has been making steady advances in the accuracy department by using new approaches, specifically using deep neural networks as a multi-level training ground for recognizing audible human speech (as opposed to the written word).
In 2009, Microsoft researcher Li Deng collaborated with University of Toronto professor Geoff Hinton to apply new neural network methods to the speech recognition problem. Deng was interested in using Hinton’s research (published in a 2006 paper) that looked at new ways neural networks can be used for signal modeling and classification.
Using not just neural networks, but “deep” neural networks with many different layers, played a key role. “People in those early days didn’t realize that using many layers was becoming very important. But that’s what many parts of the structure in the brain look like,” Deng says in the Microsoft Research article.
Another modest breakthrough came through the use of “senones,” or small pronunciation fragments, as the training targets for neural networks. Deng and Dong Yu, a fellow researchers on the Redmond, Washington, campus, achieved a 16 percent boost in speech recognition by using senones.
After working with Microsoft speech researcher Frank Seide, they were able to boost the accuracy by 24 percent, then up to 42 percent. Now they were on to something. “I was very excited, mainly because I had been working on this area for a long, long time, and I knew that improvement at that scale had never happened in my career,” Yu says in the Microsoft Research article.
The researchers documented their breakthrough in speech recognition in a 2012 paper titled “Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition,” in the journal IEEE Transactions on Audio, Speech, and Language Processing. Specifically, that paper explains why deep neural networks are better at speech recognition than the conventional context-dependent Gaussian mixture model. That paper won an IEEE award, despite the suddenly crowded field of rese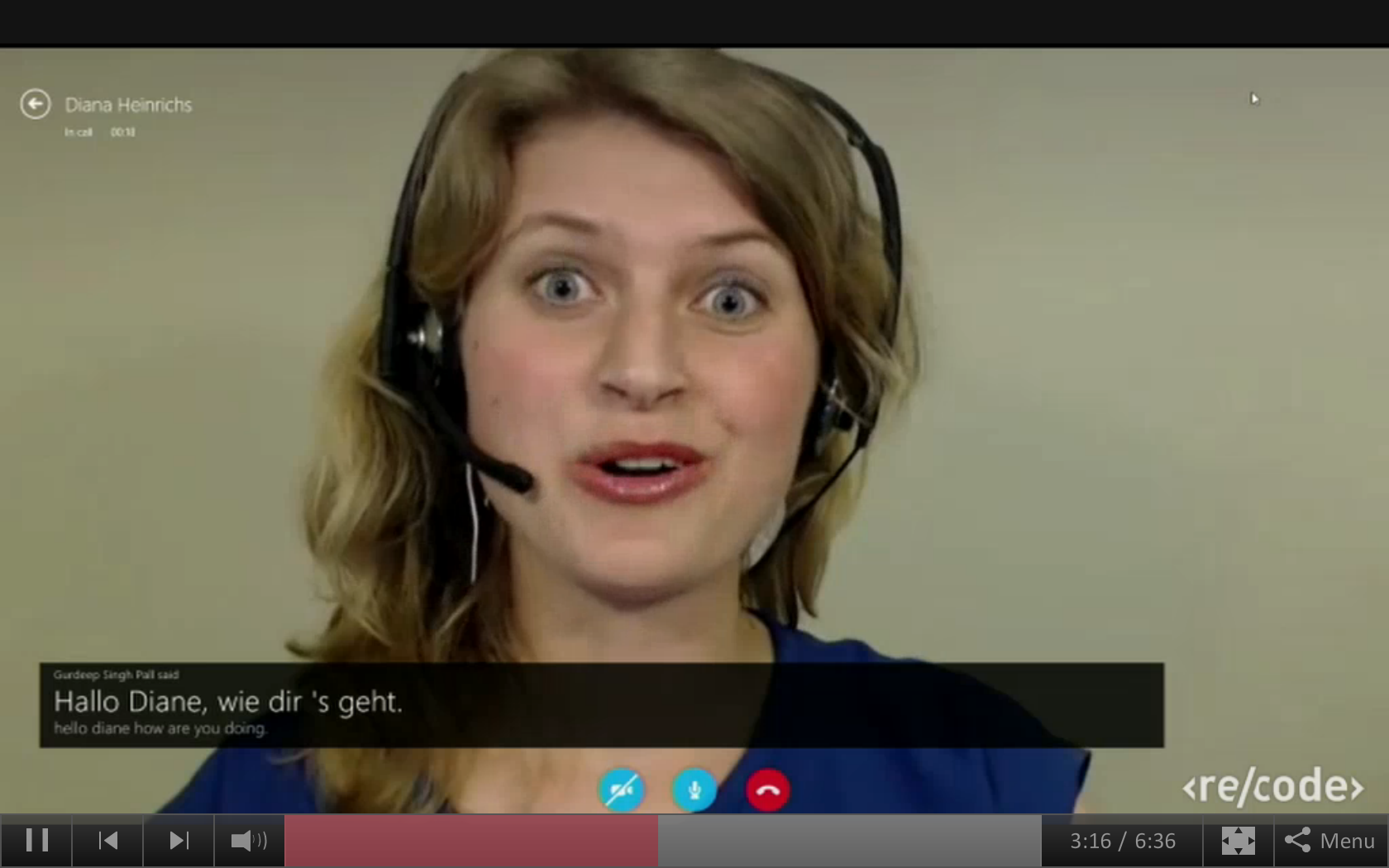 arch into neural networks.
arch into neural networks.
The deep neural network approach can’t yet replicate human understanding of speech, but it’s good enough to spur Microsoft to begin cross-departmental product development projects across the Skype and Bing platform groups that utilize the advances in basic speech recognition. On Tuesday, Microsoft CEO Satya Nadella was onstage with Walt Mossberg and Karen Swisher of Re/code to view a demo of Skype Translator.
The demo showcased the three aspects of Skype Translator, including the speech recognition, language translation, and voice synthesis. Gurdeep Pall, Microsoft’s corporate vice president of Skype, called a female German colleague via Skype and had a conversation using the new language translational feature. Pall asked questions in English, which were repeated in German using a voice synthesizer with a female voice, and also presented as text on the Skype screen. The German colleague’s response was then translated and synthesized into a male English voice on Pall’s side, and also presented as text.
Nadella, who recently took over from former CEO (and prospective NBA team owner) Steve Ballmer, stressed that the demo wasn’t just about showcasing three independent technologies. “It’s not just about daisy chaining these three technologies and

CEO Nadella, Mossberg, and Swisher on stage Tuesday at a Re/Code conference near Los Angeles.
bringing them together. It’s this deep neural net that you build that synthesizes a model to be able to do speech recognition,” he says.
“The one fascinating feature of this is something called transfer learning,” Nadella continues. “What happens is, say you teach it English. It knows English. Then you teach it Mandarin. It learns Mandarin, but it becomes better at English. Then you teach it Spanish and it gets good at Spanish but it gets great at both Mandarin and English. And quite frankly none of us know exactly why. It’s brain-like in the sense of its capability.”
“It’s a little scary, Satya,” Mossberg opined. “It’s magical, I’ll put it,” Nadella responded. “It’ll be magical until they take over the world and kill us,” Swisher finished.
Related Items:
A Prediction Machine Powered by Big Social Data
Saffron Gets $7M to Build Brain-Like Learning Machine
Vendors:
Microsoft
Leading Solution Providers
















